 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowREm: A Repository of Word Embeddings for 87 Low-Resource Languages Enhanced with Multilingual Graph Knowledge
Sep 26, 2024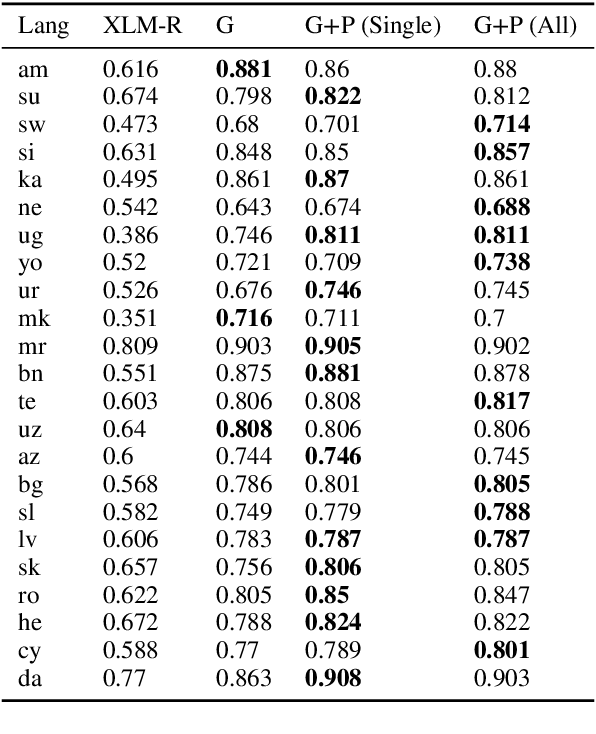
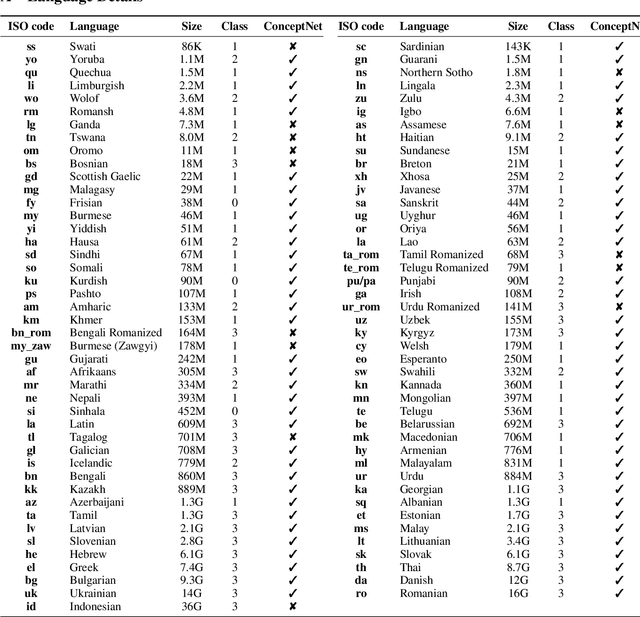
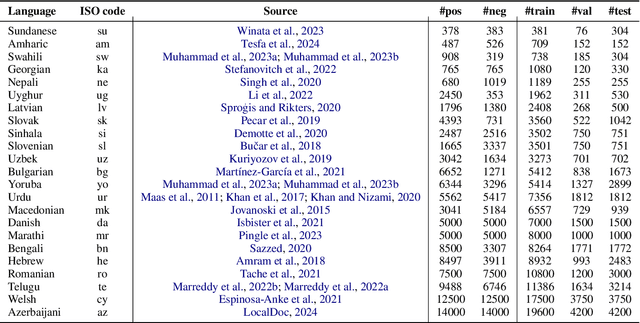
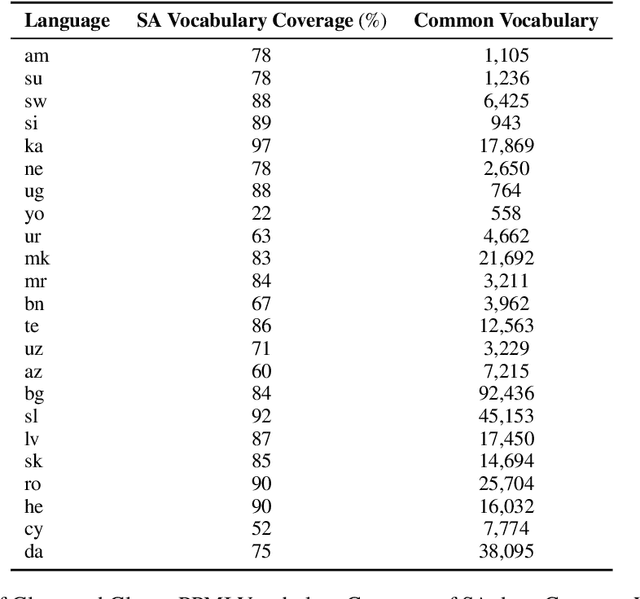
Contextualized embeddings based on large language models (LLMs) are available for various languages, but their coverage is often limited for lower resourced languages. Training LLMs for such languages is often difficult due to insufficient data and high computational cost. Especially for very low resource languages, static word embeddings thus still offer a viable alternative. There is, however, a notable lack of comprehensive repositories with such embeddings for diverse languages. To address this, we present LowREm, a centralized repository of static embeddings for 87 low-resource languages. We also propose a novel method to enhance GloVe-based embeddings by integrating multilingual graph knowledge, utilizing another source of knowledge. We demonstrate the superior performance of our enhanced embeddings as compared to contextualized embeddings extracted from XLM-R on sentiment analysis. Our code and data are publicly available under https://huggingface.co/DFKI.
