 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Unveiling Multilinguality in Transformer Models: Exploring Language Specificity in Feed-Forward Networks
Oct 24, 2023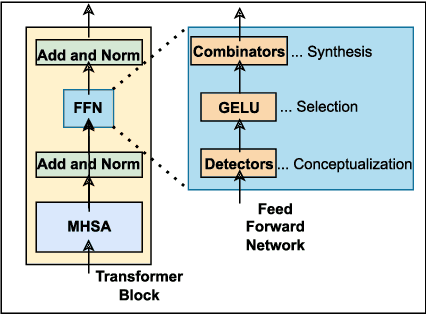
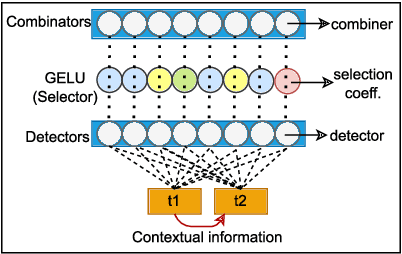
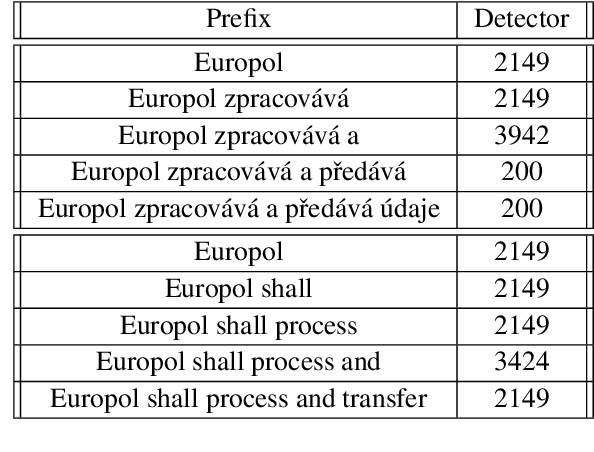
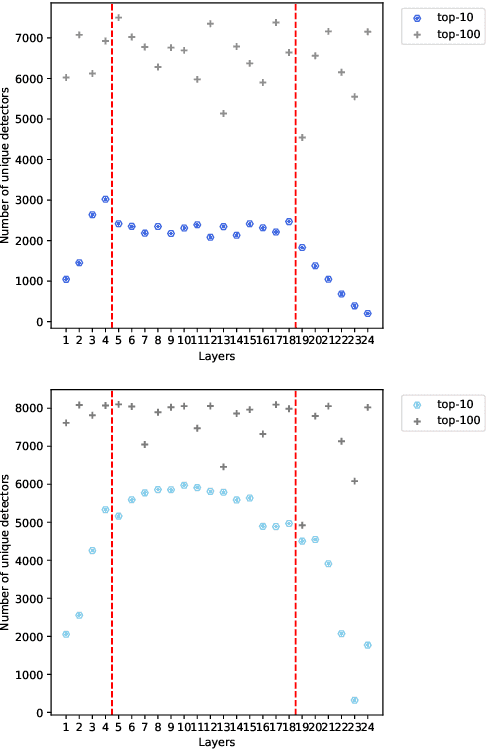
Recent research suggests that the feed-forward module within Transformers can be viewed as a collection of key-value memories, where the keys learn to capture specific patterns from the input based on the training examples. The values then combine the output from the 'memories' of the keys to generate predictions about the next token. This leads to an incremental process of prediction that gradually converges towards the final token choice near the output layers. This interesting perspective raises questions about how multilingual models might leverage this mechanism. Specifically, for autoregressive models trained on two or more languages, do all neurons (across layers) respond equally to all languages? No! Our hypothesis centers around the notion that during pretraining, certain model parameters learn strong language-specific features, while others learn more language-agnostic (shared across languages) features. To validate this, we conduct experiments utilizing parallel corpora of two languages that the model was initially pretrained on. Our findings reveal that the layers closest to the network's input or output tend to exhibit more language-specific behaviour compared to the layers in the middle.
