 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Language Barriers in Education: Developing Multilingual Digital Learning Materials with Machine Translation
Sep 11, 2025The EdUKate project combines digital education, linguistics, translation studies, and machine translation to develop multilingual learning materials for Czech primary and secondary schools. Launched through collaboration between a major Czech academic institution and the country's largest educational publisher, the project is aimed at translating up to 9,000 multimodal interactive exercises from Czech into Ukrainian, English, and German for an educational web portal. It emphasizes the development and evaluation of a direct Czech-Ukrainian machine translation system tailored to the educational domain, with special attention to processing formatted content such as XML and PDF and handling technical and scientific terminology. We present findings from an initial survey of Czech teachers regarding the needs of non-Czech-speaking students and describe the system's evaluation and implementation on the web portal. All resulting applications are freely available to students, educators, and researchers.
* 8 pages, 2 figures
Evaluating Optimal Reference Translations
Nov 28, 2023

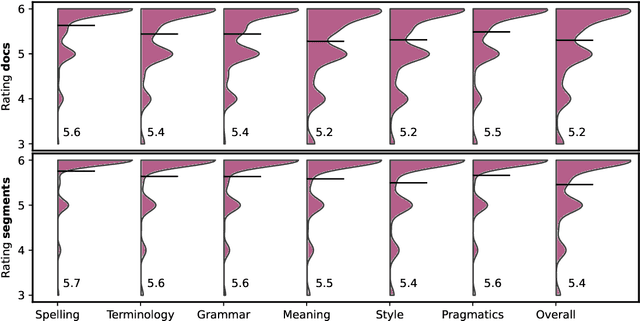
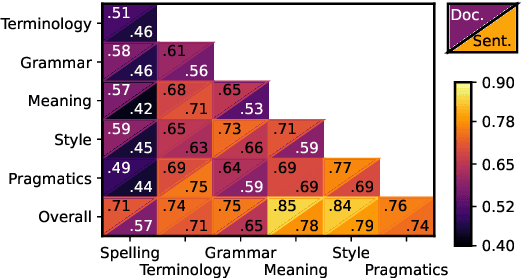
The overall translation quality reached by current machine translation (MT) systems for high-resourced language pairs is remarkably good. Standard methods of evaluation are not suitable nor intended to uncover the many translation errors and quality deficiencies that still persist. Furthermore, the quality of standard reference translations is commonly questioned and comparable quality levels have been reached by MT alone in several language pairs. Navigating further research in these high-resource settings is thus difficult. In this article, we propose a methodology for creating more reliable document-level human reference translations, called "optimal reference translations," with the simple aim to raise the bar of what should be deemed "human translation quality." We evaluate the obtained document-level optimal reference translations in comparison with "standard" ones, confirming a significant quality increase and also documenting the relationship between evaluation and translation editing.
EMMT: A simultaneous eye-tracking, 4-electrode EEG and audio corpus for multi-modal reading and translation scenarios
Apr 06, 2022



We present the Eyetracked Multi-Modal Translation (EMMT) corpus, a dataset containing monocular eye movement recordings, audio and 4-electrode electroencephalogram (EEG) data of 43 participants. The objective was to collect cognitive signals as responses of participants engaged in a number of language intensive tasks involving different text-image stimuli settings when translating from English to Czech. Each participant was exposed to 32 text-image stimuli pairs and asked to (1) read the English sentence, (2) translate it into Czech, (3) consult the image, (4) translate again, either updating or repeating the previous translation. The text stimuli consisted of 200 unique sentences with 616 unique words coupled with 200 unique images as the visual stimuli. The recordings were collected over a two week period and all the participants included in the study were Czech natives with strong English skills. Due to the nature of the tasks involved in the study and the relatively large number of participants involved, the corpus is well suited for research in Translation Process Studies, Cognitive Sciences among other disciplines.