 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Embedded Topic Models: properties and recommendations based on diverse corpora
Apr 27, 2025



We measure the effects of several implementation choices for the Dynamic Embedded Topic Model, as applied to five distinct diachronic corpora, with the goal of isolating important decisions for its use and further development. We identify priorities that will maximize utility in applied scholarship, including the practical scalability of vocabulary size to best exploit the strengths of embedded representations, and more flexible modeling of intervals to accommodate the uneven temporal distributions of historical writing. Of similar importance, we find performance is not significantly or consistently affected by several aspects that otherwise limit the model's application or might consume the resources of a grid search.
Pretraining Language Models for Diachronic Linguistic Change Discovery
Apr 09, 2025



Large language models (LLMs) have shown potential as tools for scientific discovery. This has engendered growing interest in their use in humanistic disciplines, such as historical linguistics and literary studies. These fields often construct arguments on the basis of delineations like genre, or more inflexibly, time period. Although efforts have been made to restrict inference to specific domains via fine-tuning or model editing, we posit that the only true guarantee is domain-restricted pretraining -- typically, a data- and compute-expensive proposition. We show that efficient pretraining techniques can produce useful models over corpora too large for easy manual inspection but too small for "typical" LLM approaches. We employ a novel date-attribution pipeline in order to obtain a temporally-segmented dataset of five 10-million-word slices. We train two corresponding five-model batteries over these corpus segments, efficient pretraining and Llama3-8B parameter efficiently finetuned. We find that the pretrained models are faster to train than the finetuned baselines and that they better respect the historical divisions of our corpus. Emphasizing speed and precision over a-historical comprehensiveness enables a number of novel approaches to hypothesis discovery and testing in our target fields. Taking up diachronic linguistics as a testbed, we show that our method enables the detection of a diverse set of phenomena, including en masse lexical change, non-lexical (grammatical and morphological) change, and word sense introduction/obsolescence. We provide a ready-to-use pipeline that allows extension of our approach to other target fields with only minimal adaptation.
Transferring Extreme Subword Style Using Ngram Model-Based Logit Scaling
Mar 11, 2025



We present an ngram model-based logit scaling technique that effectively transfers extreme subword stylistic variation to large language models at inference time. We demonstrate its efficacy by tracking the perplexity of generated text with respect to the ngram interpolated and original versions of an evaluation model. Minimizing the former measure while the latter approaches the perplexity of a text produced by a target author or character lets us select a sufficient degree of adaptation while retaining fluency.
Computational Discovery of Chiasmus in Ancient Religious Text
Jan 18, 2025
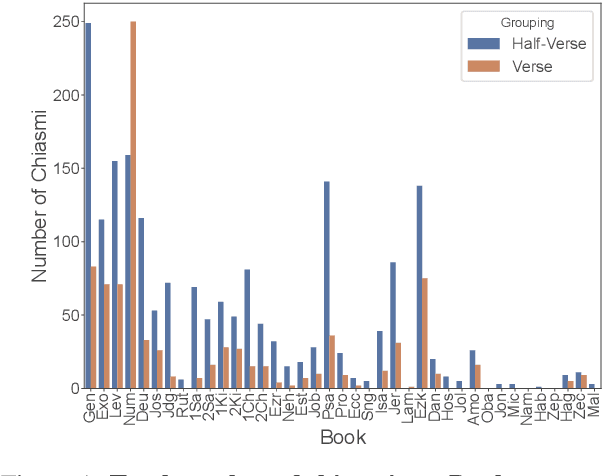
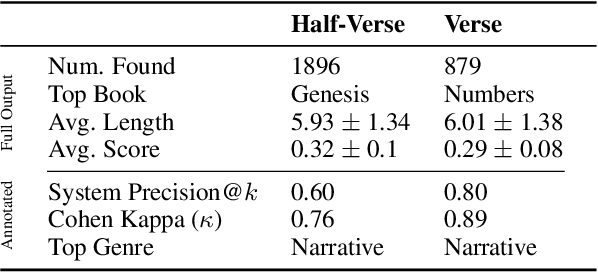

