 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the role of FFNs in driving multilingual behaviour in LLMs
Apr 22, 2024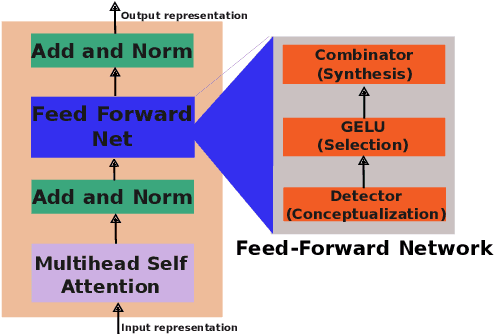
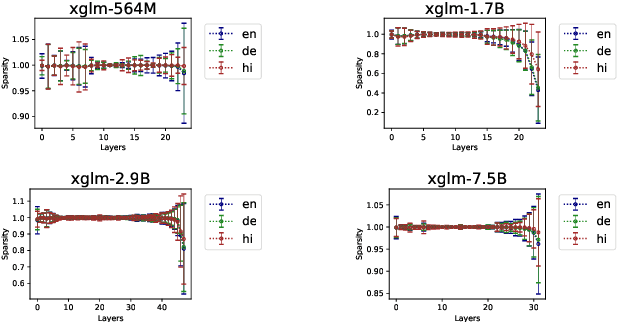
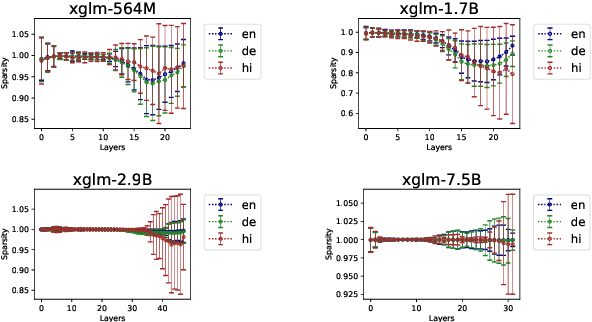
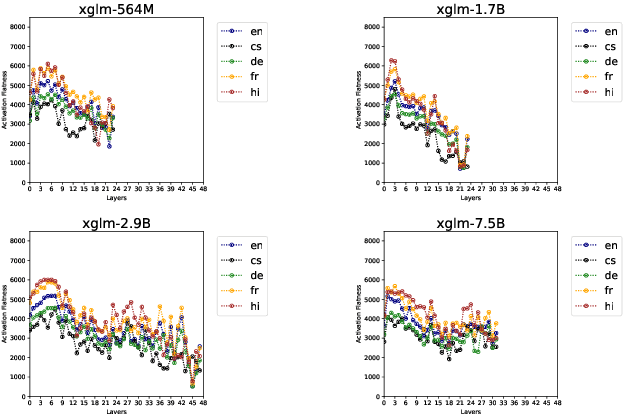
Multilingualism in Large Language Models (LLMs) is an yet under-explored area. In this paper, we conduct an in-depth analysis of the multilingual capabilities of a family of a Large Language Model, examining its architecture, activation patterns, and processing mechanisms across languages. We introduce novel metrics to probe the model's multilingual behaviour at different layers and shed light on the impact of architectural choices on multilingual processing. Our findings reveal different patterns of multilinugal processing in the sublayers of Feed-Forward Networks of the models. Furthermore, we uncover the phenomenon of "over-layerization" in certain model configurations, where increasing layer depth without corresponding adjustments to other parameters may degrade model performance. Through comparisons within and across languages, we demonstrate the interplay between model architecture, layer depth, and multilingual processing capabilities of LLMs trained on multiple languages.
