 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Language Models for Diachronic Linguistic Change Discovery
Apr 09, 2025



Large language models (LLMs) have shown potential as tools for scientific discovery. This has engendered growing interest in their use in humanistic disciplines, such as historical linguistics and literary studies. These fields often construct arguments on the basis of delineations like genre, or more inflexibly, time period. Although efforts have been made to restrict inference to specific domains via fine-tuning or model editing, we posit that the only true guarantee is domain-restricted pretraining -- typically, a data- and compute-expensive proposition. We show that efficient pretraining techniques can produce useful models over corpora too large for easy manual inspection but too small for "typical" LLM approaches. We employ a novel date-attribution pipeline in order to obtain a temporally-segmented dataset of five 10-million-word slices. We train two corresponding five-model batteries over these corpus segments, efficient pretraining and Llama3-8B parameter efficiently finetuned. We find that the pretrained models are faster to train than the finetuned baselines and that they better respect the historical divisions of our corpus. Emphasizing speed and precision over a-historical comprehensiveness enables a number of novel approaches to hypothesis discovery and testing in our target fields. Taking up diachronic linguistics as a testbed, we show that our method enables the detection of a diverse set of phenomena, including en masse lexical change, non-lexical (grammatical and morphological) change, and word sense introduction/obsolescence. We provide a ready-to-use pipeline that allows extension of our approach to other target fields with only minimal adaptation.
Transferring Extreme Subword Style Using Ngram Model-Based Logit Scaling
Mar 11, 2025



We present an ngram model-based logit scaling technique that effectively transfers extreme subword stylistic variation to large language models at inference time. We demonstrate its efficacy by tracking the perplexity of generated text with respect to the ngram interpolated and original versions of an evaluation model. Minimizing the former measure while the latter approaches the perplexity of a text produced by a target author or character lets us select a sufficient degree of adaptation while retaining fluency.
Examining Language Modeling Assumptions Using an Annotated Literary Dialect Corpus
Oct 03, 2024



We present a dataset of 19th century American literary orthovariant tokens with a novel layer of human-annotated dialect group tags designed to serve as the basis for computational experiments exploring literarily meaningful orthographic variation. We perform an initial broad set of experiments over this dataset using both token (BERT) and character (CANINE)-level contextual language models. We find indications that the "dialect effect" produced by intentional orthographic variation employs multiple linguistic channels, and that these channels are able to be surfaced to varied degrees given particular language modelling assumptions. Specifically, we find evidence showing that choice of tokenization scheme meaningfully impact the type of orthographic information a model is able to surface.
Pairing Orthographically Variant Literary Words to Standard Equivalents Using Neural Edit Distance Models
Jan 26, 2024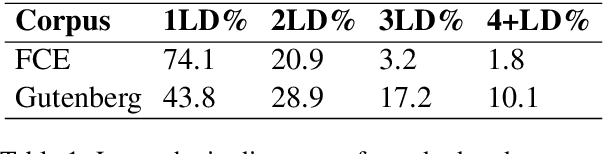
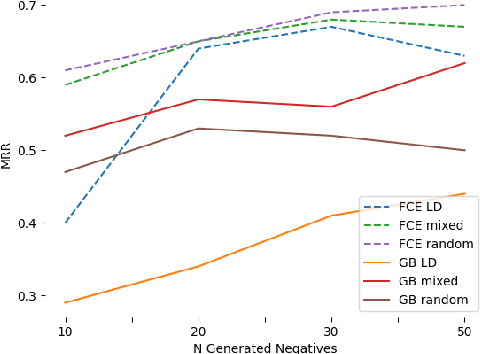
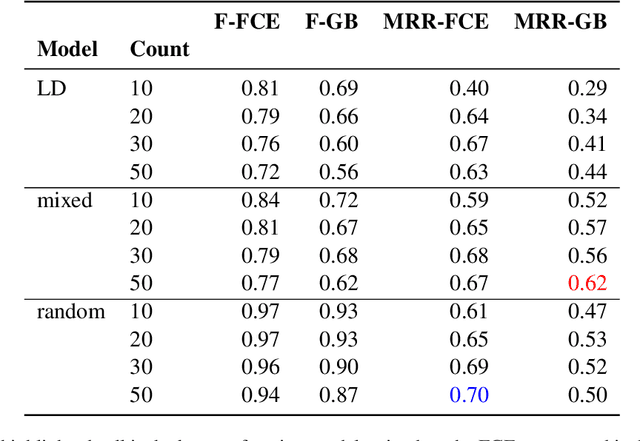
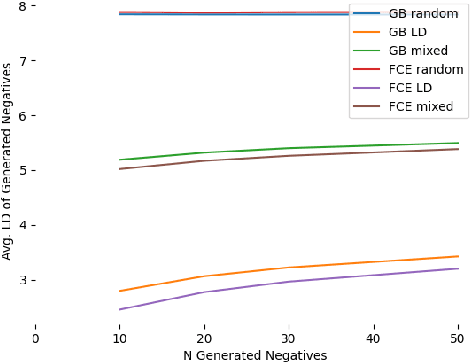
We present a novel corpus consisting of orthographically variant words found in works of 19th century U.S. literature annotated with their corresponding "standard" word pair. We train a set of neural edit distance models to pair these variants with their standard forms, and compare the performance of these models to the performance of a set of neural edit distance models trained on a corpus of orthographic errors made by L2 English learners. Finally, we analyze the relative performance of these models in the light of different negative training sample generation strategies, and offer concluding remarks on the unique challenge literary orthographic variation poses to string pairing methodologies.