Team ÚFAL at CMCL 2022 Shared Task: Figuring out the correct recipe for predicting Eye-Tracking features using Pretrained Language Models
Apr 11, 2022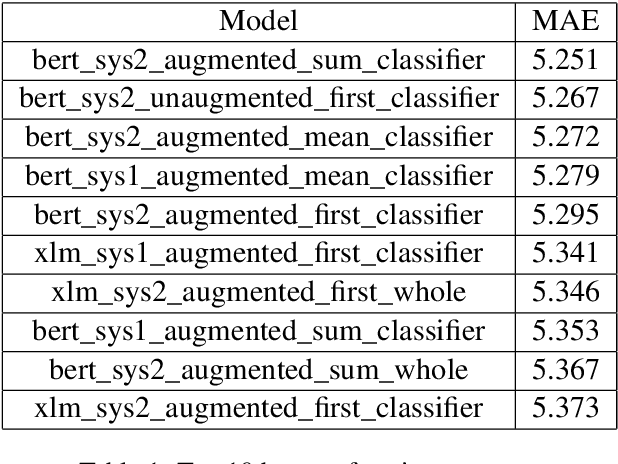
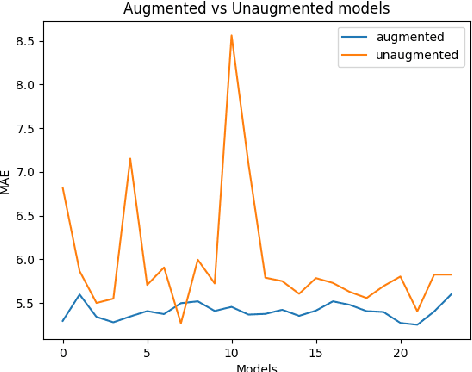
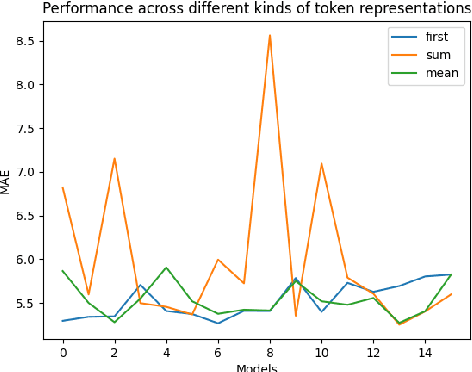
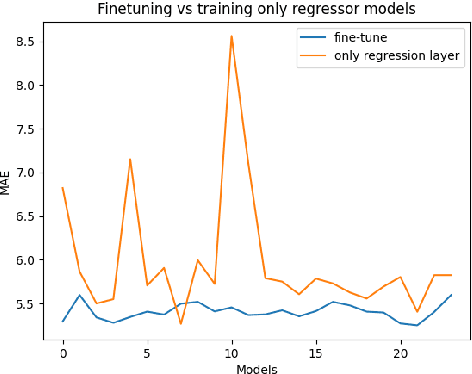
Eye-Tracking data is a very useful source of information to study cognition and especially language comprehension in humans. In this paper, we describe our systems for the CMCL 2022 shared task on predicting eye-tracking information. We describe our experiments with pretrained models like BERT and XLM and the different ways in which we used those representations to predict four eye-tracking features. Along with analysing the effect of using two different kinds of pretrained multilingual language models and different ways of pooling the tokenlevel representations, we also explore how contextual information affects the performance of the systems. Finally, we also explore if factors like augmenting linguistic information affect the predictions. Our submissions achieved an average MAE of 5.72 and ranked 5th in the shared task. The average MAE showed further reduction to 5.25 in post task evaluation.
Announcing CzEng 2.0 Parallel Corpus with over 2 Gigawords
Jul 06, 2020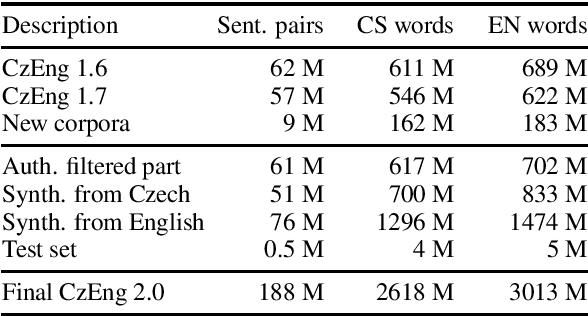
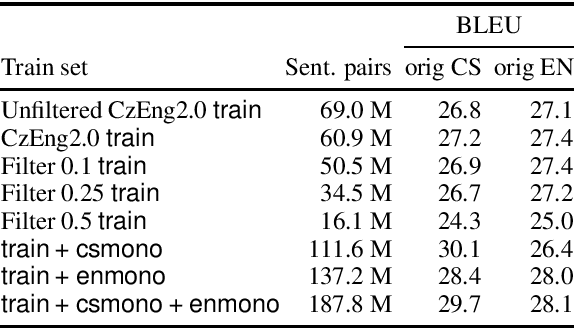
We present a new release of the Czech-English parallel corpus CzEng 2.0 consisting of over 2 billion words (2 "gigawords") in each language. The corpus contains document-level information and is filtered with several techniques to lower the amount of noise. In addition to the data in the previous version of CzEng, it contains new authentic and also high-quality synthetic parallel data. CzEng is freely available for research and educational purposes.