Unveiling Multilinguality in Transformer Models: Exploring Language Specificity in Feed-Forward Networks
Oct 24, 2023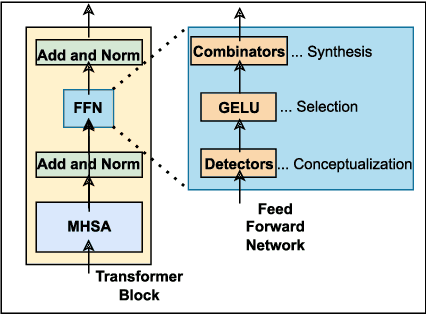
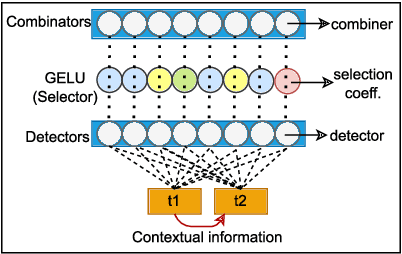
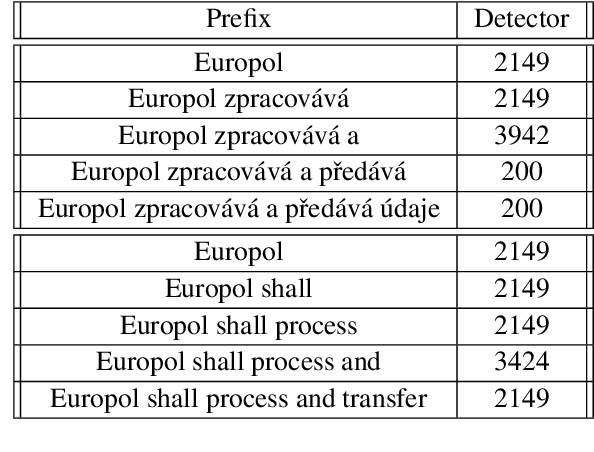
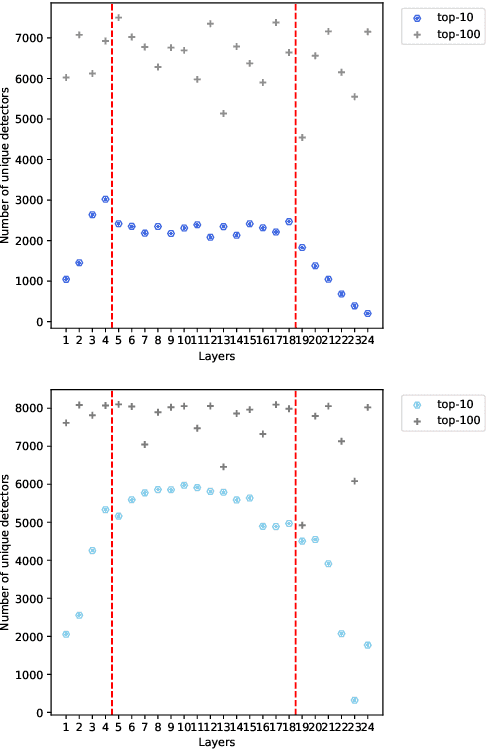
Recent research suggests that the feed-forward module within Transformers can be viewed as a collection of key-value memories, where the keys learn to capture specific patterns from the input based on the training examples. The values then combine the output from the 'memories' of the keys to generate predictions about the next token. This leads to an incremental process of prediction that gradually converges towards the final token choice near the output layers. This interesting perspective raises questions about how multilingual models might leverage this mechanism. Specifically, for autoregressive models trained on two or more languages, do all neurons (across layers) respond equally to all languages? No! Our hypothesis centers around the notion that during pretraining, certain model parameters learn strong language-specific features, while others learn more language-agnostic (shared across languages) features. To validate this, we conduct experiments utilizing parallel corpora of two languages that the model was initially pretrained on. Our findings reveal that the layers closest to the network's input or output tend to exhibit more language-specific behaviour compared to the layers in the middle.
