 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Regularization and Convergence of Policy Gradient Flows under Safety Constraints
Nov 28, 2024This paper studies reinforcement learning (RL) in infinite-horizon dynamic decision processes with almost-sure safety constraints. Such safety-constrained decision processes are central to applications in autonomous systems, finance, and resource management, where policies must satisfy strict, state-dependent constraints. We consider a doubly-regularized RL framework that combines reward and parameter regularization to address these constraints within continuous state-action spaces. Specifically, we formulate the problem as a convex regularized objective with parametrized policies in the mean-field regime. Our approach leverages recent developments in mean-field theory and Wasserstein gradient flows to model policies as elements of an infinite-dimensional statistical manifold, with policy updates evolving via gradient flows on the space of parameter distributions. Our main contributions include establishing solvability conditions for safety-constrained problems, defining smooth and bounded approximations that facilitate gradient flows, and demonstrating exponential convergence towards global solutions under sufficient regularization. We provide general conditions on regularization functions, encompassing standard entropy regularization as a special case. The results also enable a particle method implementation for practical RL applications. The theoretical insights and convergence guarantees presented here offer a robust framework for safe RL in complex, high-dimensional decision-making problems.
SEntFiN 1.0: Entity-Aware Sentiment Analysis for Financial News
May 20, 2023Fine-grained financial sentiment analysis on news headlines is a challenging task requiring human-annotated datasets to achieve high performance. Limited studies have tried to address the sentiment extraction task in a setting where multiple entities are present in a news headline. In an effort to further research in this area, we make publicly available SEntFiN 1.0, a human-annotated dataset of 10,753 news headlines with entity-sentiment annotations, of which 2,847 headlines contain multiple entities, often with conflicting sentiments. We augment our dataset with a database of over 1,000 financial entities and their various representations in news media amounting to over 5,000 phrases. We propose a framework that enables the extraction of entity-relevant sentiments using a feature-based approach rather than an expression-based approach. For sentiment extraction, we utilize 12 different learning schemes utilizing lexicon-based and pre-trained sentence representations and five classification approaches. Our experiments indicate that lexicon-based n-gram ensembles are above par with pre-trained word embedding schemes such as GloVe. Overall, RoBERTa and finBERT (domain-specific BERT) achieve the highest average accuracy of 94.29% and F1-score of 93.27%. Further, using over 210,000 entity-sentiment predictions, we validate the economic effect of sentiments on aggregate market movements over a long duration.
Predicting Visit Cost of Obstructive Sleep Apnea using Electronic Healthcare Records with Transformer
Jan 28, 2023Background: Obstructive sleep apnea (OSA) is growing increasingly prevalent in many countries as obesity rises. Sufficient, effective treatment of OSA entails high social and financial costs for healthcare. Objective: For treatment purposes, predicting OSA patients' visit expenses for the coming year is crucial. Reliable estimates enable healthcare decision-makers to perform careful fiscal management and budget well for effective distribution of resources to hospitals. The challenges created by scarcity of high-quality patient data are exacerbated by the fact that just a third of those data from OSA patients can be used to train analytics models: only OSA patients with more than 365 days of follow-up are relevant for predicting a year's expenditures. Methods and procedures: The authors propose a method applying two Transformer models, one for augmenting the input via data from shorter visit histories and the other predicting the costs by considering both the material thus enriched and cases with more than a year's follow-up. Results: The two-model solution permits putting the limited body of OSA patient data to productive use. Relative to a single-Transformer solution using only a third of the high-quality patient data, the solution with two models improved the prediction performance's $R^{2}$ from 88.8% to 97.5%. Even using baseline models with the model-augmented data improved the $R^{2}$ considerably, from 61.6% to 81.9%. Conclusion: The proposed method makes prediction with the most of the available high-quality data by carefully exploiting details, which are not directly relevant for answering the question of the next year's likely expenditure.
