 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiMATE: A Hierarchical Multi-Agent Framework for Machine Translation Evaluation
May 22, 2025



The advancement of Large Language Models (LLMs) enables flexible and interpretable automatic evaluations. In the field of machine translation evaluation, utilizing LLMs with translation error annotations based on Multidimensional Quality Metrics (MQM) yields more human-aligned judgments. However, current LLM-based evaluation methods still face challenges in accurately identifying error spans and assessing their severity. In this paper, we propose HiMATE, a Hierarchical Multi-Agent Framework for Machine Translation Evaluation. We argue that existing approaches inadequately exploit the fine-grained structural and semantic information within the MQM hierarchy. To address this, we develop a hierarchical multi-agent system grounded in the MQM error typology, enabling granular evaluation of subtype errors. Two key strategies are incorporated to further mitigate systemic hallucinations within the framework: the utilization of the model's self-reflection capability and the facilitation of agent discussion involving asymmetric information. Empirically, HiMATE outperforms competitive baselines across different datasets in conducting human-aligned evaluations. Further analyses underscore its significant advantage in error span detection and severity assessment, achieving an average F1-score improvement of 89% over the best-performing baseline. We make our code and data publicly available at https://anonymous.4open.science/r/HiMATE-Anony.
Token-level Ensembling of Models with Different Vocabularies
Feb 28, 2025Model ensembling is a technique to combine the predicted distributions of two or more models, often leading to improved robustness and performance. For ensembling in text generation, the next token's probability distribution is derived from a weighted sum of the distributions of each individual model. This requires the underlying models to share the same subword vocabulary, limiting the applicability of ensembling, since many open-sourced models have distinct vocabularies. In research settings, experimentation or upgrades to vocabularies may introduce multiple vocabulary sizes. This paper proposes an inference-time only algorithm that allows for ensembling models with different vocabularies, without the need to learn additional parameters or alter the underlying models. Instead, the algorithm ensures that tokens generated by the ensembled models \textit{agree} in their surface form. We apply this technique to combinations of traditional encoder-decoder models and decoder-only LLMs and evaluate on machine translation. In addition to expanding to model pairs that were previously incapable of token-level ensembling, our algorithm frequently improves translation performance over either model individually.
Findings of the WMT 2024 Shared Task on Discourse-Level Literary Translation
Dec 16, 2024Following last year, we have continued to host the WMT translation shared task this year, the second edition of the Discourse-Level Literary Translation. We focus on three language directions: Chinese-English, Chinese-German, and Chinese-Russian, with the latter two ones newly added. This year, we totally received 10 submissions from 5 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. We release data, system outputs, and leaderboard at https://www2.statmt.org/wmt24/literary-translation-task.html.
X-ALMA: Plug & Play Modules and Adaptive Rejection for Quality Translation at Scale
Oct 04, 2024



Large language models (LLMs) have achieved remarkable success across various NLP tasks, yet their focus has predominantly been on English due to English-centric pre-training and limited multilingual data. While some multilingual LLMs claim to support for hundreds of languages, models often fail to provide high-quality response for mid- and low-resource languages, leading to imbalanced performance heavily skewed in favor of high-resource languages like English and Chinese. In this paper, we prioritize quality over scaling number of languages, with a focus on multilingual machine translation task, and introduce X-ALMA, a model designed with a commitment to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels. X-ALMA surpasses state-of-the-art open-source multilingual LLMs, such as Aya-101 and Aya-23, in every single translation direction on the FLORES and WMT'23 test datasets according to COMET-22. This is achieved by plug-and-play language-specific module architecture to prevent language conflicts during training and a carefully designed training regimen with novel optimization methods to maximize the translation performance. At the final stage of training regimen, our proposed Adaptive Rejection Preference Optimization (ARPO) surpasses existing preference optimization methods in translation tasks.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Every Language Counts: Learn and Unlearn in Multilingual LLMs
Jun 19, 2024



This paper investigates the propagation of harmful information in multilingual large language models (LLMs) and evaluates the efficacy of various unlearning methods. We demonstrate that fake information, regardless of the language it is in, once introduced into these models through training data, can spread across different languages, compromising the integrity and reliability of the generated content. Our findings reveal that standard unlearning techniques, which typically focus on English data, are insufficient in mitigating the spread of harmful content in multilingual contexts and could inadvertently reinforce harmful content across languages. We show that only by addressing harmful responses in both English and the original language of the harmful data can we effectively eliminate generations for all languages. This underscores the critical need for comprehensive unlearning strategies that consider the multilingual nature of modern LLMs to enhance their safety and reliability across diverse linguistic landscapes.
Recovering document annotations for sentence-level bitext
Jun 06, 2024