Multimodal Shannon Game with Images
Mar 20, 2023

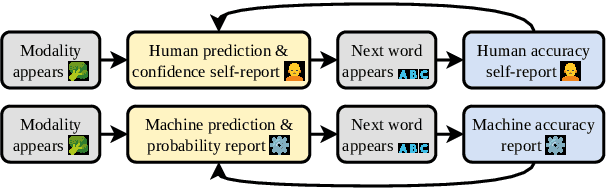

The Shannon game has long been used as a thought experiment in linguistics and NLP, asking participants to guess the next letter in a sentence based on its preceding context. We extend the game by introducing an optional extra modality in the form of image information. To investigate the impact of multimodal information in this game, we use human participants and a language model (LM, GPT-2). We show that the addition of image information improves both self-reported confidence and accuracy for both humans and LM. Certain word classes, such as nouns and determiners, benefit more from the additional modality information. The priming effect in both humans and the LM becomes more apparent as the context size (extra modality information + sentence context) increases. These findings highlight the potential of multimodal information in improving language understanding and modeling.
Sentence Ambiguity, Grammaticality and Complexity Probes
Oct 15, 2022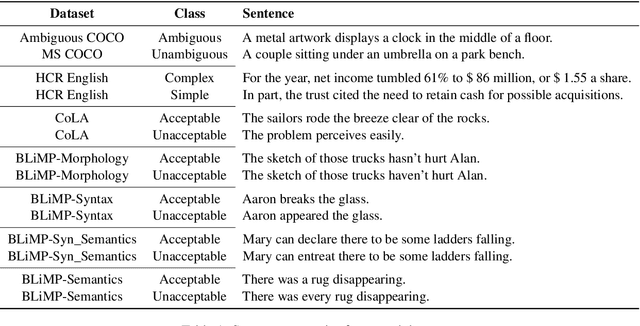

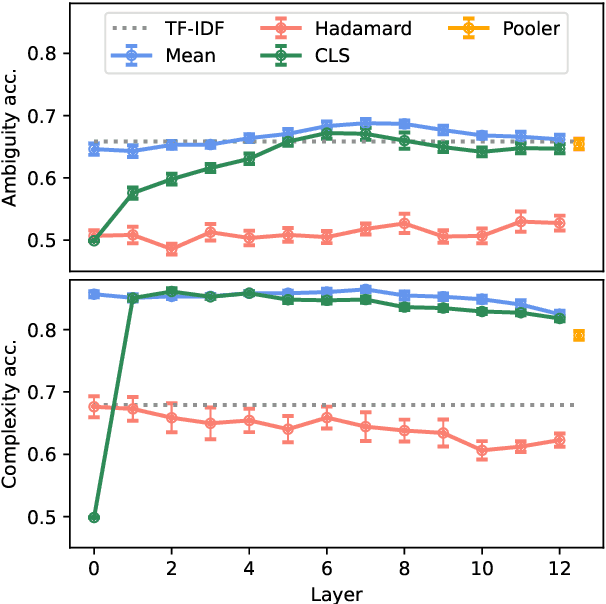
It is unclear whether, how and where large pre-trained language models capture subtle linguistic traits like ambiguity, grammaticality and sentence complexity. We present results of automatic classification of these traits and compare their viability and patterns across representation types. We demonstrate that template-based datasets with surface-level artifacts should not be used for probing, careful comparisons with baselines should be done and that t-SNE plots should not be used to determine the presence of a feature among dense vectors representations. We also show how features might be highly localized in the layers for these models and get lost in the upper layers.