Curriculum Learning and Minibatch Bucketing in Neural Machine Translation
Jul 29, 2017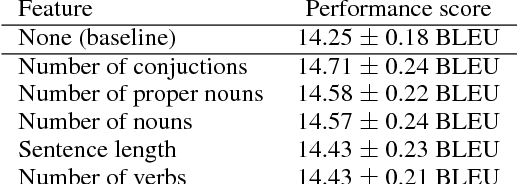
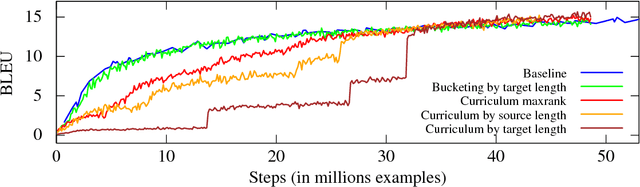

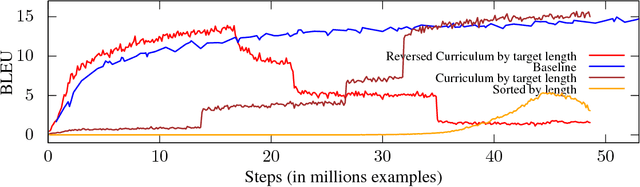
We examine the effects of particular orderings of sentence pairs on the on-line training of neural machine translation (NMT). We focus on two types of such orderings: (1) ensuring that each minibatch contains sentences similar in some aspect and (2) gradual inclusion of some sentence types as the training progresses (so called "curriculum learning"). In our English-to-Czech experiments, the internal homogeneity of minibatches has no effect on the training but some of our "curricula" achieve a small improvement over the baseline.
HUME: Human UCCA-Based Evaluation of Machine Translation
Sep 27, 2016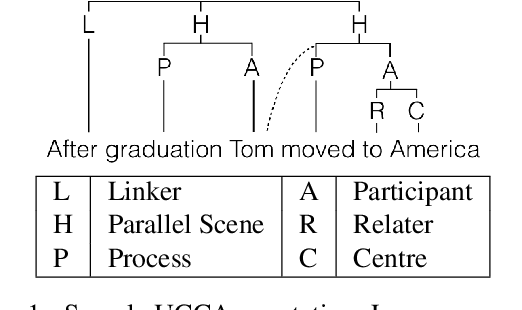

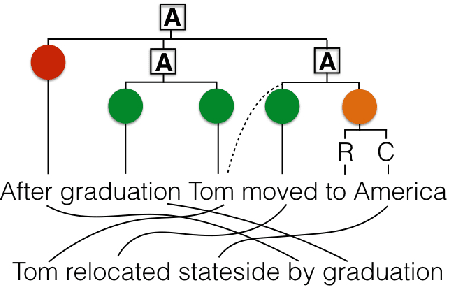

Human evaluation of machine translation normally uses sentence-level measures such as relative ranking or adequacy scales. However, these provide no insight into possible errors, and do not scale well with sentence length. We argue for a semantics-based evaluation, which captures what meaning components are retained in the MT output, thus providing a more fine-grained analysis of translation quality, and enabling the construction and tuning of semantics-based MT. We present a novel human semantic evaluation measure, Human UCCA-based MT Evaluation (HUME), building on the UCCA semantic representation scheme. HUME covers a wider range of semantic phenomena than previous methods and does not rely on semantic annotation of the potentially garbled MT output. We experiment with four language pairs, demonstrating HUME's broad applicability, and report good inter-annotator agreement rates and correlation with human adequacy scores.