 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Language Barriers in Education: Developing Multilingual Digital Learning Materials with Machine Translation
Sep 11, 2025The EdUKate project combines digital education, linguistics, translation studies, and machine translation to develop multilingual learning materials for Czech primary and secondary schools. Launched through collaboration between a major Czech academic institution and the country's largest educational publisher, the project is aimed at translating up to 9,000 multimodal interactive exercises from Czech into Ukrainian, English, and German for an educational web portal. It emphasizes the development and evaluation of a direct Czech-Ukrainian machine translation system tailored to the educational domain, with special attention to processing formatted content such as XML and PDF and handling technical and scientific terminology. We present findings from an initial survey of Czech teachers regarding the needs of non-Czech-speaking students and describe the system's evaluation and implementation on the web portal. All resulting applications are freely available to students, educators, and researchers.
* 8 pages, 2 figures
Findings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Charles Translator: A Machine Translation System between Ukrainian and Czech
Apr 10, 2024



We present Charles Translator, a machine translation system between Ukrainian and Czech, developed as part of a society-wide effort to mitigate the impact of the Russian-Ukrainian war on individuals and society. The system was developed in the spring of 2022 with the help of many language data providers in order to quickly meet the demand for such a service, which was not available at the time in the required quality. The translator was later implemented as an online web interface and as an Android app with speech input, both featuring Cyrillic-Latin script transliteration. The system translates directly, compared to other available systems that use English as a pivot, and thus take advantage of the typological similarity of the two languages. It uses the block back-translation method, which allows for efficient use of monolingual training data. The paper describes the development process, including data collection and implementation, evaluation, mentions several use cases, and outlines possibilities for the further development of the system for educational purposes.
Evaluating Optimal Reference Translations
Nov 28, 2023

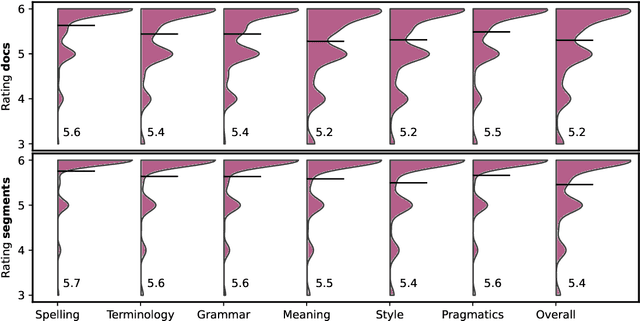
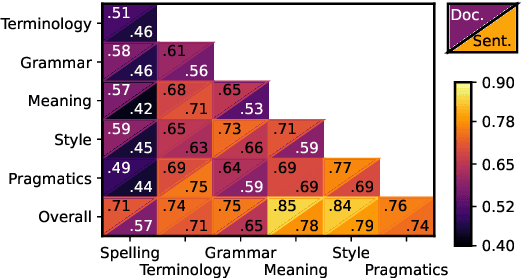
The overall translation quality reached by current machine translation (MT) systems for high-resourced language pairs is remarkably good. Standard methods of evaluation are not suitable nor intended to uncover the many translation errors and quality deficiencies that still persist. Furthermore, the quality of standard reference translations is commonly questioned and comparable quality levels have been reached by MT alone in several language pairs. Navigating further research in these high-resource settings is thus difficult. In this article, we propose a methodology for creating more reliable document-level human reference translations, called "optimal reference translations," with the simple aim to raise the bar of what should be deemed "human translation quality." We evaluate the obtained document-level optimal reference translations in comparison with "standard" ones, confirming a significant quality increase and also documenting the relationship between evaluation and translation editing.
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
CUNI Systems for the WMT22 Czech-Ukrainian Translation Task
Dec 01, 2022We present Charles University submissions to the WMT22 General Translation Shared Task on Czech-Ukrainian and Ukrainian-Czech machine translation. We present two constrained submissions based on block back-translation and tagged back-translation and experiment with rule-based romanization of Ukrainian. Our results show that the romanization only has a minor effect on the translation quality. Further, we describe Charles Translator, a system that was developed in March 2022 as a response to the migration from Ukraine to the Czech Republic. Compared to our constrained systems, it did not use the romanization and used some proprietary data sources.
CUNI Submission in WMT22 General Task
Nov 29, 2022We present the CUNI-Bergamot submission for the WMT22 General translation task. We compete in English$\rightarrow$Czech direction. Our submission further explores block backtranslation techniques. Compared to the previous work, we measure performance in terms of COMET score and named entities translation accuracy. We evaluate performance of MBR decoding compared to traditional mixed backtranslation training and we show a possible synergy when using both of the techniques simultaneously. The results show that both approaches are effective means of improving translation quality and they yield even better results when combined.
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022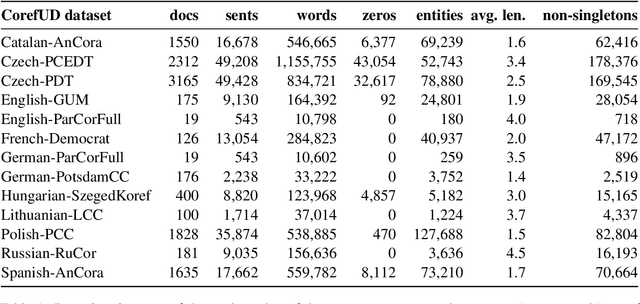
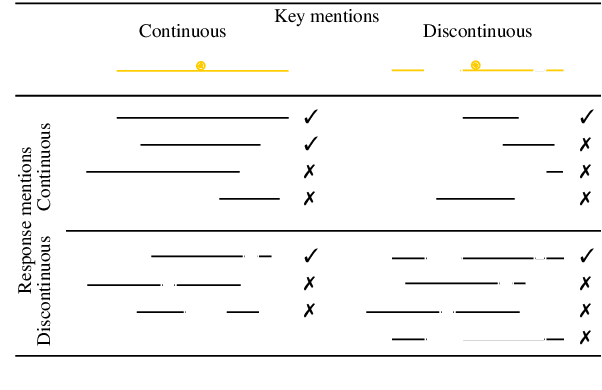