A Review on Bilevel Optimization: From Classical to Evolutionary Approaches and Applications
May 17, 2017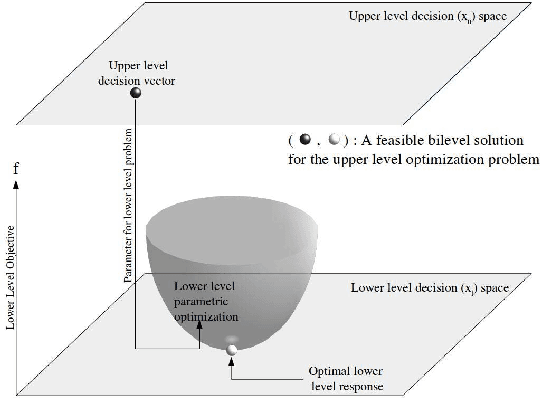
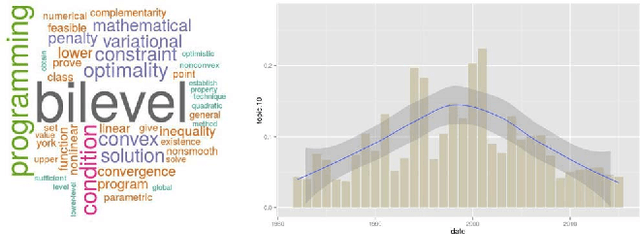
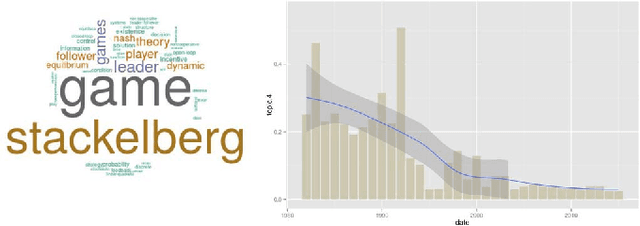
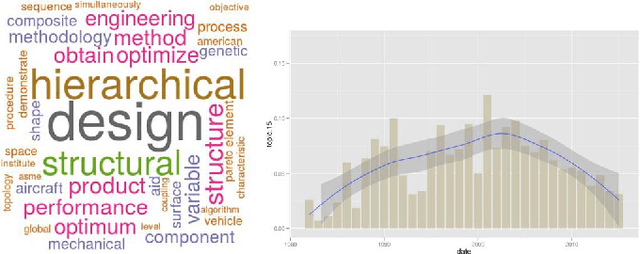
Bilevel optimization is defined as a mathematical program, where an optimization problem contains another optimization problem as a constraint. These problems have received significant attention from the mathematical programming community. Only limited work exists on bilevel problems using evolutionary computation techniques; however, recently there has been an increasing interest due to the proliferation of practical applications and the potential of evolutionary algorithms in tackling these problems. This paper provides a comprehensive review on bilevel optimization from the basic principles to solution strategies; both classical and evolutionary. A number of potential application problems are also discussed. To offer the readers insights on the prominent developments in the field of bilevel optimization, we have performed an automated text-analysis of an extended list of papers published on bilevel optimization to date. This paper should motivate evolutionary computation researchers to pay more attention to this practical yet challenging area.
Optimal Management of Naturally Regenerating Uneven-aged Forests
Aug 17, 2016

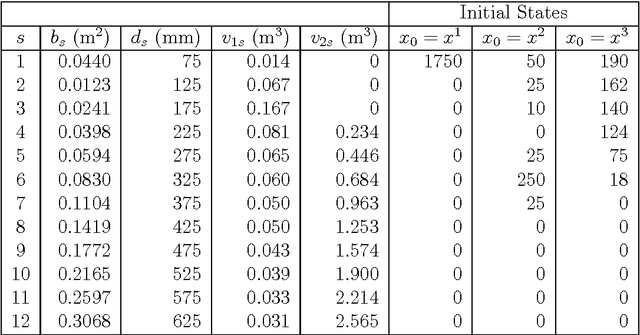
A shift from even-aged forest management to uneven-aged management practices leads to a problem rather different from the existing straightforward practice that follows a rotation cycle of artificial regeneration, thinning of inferior trees and a clearcut. A lack of realistic models and methods suggesting how to manage uneven-aged stands in a way that is economically viable and ecologically sustainable creates difficulties in adopting this new management practice. To tackle this problem, we make a two-fold contribution in this paper. The first contribution is the proposal of an algorithm that is able to handle a realistic uneven-aged stand management model that is otherwise computationally tedious and intractable. The model considered in this paper is an empirically estimated size-structured ecological model for uneven-aged spruce forests. The second contribution is on the sensitivity analysis of the forest model with respect to a number of important parameters. The analysis provides us an insight into the behavior of the uneven-aged forest model.