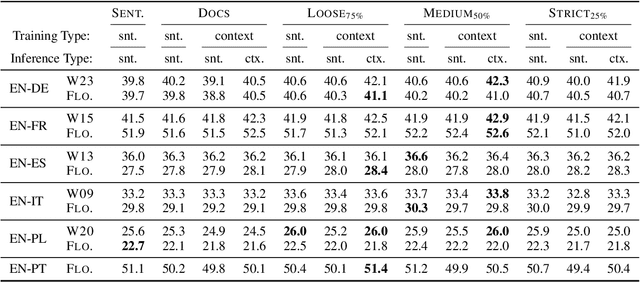

Data availability limits the scope of any given task. In machine translation, historical models were incapable of handling longer contexts, so the lack of document-level datasets was less noticeable. Now, despite the emergence of long-sequence methods, we remain within a sentence-level paradigm and without data to adequately approach context-aware machine translation. Most large-scale datasets have been processed through a pipeline that discards document-level metadata. In this work, we reconstruct document-level information for three (ParaCrawl, News Commentary, and Europarl) large datasets in German, French, Spanish, Italian, Polish, and Portuguese (paired with English). We then introduce a document-level filtering technique as an alternative to traditional bitext filtering. We present this filtering with analysis to show that this method prefers context-consistent translations rather than those that may have been sentence-level machine translated. Last we train models on these longer contexts and demonstrate improvement in document-level translation without degradation of sentence-level translation. We release our dataset, ParaDocs, and resulting models as a resource to the community.
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
DiffNorm: Self-Supervised Normalization for Non-autoregressive Speech-to-speech Translation
May 22, 2024



Non-autoregressive Transformers (NATs) are recently applied in direct speech-to-speech translation systems, which convert speech across different languages without intermediate text data. Although NATs generate high-quality outputs and offer faster inference than autoregressive models, they tend to produce incoherent and repetitive results due to complex data distribution (e.g., acoustic and linguistic variations in speech). In this work, we introduce DiffNorm, a diffusion-based normalization strategy that simplifies data distributions for training NAT models. After training with a self-supervised noise estimation objective, DiffNorm constructs normalized target data by denoising synthetically corrupted speech features. Additionally, we propose to regularize NATs with classifier-free guidance, improving model robustness and translation quality by randomly dropping out source information during training. Our strategies result in a notable improvement of about +7 ASR-BLEU for English-Spanish (En-Es) and +2 ASR-BLEU for English-French (En-Fr) translations on the CVSS benchmark, while attaining over 14x speedup for En-Es and 5x speedup for En-Fr translations compared to autoregressive baselines.
Pointer-Generator Networks for Low-Resource Machine Translation: Don't Copy That!
Mar 25, 2024

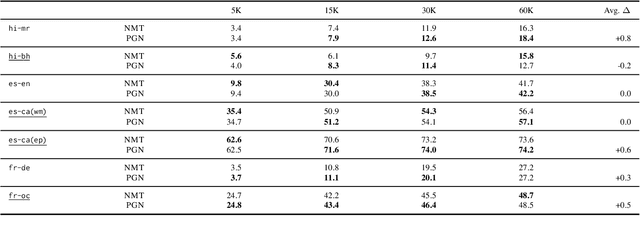
While Transformer-based neural machine translation (NMT) is very effective in high-resource settings, many languages lack the necessary large parallel corpora to benefit from it. In the context of low-resource (LR) MT between two closely-related languages, a natural intuition is to seek benefits from structural "shortcuts", such as copying subwords from the source to the target, given that such language pairs often share a considerable number of identical words, cognates, and borrowings. We test Pointer-Generator Networks for this purpose for six language pairs over a variety of resource ranges, and find weak improvements for most settings. However, analysis shows that the model does not show greater improvements for closely-related vs. more distant language pairs, or for lower resource ranges, and that the models do not exhibit the expected usage of the mechanism for shared subwords. Our discussion of the reasons for this behaviour highlights several general challenges for LR NMT, such as modern tokenization strategies, noisy real-world conditions, and linguistic complexities. We call for better scrutiny of linguistically motivated improvements to NMT given the blackbox nature of Transformer models, as well as for a focus on the above problems in the field.