 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRashid: A Cipher-Based Framework for Exploring In-Context Language Learning
Mar 23, 2026Where there is growing interest in in-context language learning (ICLL) for unseen languages with large language models, such languages usually suffer from the lack of NLP tools, data resources, and researcher expertise. This means that progress is difficult to assess, the field does not allow for cheap large-scale experimentation, and findings on ICLL are often limited to very few languages and tasks. In light of such limitations, we introduce a framework (Rashid), for studying ICLL wherein we reversibly cipher high-resource languages (HRLs) to construct truly unseen languages with access to a wide range of resources available for HRLs, unlocking previously impossible exploration of ICLL phenomena. We use our framework to assess current methods in the field with SOTA evaluation tools and manual analysis, explore the utility of potentially expensive resources in improving ICLL, and test ICLL strategies on rich downstream tasks beyond machine translation. These lines of exploration showcase the possibilities enabled by our framework, as well as providing actionable insights regarding current performance and future directions in ICLL.
DialUp! Modeling the Language Continuum by Adapting Models to Dialects and Dialects to Models
Jan 27, 2025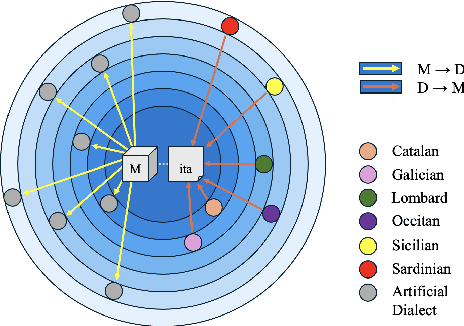



Most of the world's languages and dialects are low-resource, and lack support in mainstream machine translation (MT) models. However, many of them have a closely-related high-resource language (HRL) neighbor, and differ in linguistically regular ways from it. This underscores the importance of model robustness to dialectical variation and cross-lingual generalization to the HRL dialect continuum. We present DialUp, consisting of a training-time technique for adapting a pretrained model to dialectical data (M->D), and an inference-time intervention adapting dialectical data to the model expertise (D->M). M->D induces model robustness to potentially unseen and unknown dialects by exposure to synthetic data exemplifying linguistic mechanisms of dialectical variation, whereas D->M treats dialectical divergence for known target dialects. These methods show considerable performance gains for several dialects from four language families, and modest gains for two other language families. We also conduct feature and error analyses, which show that language varieties with low baseline MT performance are more likely to benefit from these approaches.
Computational Discovery of Chiasmus in Ancient Religious Text
Jan 18, 2025
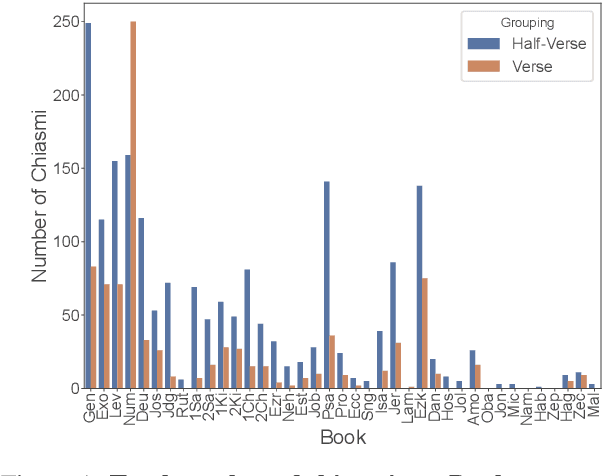
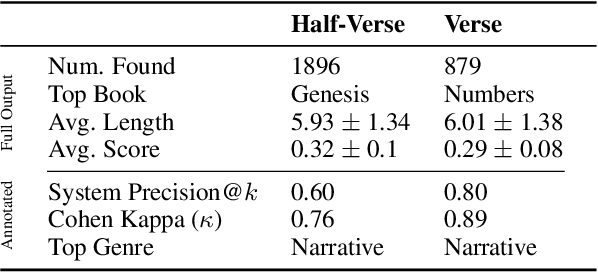

Chiasmus, a debated literary device in Biblical texts, has captivated mystics while sparking ongoing scholarly discussion. In this paper, we introduce the first computational approach to systematically detect chiasmus within Biblical passages. Our method leverages neural embeddings to capture lexical and semantic patterns associated with chiasmus, applied at multiple levels of textual granularity (half-verses, verses). We also involve expert annotators to review a subset of the detected patterns. Despite its computational efficiency, our method achieves robust results, with high inter-annotator agreement and system precision@k of 0.80 at the verse level and 0.60 at the half-verse level. We further provide a qualitative analysis of the distribution of detected chiasmi, along with selected examples that highlight the effectiveness of our approach.
Characterizing the Effects of Translation on Intertextuality using Multilingual Embedding Spaces
Jan 18, 2025

