 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Reasoning Cascades Need More Context
Jun 25, 2026Translation cascades for reasoning translate the query from another language to English, reason in English, and translate the answer back to the original language. This is a competitive approach to multilingual reasoning, but structurally lossy, since each stage discards information later stages may need, including cues for cultural grounding, register, and disambiguation. We examine the benefits of a simple and training-free intervention: a context-aware translation cascade, which additionally provides the original question, the English translated question, and the reasoning trace to the context of the final translation module. We evaluate gains across nine multilingual benchmarks including various task types, three backbone models, and 285 high-, mid-, and low-resource languages, and demonstrate strong gains for open-ended generation across models and resource regimes. We show that the original language question carries most of the beneficial context. Our study emphasizes the need to better design information flow in machine translation cascades for mitigating error propagation, and provides a simple and actionable default strategy: preserve the original user question until the end of the pipeline.
Rashid: A Cipher-Based Framework for Exploring In-Context Language Learning
Mar 23, 2026Where there is growing interest in in-context language learning (ICLL) for unseen languages with large language models, such languages usually suffer from the lack of NLP tools, data resources, and researcher expertise. This means that progress is difficult to assess, the field does not allow for cheap large-scale experimentation, and findings on ICLL are often limited to very few languages and tasks. In light of such limitations, we introduce a framework (Rashid), for studying ICLL wherein we reversibly cipher high-resource languages (HRLs) to construct truly unseen languages with access to a wide range of resources available for HRLs, unlocking previously impossible exploration of ICLL phenomena. We use our framework to assess current methods in the field with SOTA evaluation tools and manual analysis, explore the utility of potentially expensive resources in improving ICLL, and test ICLL strategies on rich downstream tasks beyond machine translation. These lines of exploration showcase the possibilities enabled by our framework, as well as providing actionable insights regarding current performance and future directions in ICLL.
Omnilingual MT: Machine Translation for 1,600 Languages
Mar 17, 2026High-quality machine translation (MT) can scale to hundreds of languages, setting a high bar for multilingual systems. However, compared to the world's 7,000 languages, current systems still offer only limited coverage: about 200 languages on the target side, and maybe a few hundreds more on the source side, supported due to cross-lingual transfer. And even these numbers have been hard to evaluate due to the lack of reliable benchmarks and metrics. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext. We explore two ways of specializing a Large Language model (LLM) for machine translation: as a decoder-only model (OMT-LLaMA) or as a module in an encoder-decoder architecture (OMT-NLLB). Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to-1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; OMT-LLaMA models substantially expand the set of languages for which coherent generation is feasible. Additionally, OMT models improve in cross-lingual transfer, being close to solving the "understanding" part of the puzzle in MT for the 1,600 evaluated. Our leaderboard and main human-created evaluation datasets (BOUQuET and Met-BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
DialUp! Modeling the Language Continuum by Adapting Models to Dialects and Dialects to Models
Jan 27, 2025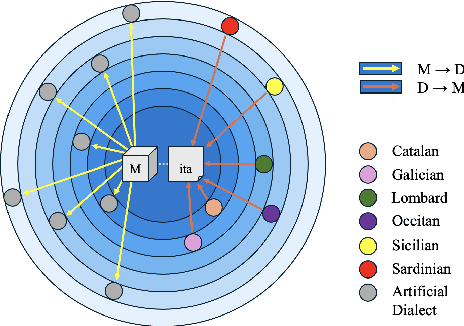



Most of the world's languages and dialects are low-resource, and lack support in mainstream machine translation (MT) models. However, many of them have a closely-related high-resource language (HRL) neighbor, and differ in linguistically regular ways from it. This underscores the importance of model robustness to dialectical variation and cross-lingual generalization to the HRL dialect continuum. We present DialUp, consisting of a training-time technique for adapting a pretrained model to dialectical data (M->D), and an inference-time intervention adapting dialectical data to the model expertise (D->M). M->D induces model robustness to potentially unseen and unknown dialects by exposure to synthetic data exemplifying linguistic mechanisms of dialectical variation, whereas D->M treats dialectical divergence for known target dialects. These methods show considerable performance gains for several dialects from four language families, and modest gains for two other language families. We also conduct feature and error analyses, which show that language varieties with low baseline MT performance are more likely to benefit from these approaches.