SEntFiN 1.0: Entity-Aware Sentiment Analysis for Financial News
May 20, 2023Fine-grained financial sentiment analysis on news headlines is a challenging task requiring human-annotated datasets to achieve high performance. Limited studies have tried to address the sentiment extraction task in a setting where multiple entities are present in a news headline. In an effort to further research in this area, we make publicly available SEntFiN 1.0, a human-annotated dataset of 10,753 news headlines with entity-sentiment annotations, of which 2,847 headlines contain multiple entities, often with conflicting sentiments. We augment our dataset with a database of over 1,000 financial entities and their various representations in news media amounting to over 5,000 phrases. We propose a framework that enables the extraction of entity-relevant sentiments using a feature-based approach rather than an expression-based approach. For sentiment extraction, we utilize 12 different learning schemes utilizing lexicon-based and pre-trained sentence representations and five classification approaches. Our experiments indicate that lexicon-based n-gram ensembles are above par with pre-trained word embedding schemes such as GloVe. Overall, RoBERTa and finBERT (domain-specific BERT) achieve the highest average accuracy of 94.29% and F1-score of 93.27%. Further, using over 210,000 entity-sentiment predictions, we validate the economic effect of sentiments on aggregate market movements over a long duration.
Team ÚFAL at CMCL 2022 Shared Task: Figuring out the correct recipe for predicting Eye-Tracking features using Pretrained Language Models
Apr 11, 2022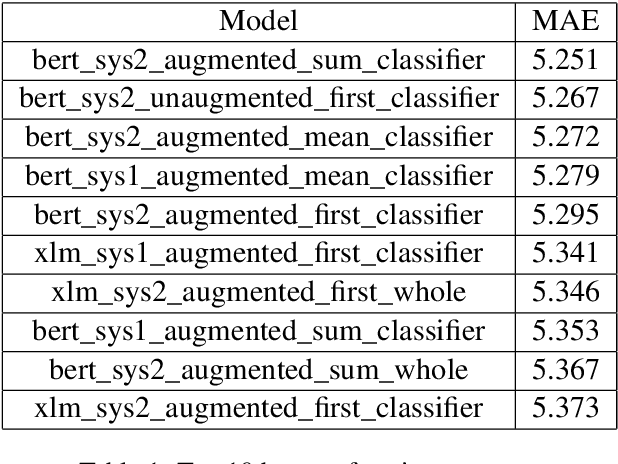
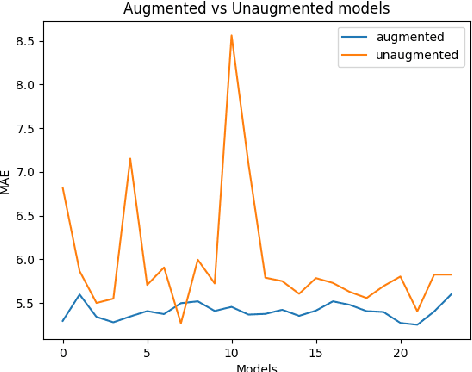
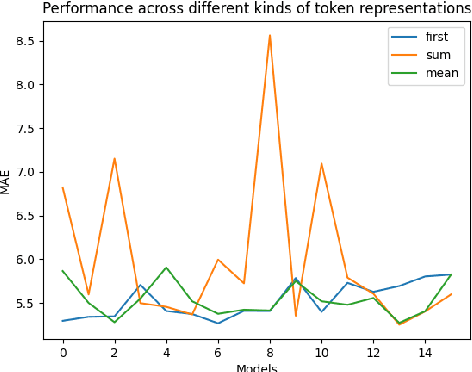
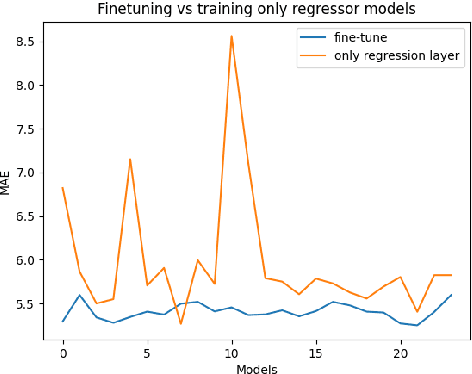
Eye-Tracking data is a very useful source of information to study cognition and especially language comprehension in humans. In this paper, we describe our systems for the CMCL 2022 shared task on predicting eye-tracking information. We describe our experiments with pretrained models like BERT and XLM and the different ways in which we used those representations to predict four eye-tracking features. Along with analysing the effect of using two different kinds of pretrained multilingual language models and different ways of pooling the tokenlevel representations, we also explore how contextual information affects the performance of the systems. Finally, we also explore if factors like augmenting linguistic information affect the predictions. Our submissions achieved an average MAE of 5.72 and ranked 5th in the shared task. The average MAE showed further reduction to 5.25 in post task evaluation.
Short-Term Word-Learning in a Dynamically Changing Environment
Mar 29, 2022



Neural sequence-to-sequence automatic speech recognition (ASR) systems are in principle open vocabulary systems, when using appropriate modeling units. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem, Huber et al. proposed to supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. In this paper we study, a) methods to acquire important words for this memory dynamically and, b) the trade-off between improvement in recognition accuracy of new words and the potential danger of false alarms for those added words. We demonstrate significant improvements in the detection rate of new words with only a minor increase in false alarms (F1 score 0.30 $\rightarrow$ 0.80), when using an appropriate number of new words. In addition, we show that important keywords can be extracted from supporting documents and used effectively.