Chiasmus, a debated literary device in Biblical texts, has captivated mystics while sparking ongoing scholarly discussion. In this paper, we introduce the first computational approach to systematically detect chiasmus within Biblical passages. Our method leverages neural embeddings to capture lexical and semantic patterns associated with chiasmus, applied at multiple levels of textual granularity (half-verses, verses). We also involve expert annotators to review a subset of the detected patterns. Despite its computational efficiency, our method achieves robust results, with high inter-annotator agreement and system precision@k of 0.80 at the verse level and 0.60 at the half-verse level. We further provide a qualitative analysis of the distribution of detected chiasmi, along with selected examples that highlight the effectiveness of our approach.
Characterizing the Effects of Translation on Intertextuality using Multilingual Embedding Spaces
Jan 18, 2025

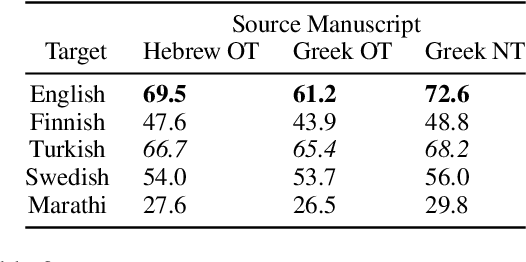
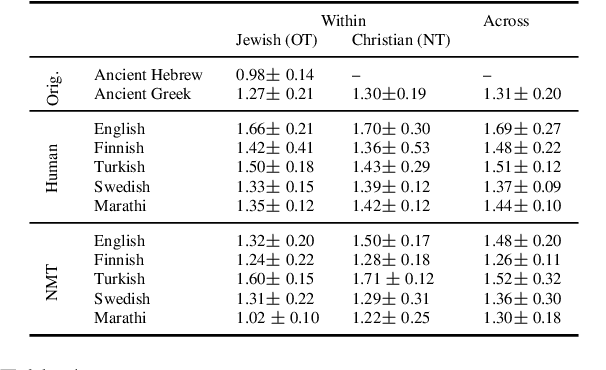
Rhetorical devices are difficult to translate, but they are crucial to the translation of literary documents. We investigate the use of multilingual embedding spaces to characterize the preservation of intertextuality, one common rhetorical device, across human and machine translation. To do so, we use Biblical texts, which are both full of intertextual references and are highly translated works. We provide a metric to characterize intertextuality at the corpus level and provide a quantitative analysis of the preservation of this rhetorical device across extant human translations and machine-generated counterparts. We go on to provide qualitative analysis of cases wherein human translations over- or underemphasize the intertextuality present in the text, whereas machine translations provide a neutral baseline. This provides support for established scholarship proposing that human translators have a propensity to amplify certain literary characteristics of the original manuscripts.
Examining Language Modeling Assumptions Using an Annotated Literary Dialect Corpus
Oct 03, 2024