Evaluating Large Language Models along Dimensions of Language Variation: A Systematik Invesdigatiom uv Cross-lingual Generalization
Jun 19, 2024

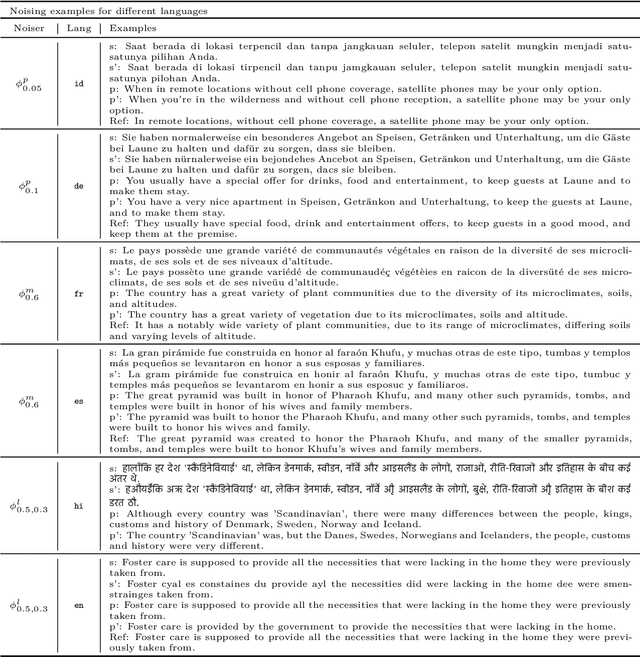
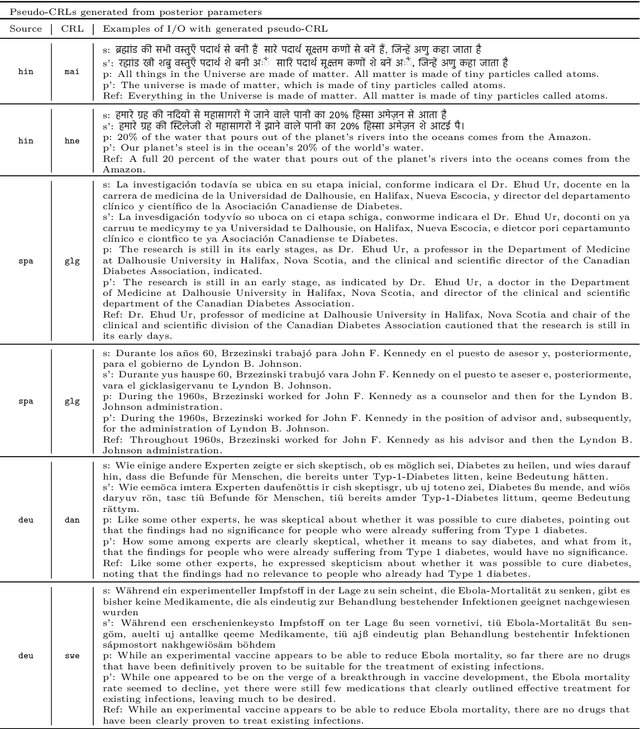
While large language models exhibit certain cross-lingual generalization capabilities, they suffer from performance degradation (PD) on unseen closely-related languages (CRLs) and dialects relative to their high-resource language neighbour (HRLN). However, we currently lack a fundamental understanding of what kinds of linguistic distances contribute to PD, and to what extent. Furthermore, studies of cross-lingual generalization are confounded by unknown quantities of CRL language traces in the training data, and by the frequent lack of availability of evaluation data in lower-resource related languages and dialects. To address these issues, we model phonological, morphological, and lexical distance as Bayesian noise processes to synthesize artificial languages that are controllably distant from the HRLN. We analyse PD as a function of underlying noise parameters, offering insights on model robustness to isolated and composed linguistic phenomena, and the impact of task and HRL characteristics on PD. We calculate parameter posteriors on real CRL-HRLN pair data and show that they follow computed trends of artificial languages, demonstrating the viability of our noisers. Our framework offers a cheap solution to estimating task performance on an unseen CRL given HRLN performance using its posteriors, as well as for diagnosing observed PD on a CRL in terms of its linguistic distances from its HRLN, and opens doors to principled methods of mitigating performance degradation.
Pointer-Generator Networks for Low-Resource Machine Translation: Don't Copy That!
