Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairing Orthographically Variant Literary Words to Standard Equivalents Using Neural Edit Distance Models
Paper and Code
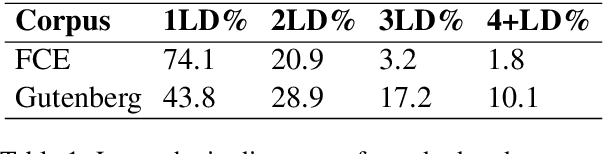
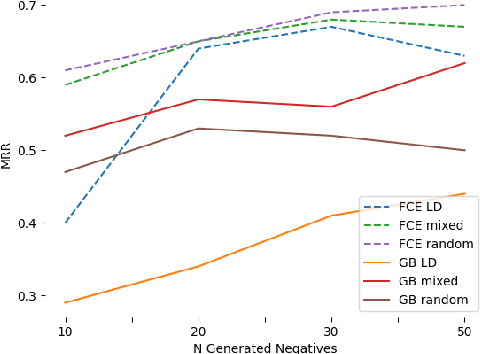
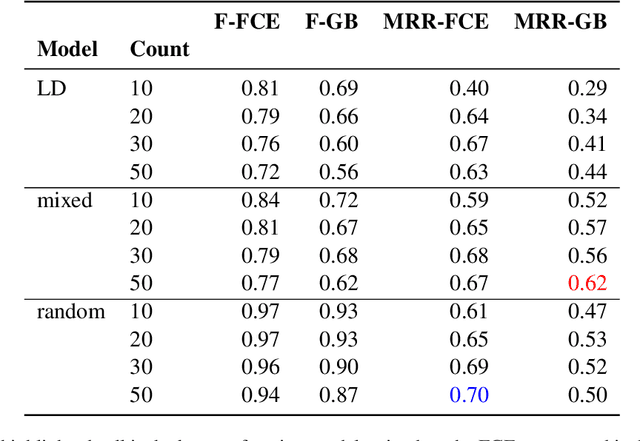
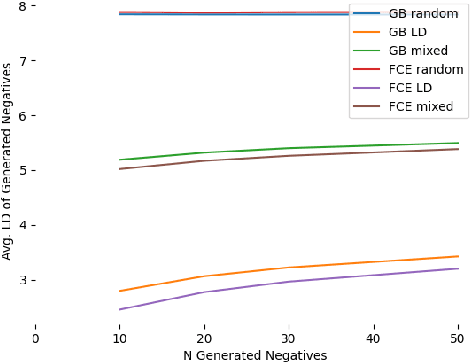
We present a novel corpus consisting of orthographically variant words found in works of 19th century U.S. literature annotated with their corresponding "standard" word pair. We train a set of neural edit distance models to pair these variants with their standard forms, and compare the performance of these models to the performance of a set of neural edit distance models trained on a corpus of orthographic errors made by L2 English learners. Finally, we analyze the relative performance of these models in the light of different negative training sample generation strategies, and offer concluding remarks on the unique challenge literary orthographic variation poses to string pairing methodologies.
* Accepted to LaTeCH@EACL2024
View paper on