A Multi-objective Exploratory Procedure for Regression Model Selection
Jul 13, 2016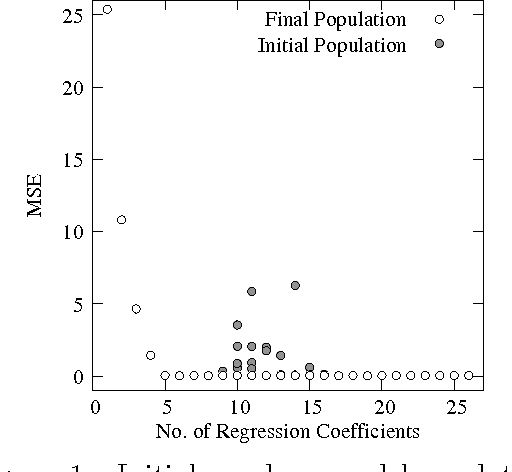
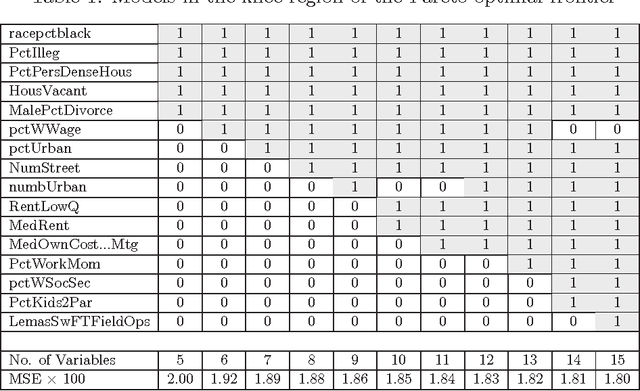

Variable selection is recognized as one of the most critical steps in statistical modeling. The problems encountered in engineering and social sciences are commonly characterized by over-abundance of explanatory variables, non-linearities and unknown interdependencies between the regressors. An added difficulty is that the analysts may have little or no prior knowledge on the relative importance of the variables. To provide a robust method for model selection, this paper introduces the Multi-objective Genetic Algorithm for Variable Selection (MOGA-VS) that provides the user with an optimal set of regression models for a given data-set. The algorithm considers the regression problem as a two objective task, and explores the Pareto-optimal (best subset) models by preferring those models over the other which have less number of regression coefficients and better goodness of fit. The model exploration can be performed based on in-sample or generalization error minimization. The model selection is proposed to be performed in two steps. First, we generate the frontier of Pareto-optimal regression models by eliminating the dominated models without any user intervention. Second, a decision making process is executed which allows the user to choose the most preferred model using visualisations and simple metrics. The method has been evaluated on a recently published real dataset on Communities and Crime within United States.
Efficient Evolutionary Algorithm for Single-Objective Bilevel Optimization
Oct 07, 2013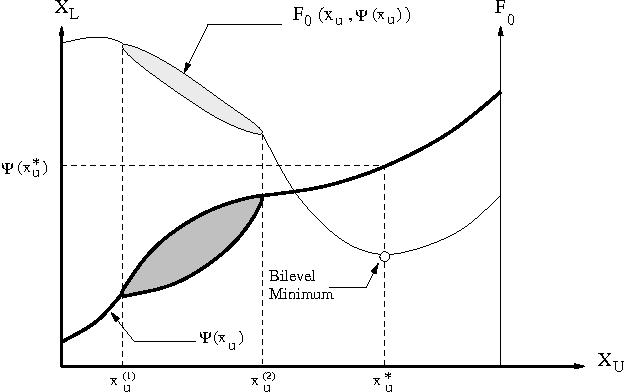
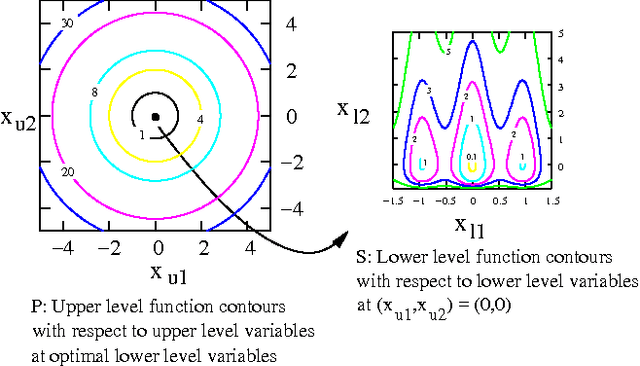
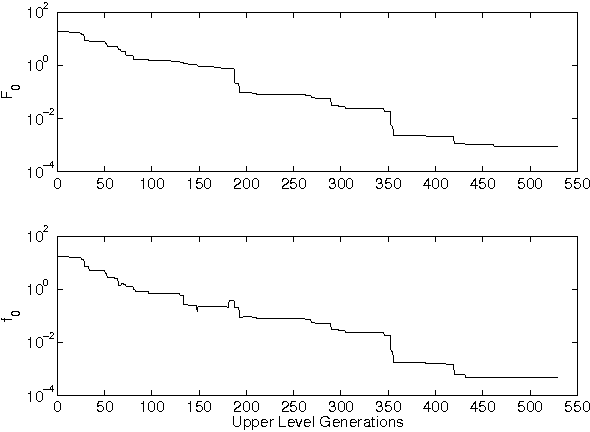
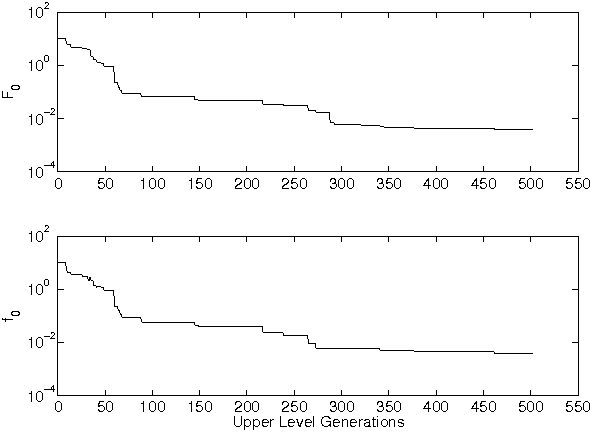
Bilevel optimization problems are a class of challenging optimization problems, which contain two levels of optimization tasks. In these problems, the optimal solutions to the lower level problem become possible feasible candidates to the upper level problem. Such a requirement makes the optimization problem difficult to solve, and has kept the researchers