Mar 25, 2024

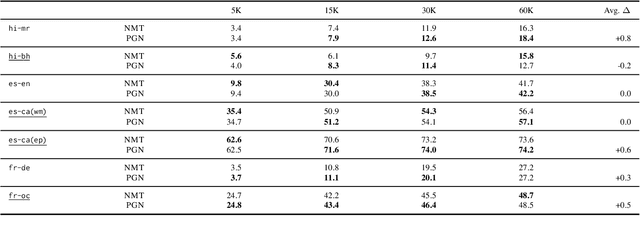
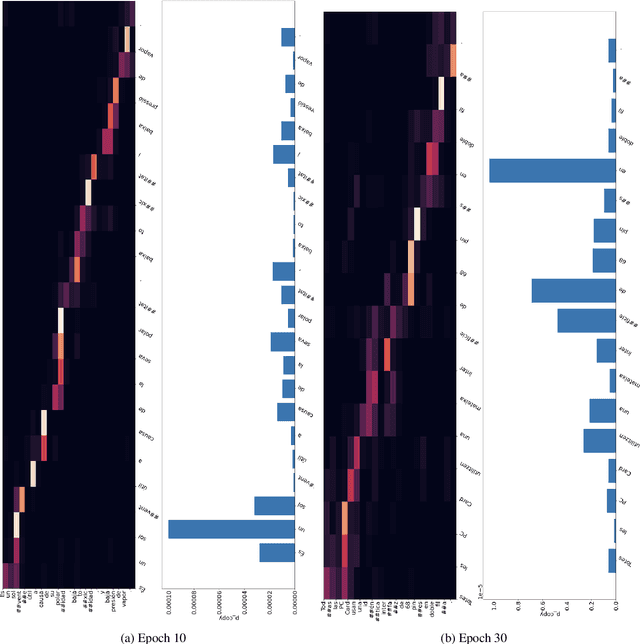
While Transformer-based neural machine translation (NMT) is very effective in high-resource settings, many languages lack the necessary large parallel corpora to benefit from it. In the context of low-resource (LR) MT between two closely-related languages, a natural intuition is to seek benefits from structural "shortcuts", such as copying subwords from the source to the target, given that such language pairs often share a considerable number of identical words, cognates, and borrowings. We test Pointer-Generator Networks for this purpose for six language pairs over a variety of resource ranges, and find weak improvements for most settings. However, analysis shows that the model does not show greater improvements for closely-related vs. more distant language pairs, or for lower resource ranges, and that the models do not exhibit the expected usage of the mechanism for shared subwords. Our discussion of the reasons for this behaviour highlights several general challenges for LR NMT, such as modern tokenization strategies, noisy real-world conditions, and linguistic complexities. We call for better scrutiny of linguistically motivated improvements to NMT given the blackbox nature of Transformer models, as well as for a focus on the above problems in the field.
A Simple Method for Unsupervised Bilingual Lexicon Induction for Data-Imbalanced, Closely Related Language Pairs
May 23, 2023
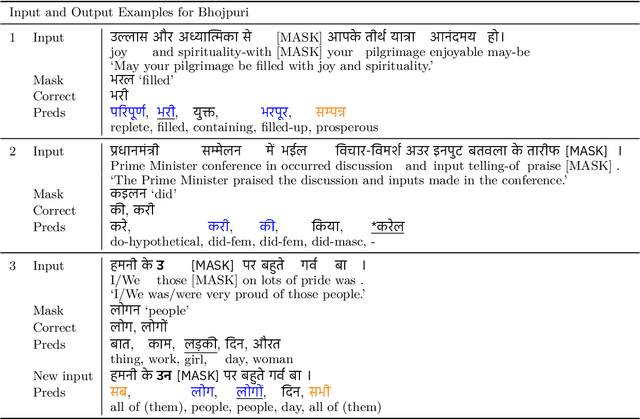
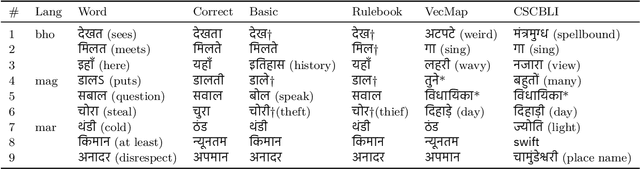

Existing approaches for unsupervised bilingual lexicon induction (BLI) often depend on good quality static or contextual embeddings trained on large monolingual corpora for both languages. In reality, however, unsupervised BLI is most likely to be useful for dialects and languages that do not have abundant amounts of monolingual data. We introduce a simple and fast method for unsupervised BLI for low-resource languages with a related mid-to-high resource language, only requiring inference on the higher-resource language monolingual BERT. We work with two low-resource languages ($<5M$ monolingual tokens), Bhojpuri and Magahi, of the severely under-researched Indic dialect continuum, showing that state-of-the-art methods in the literature show near-zero performance in these settings, and that our simpler method gives much better results. We repeat our experiments on Marathi and Nepali, two higher-resource Indic languages, to compare approach performances by resource range. We release automatically created bilingual lexicons for the first time for five languages of the Indic dialect continuum.