Team ÚFAL at CMCL 2022 Shared Task: Figuring out the correct recipe for predicting Eye-Tracking features using Pretrained Language Models
Apr 11, 2022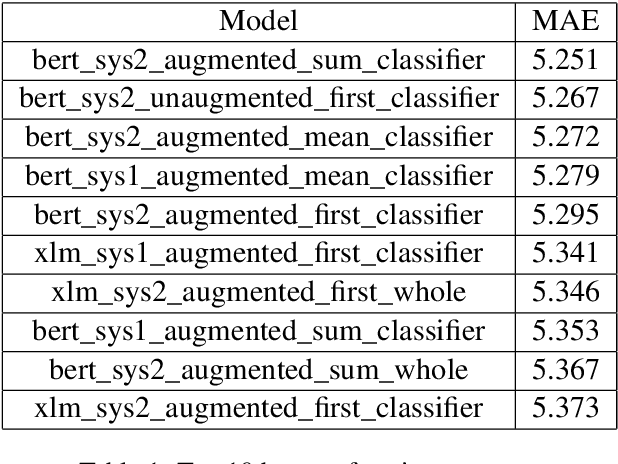
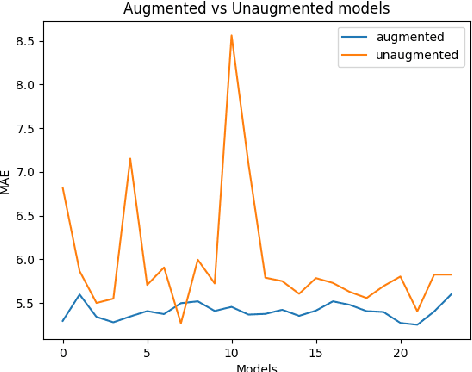
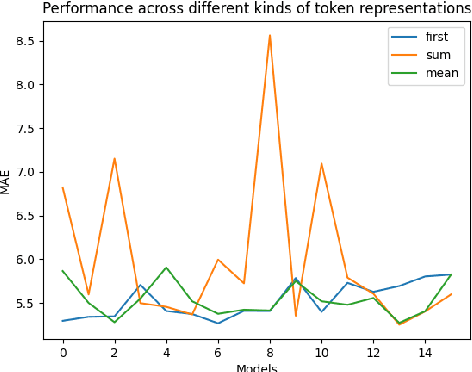
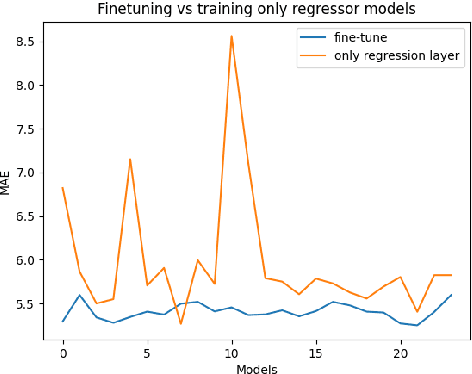
Eye-Tracking data is a very useful source of information to study cognition and especially language comprehension in humans. In this paper, we describe our systems for the CMCL 2022 shared task on predicting eye-tracking information. We describe our experiments with pretrained models like BERT and XLM and the different ways in which we used those representations to predict four eye-tracking features. Along with analysing the effect of using two different kinds of pretrained multilingual language models and different ways of pooling the tokenlevel representations, we also explore how contextual information affects the performance of the systems. Finally, we also explore if factors like augmenting linguistic information affect the predictions. Our submissions achieved an average MAE of 5.72 and ranked 5th in the shared task. The average MAE showed further reduction to 5.25 in post task evaluation.
EMMT: A simultaneous eye-tracking, 4-electrode EEG and audio corpus for multi-modal reading and translation scenarios
Apr 06, 2022



We present the Eyetracked Multi-Modal Translation (EMMT) corpus, a dataset containing monocular eye movement recordings, audio and 4-electrode electroencephalogram (EEG) data of 43 participants. The objective was to collect cognitive signals as responses of participants engaged in a number of language intensive tasks involving different text-image stimuli settings when translating from English to Czech. Each participant was exposed to 32 text-image stimuli pairs and asked to (1) read the English sentence, (2) translate it into Czech, (3) consult the image, (4) translate again, either updating or repeating the previous translation. The text stimuli consisted of 200 unique sentences with 616 unique words coupled with 200 unique images as the visual stimuli. The recordings were collected over a two week period and all the participants included in the study were Czech natives with strong English skills. Due to the nature of the tasks involved in the study and the relatively large number of participants involved, the corpus is well suited for research in Translation Process Studies, Cognitive Sciences among other disciplines.