busy towards devising methodologies, which can efficiently handle the problem. Despite the efforts, there hardly exists any effective methodology, which is capable of handling a complex bilevel problem. In this paper, we introduce bilevel evolutionary algorithm based on quadratic approximations (BLEAQ) of optimal lower level variables with respect to the upper level variables. The approach is capable of handling bilevel problems with different kinds of complexities in relatively smaller number of function evaluations. Ideas from classical optimization have been hybridized with evolutionary methods to generate an efficient optimization algorithm for generic bilevel problems. The efficacy of the algorithm has been shown on two sets of test problems. The first set is a recently proposed SMD test set, which contains problems with controllable complexities, and the second set contains standard test problems collected from the literature. The proposed method has been evaluated against two benchmarks, and the performance gain is observed to be significant.
Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts
Jul 23, 2013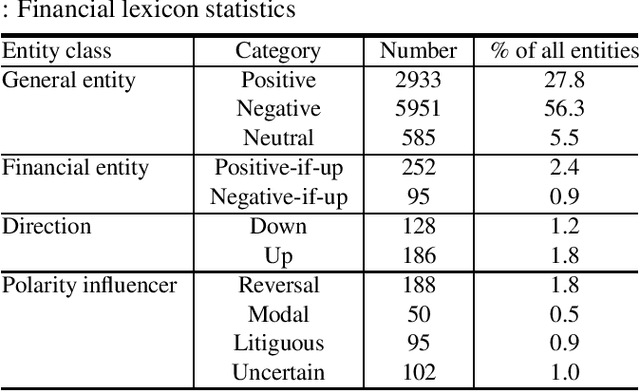

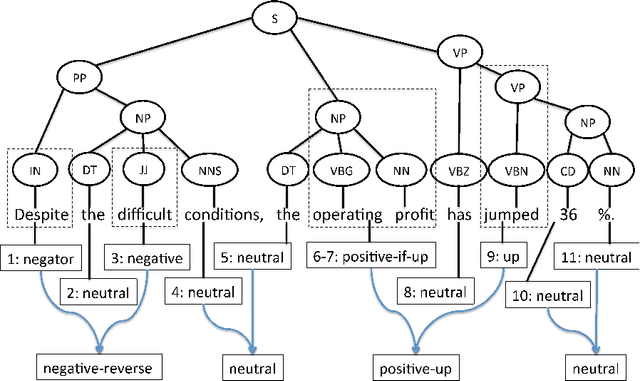
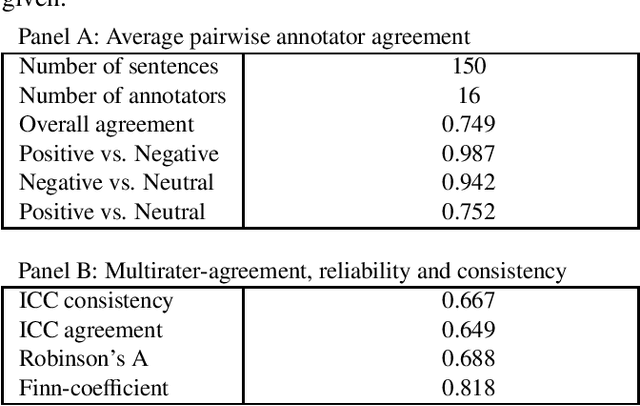
The use of robo-readers to analyze news texts is an emerging technology trend in computational finance. In recent research, a substantial effort has been invested to develop sophisticated financial polarity-lexicons that can be used to investigate how financial sentiments relate to future company performance. However, based on experience from other fields, where sentiment analysis is commonly applied, it is well-known that the overall semantic orientation of a sentence may differ from the prior polarity of individual words. The objective of this article is to investigate how semantic orientations can be better detected in financial and economic news by accommodating the overall phrase-structure information and domain-specific use of language. Our three main contributions are: (1) establishment of a human-annotated finance phrase-bank, which can be used as benchmark for training and evaluating alternative models; (2) presentation of a