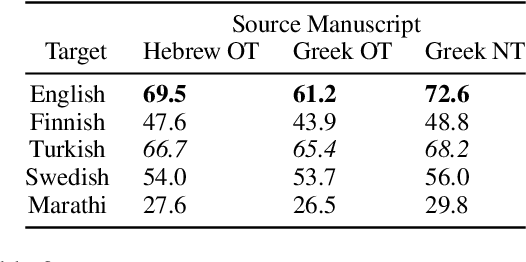
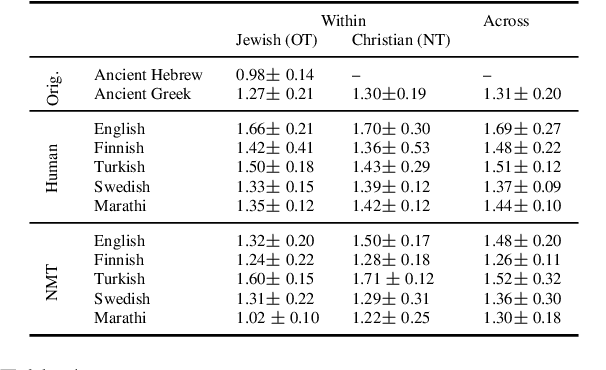
Rhetorical devices are difficult to translate, but they are crucial to the translation of literary documents. We investigate the use of multilingual embedding spaces to characterize the preservation of intertextuality, one common rhetorical device, across human and machine translation. To do so, we use Biblical texts, which are both full of intertextual references and are highly translated works. We provide a metric to characterize intertextuality at the corpus level and provide a quantitative analysis of the preservation of this rhetorical device across extant human translations and machine-generated counterparts. We go on to provide qualitative analysis of cases wherein human translations over- or underemphasize the intertextuality present in the text, whereas machine translations provide a neutral baseline. This provides support for established scholarship proposing that human translators have a propensity to amplify certain literary characteristics of the original manuscripts.
Evaluating Morphological Compositional Generalization in Large Language Models
Oct 16, 2024Large language models (LLMs) have demonstrated significant progress in various natural language generation and understanding tasks. However, their linguistic generalization capabilities remain questionable, raising doubts about whether these models learn language similarly to humans. While humans exhibit compositional generalization and linguistic creativity in language use, the extent to which LLMs replicate these abilities, particularly in morphology, is under-explored. In this work, we systematically investigate the morphological generalization abilities of LLMs through the lens of compositionality. We define morphemes as compositional primitives and design a novel suite of generative and discriminative tasks to assess morphological productivity and systematicity. Focusing on agglutinative languages such as Turkish and Finnish, we evaluate several state-of-the-art instruction-finetuned multilingual models, including GPT-4 and Gemini. Our analysis shows that LLMs struggle with morphological compositional generalization particularly when applied to novel word roots, with performance declining sharply as morphological complexity increases. While models can identify individual morphological combinations better than chance, their performance lacks systematicity, leading to significant accuracy gaps compared to humans.
Dynamic embedded topic models and change-point detection for exploring literary-historical hypotheses
Jan 25, 2024



We present a novel combination of dynamic embedded topic models and change-point detection to explore diachronic change of lexical semantic modality in classical and early Christian Latin. We demonstrate several methods for finding and characterizing patterns in the output, and relating them to traditional scholarship in Comparative Literature and Classics. This simple approach to unsupervised models of semantic change can be applied to any suitable corpus, and we conclude with future directions and refinements aiming to allow noisier, less-curated materials to meet that threshold.
Detecting Structured Language Alternations in Historical Documents by Combining Language Identification with Fourier Analysis
Jan 25, 2024

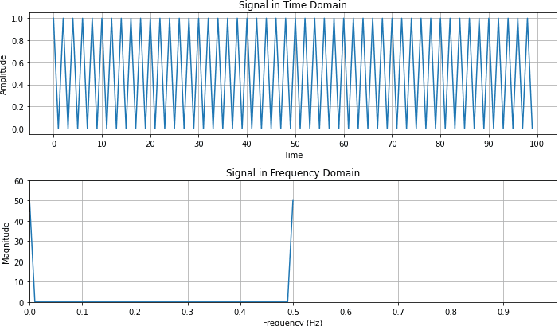
In this study, we present a generalizable workflow to identify documents in a historic language with a nonstandard language and script combination, Armeno-Turkish. We introduce the task of detecting distinct patterns of multilinguality based on the frequency of structured language alternations within a document.