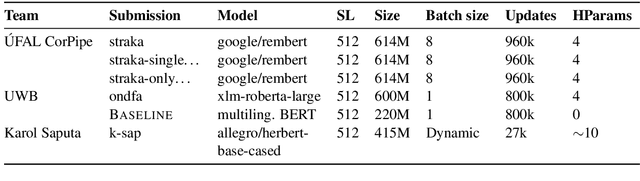
This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
Understanding Model Robustness to User-generated Noisy Texts
Oct 14, 2021

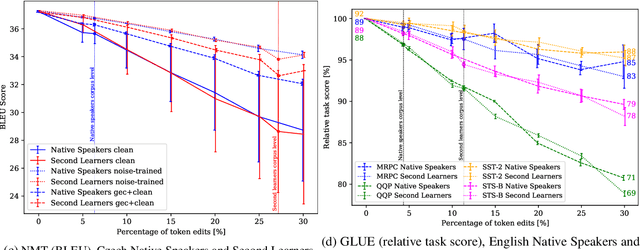
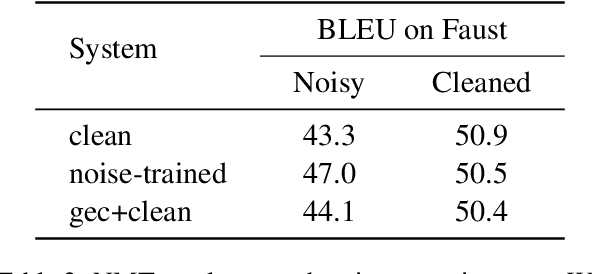
Sensitivity of deep-neural models to input noise is known to be a challenging problem. In NLP, model performance often deteriorates with naturally occurring noise, such as spelling errors. To mitigate this issue, models may leverage artificially noised data. However, the amount and type of generated noise has so far been determined arbitrarily. We therefore propose to model the errors statistically from grammatical-error-correction corpora. We present a thorough evaluation of several state-of-the-art NLP systems' robustness in multiple languages, with tasks including morpho-syntactic analysis, named entity recognition, neural machine translation, a subset of the GLUE benchmark and reading comprehension. We also compare two approaches to address the performance drop: a) training the NLP models with noised data generated by our framework; and b) reducing the input noise with external system for natural language correction. The code is released at https://github.com/ufal/kazitext.