technique to enhance financial lexicons with attributes that help to identify expected direction of events that affect overall sentiment; (3) development of a linearized phrase-structure model for detecting contextual semantic orientations in financial and economic news texts. The relevance of the newly added lexicon features and the benefit of using the proposed learning-algorithm are demonstrated in a comparative study against previously used general sentiment models as well as the popular word frequency models used in recent financial studies. The proposed framework is parsimonious and avoids the explosion in feature-space caused by the use of conventional n-gram features.
Automated Query Learning with Wikipedia and Genetic Programming
Dec 03, 2010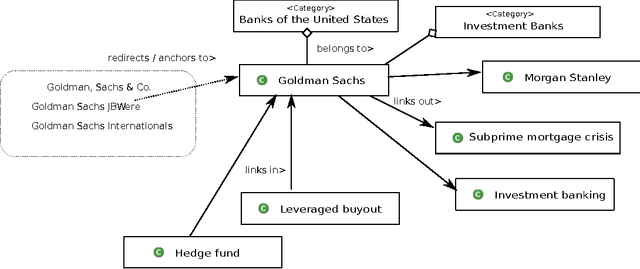

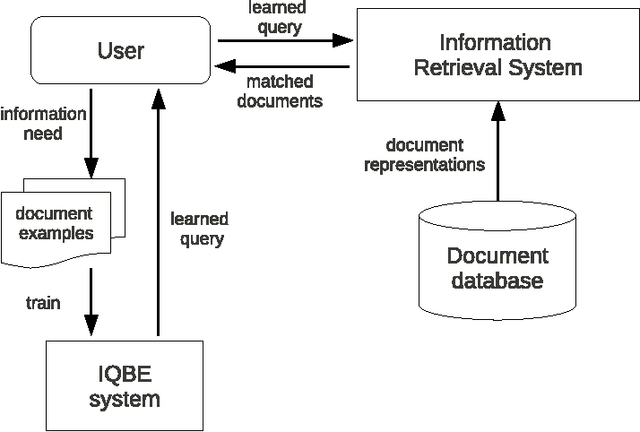

Most of the existing information retrieval systems are based on bag of words model and are not equipped with common world knowledge. Work has been done towards improving the efficiency of such systems by using intelligent algorithms to generate search queries, however, not much research has been done in the direction of incorporating human-and-society level knowledge in the queries. This paper is one of the first attempts where such information is incorporated into the search queries using Wikipedia semantics. The paper presents an essential shift from conventional token based queries to concept based queries, leading to an enhanced efficiency of information retrieval systems. To efficiently handle the automated query learning problem, we propose Wikipedia-based Evolutionary Semantics (Wiki-ES) framework where concept based queries are learnt using a co-evolving evolutionary procedure. Learning concept based queries using an intelligent evolutionary procedure yields significant improvement in performance which is shown through an extensive study using Reuters newswire documents. Comparison of the proposed framework is performed with other information retrieval systems. Concept based approach has also been implemented on other information retrieval systems to justify the effectiveness of a transition from token based queries to concept based queries.