We present a dataset of 19th century American literary orthovariant tokens with a novel layer of human-annotated dialect group tags designed to serve as the basis for computational experiments exploring literarily meaningful orthographic variation. We perform an initial broad set of experiments over this dataset using both token (BERT) and character (CANINE)-level contextual language models. We find indications that the "dialect effect" produced by intentional orthographic variation employs multiple linguistic channels, and that these channels are able to be surfaced to varied degrees given particular language modelling assumptions. Specifically, we find evidence showing that choice of tokenization scheme meaningfully impact the type of orthographic information a model is able to surface.
Pairing Orthographically Variant Literary Words to Standard Equivalents Using Neural Edit Distance Models
Jan 26, 2024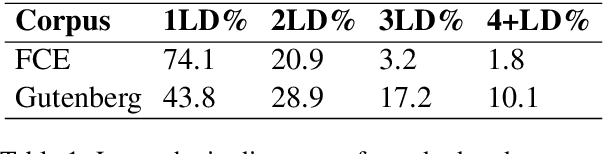
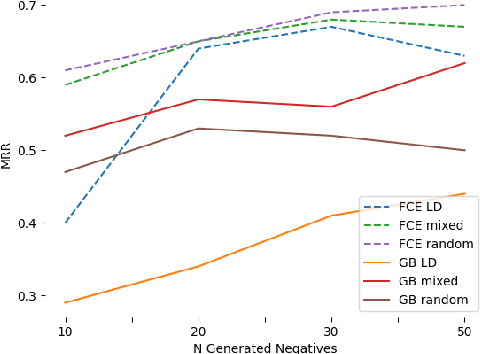
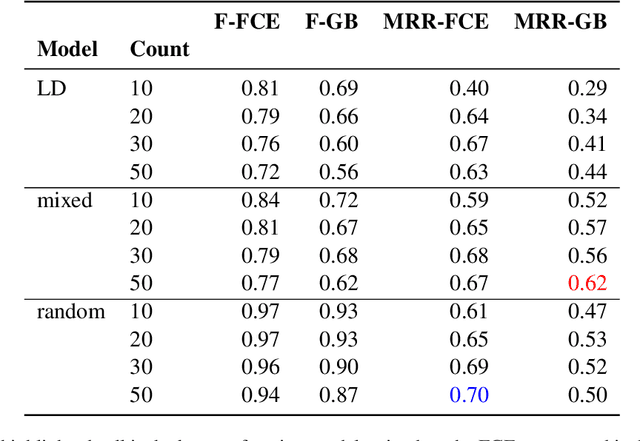
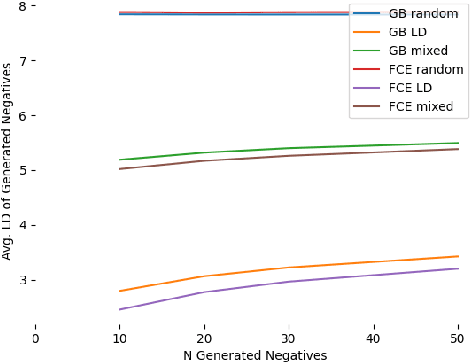
We present a novel corpus consisting of orthographically variant words found in works of 19th century U.S. literature annotated with their corresponding "standard" word pair. We train a set of neural edit distance models to pair these variants with their standard forms, and compare the performance of these models to the performance of a set of neural edit distance models trained on a corpus of orthographic errors made by L2 English learners. Finally, we analyze the relative performance of these models in the light of different negative training sample generation strategies, and offer concluding remarks on the unique challenge literary orthographic variation poses to string pairing methodologies.
Dynamic embedded topic models and change-point detection for exploring literary-historical hypotheses
Jan 25, 2024



We present a novel combination of dynamic embedded topic models and change-point detection to explore diachronic change of lexical semantic modality in classical and early Christian Latin. We demonstrate several methods for finding and characterizing patterns in the output, and relating them to traditional scholarship in Comparative Literature and Classics. This simple approach to unsupervised models of semantic change can be applied to any suitable corpus, and we conclude with future directions and refinements aiming to allow noisier, less-curated materials to meet that threshold.
Detecting Structured Language Alternations in Historical Documents by Combining Language Identification with Fourier Analysis
Jan 25, 2024

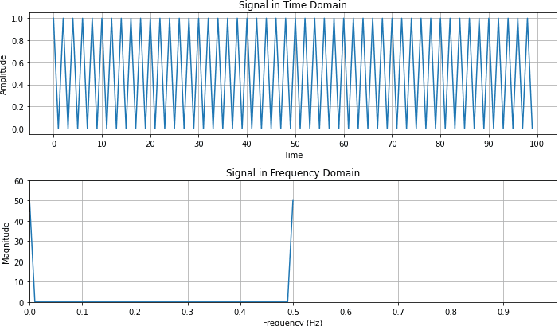
In this study, we present a generalizable workflow to identify documents in a historic language with a nonstandard language and script combination, Armeno-Turkish. We introduce the task of detecting distinct patterns of multilinguality based on the frequency of structured language alternations within a document.
Graph-Convolutional Autoencoder Ensembles for the Humanities, Illustrated with a Study of the American Slave Trade
Jan 01, 2024We introduce a graph-aware autoencoder ensemble framework, with associated formalisms and tooling, designed to facilitate deep learning for scholarship in the humanities. By composing sub-architectures to produce a model isomorphic to a humanistic domain we maintain interpretability while providing function signatures for each sub-architectural choice, allowing both traditional and computational researchers to collaborate without disrupting established practices. We illustrate a practical application of our approach to a historical study of the American post-Atlantic slave trade, and make several specific technical contributions: a novel hybrid graph-convolutional autoencoder mechanism, batching policies for common graph topologies, and masking techniques for particular use-cases. The effectiveness of the framework for broadening participation of diverse domains is demonstrated by a growing suite of two dozen studies, both collaborations with humanists and established tasks from machine learning literature, spanning a variety of fields and data modalities. We make performance comparisons of several different architectural choices and conclude with an ambitious list of imminent next steps for this research.