 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNameTag 3: A Tool and a Service for Multilingual/Multitagset NER
Jun 06, 2025



We introduce NameTag 3, an open-source tool and cloud-based web service for multilingual, multidataset, and multitagset named entity recognition (NER), supporting both flat and nested entities. NameTag 3 achieves state-of-the-art results on 21 test datasets in 15 languages and remains competitive on the rest, even against larger models. It is available as a command-line tool and as a cloud-based service, enabling use without local installation. NameTag 3 web service currently provides flat NER for 17 languages, trained on 21 corpora and three NE tagsets, all powered by a single 355M-parameter fine-tuned model; and nested NER for Czech, powered by a 126M fine-tuned model. The source code is licensed under open-source MPL 2.0, while the models are distributed under non-commercial CC BY-NC-SA 4.0. Documentation is available at https://ufal.mff.cuni.cz/nametag, source code at https://github.com/ufal/nametag3, and trained models via https://lindat.cz. The REST service and the web application can be found at https://lindat.mff.cuni.cz/services/nametag/. A demonstration video is available at https://www.youtube.com/watch?v=-gaGnP0IV8A.
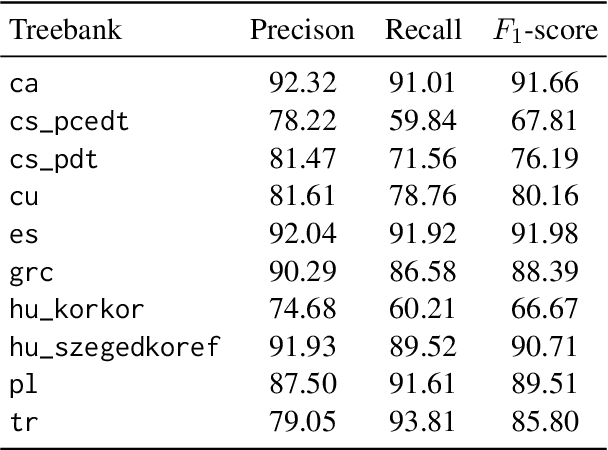
Findings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
CorPipe at CRAC 2024: Predicting Zero Mentions from Raw Text
Oct 03, 2024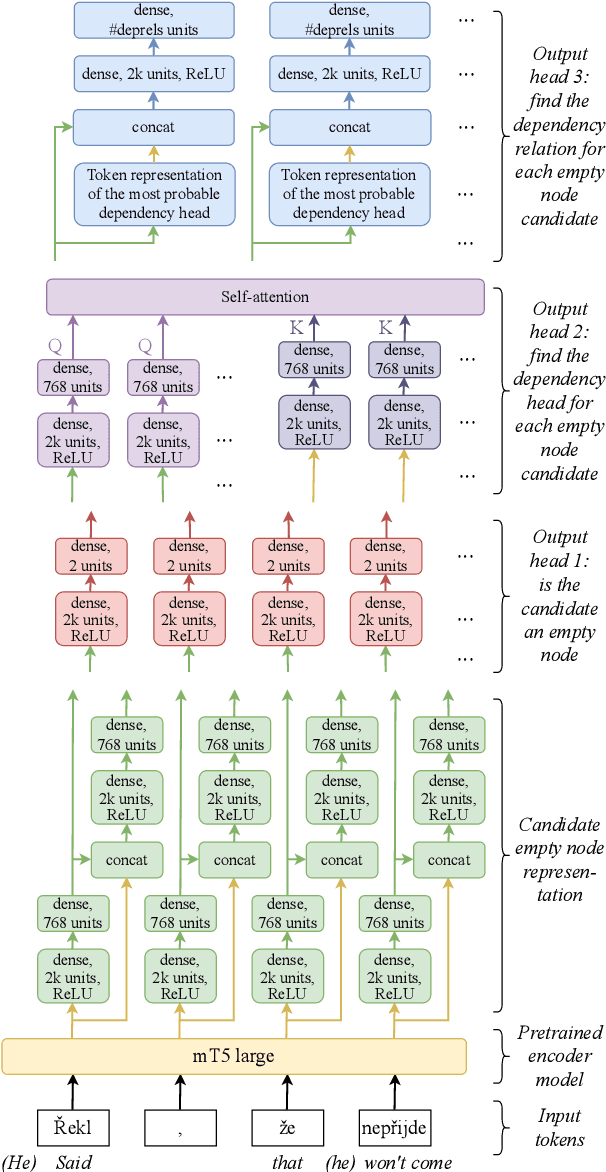

We present CorPipe 24, the winning entry to the CRAC 2024 Shared Task on Multilingual Coreference Resolution. In this third iteration of the shared task, a novel objective is to also predict empty nodes needed for zero coreference mentions (while the empty nodes were given on input in previous years). This way, coreference resolution can be performed on raw text. We evaluate two model variants: a~two-stage approach (where the empty nodes are predicted first using a pretrained encoder model and then processed together with sentence words by another pretrained model) and a single-stage approach (where a single pretrained encoder model generates empty nodes, coreference mentions, and coreference links jointly). In both settings, CorPipe surpasses other participants by a large margin of 3.9 and 2.8 percent points, respectively. The source code and the trained model are available at https://github.com/ufal/crac2024-corpipe .
beeFormer: Bridging the Gap Between Semantic and Interaction Similarity in Recommender Systems
Sep 16, 2024Recommender systems often use text-side information to improve their predictions, especially in cold-start or zero-shot recommendation scenarios, where traditional collaborative filtering approaches cannot be used. Many approaches to text-mining side information for recommender systems have been proposed over recent years, with sentence Transformers being the most prominent one. However, these models are trained to predict semantic similarity without utilizing interaction data with hidden patterns specific to recommender systems. In this paper, we propose beeFormer, a framework for training sentence Transformer models with interaction data. We demonstrate that our models trained with beeFormer can transfer knowledge between datasets while outperforming not only semantic similarity sentence Transformers but also traditional collaborative filtering methods. We also show that training on multiple datasets from different domains accumulates knowledge in a single model, unlocking the possibility of training universal, domain-agnostic sentence Transformer models to mine text representations for recommender systems. We release the source code, trained models, and additional details allowing replication of our experiments at https://github.com/recombee/beeformer.
Open-Source Web Service with Morphological Dictionary-Supplemented Deep Learning for Morphosyntactic Analysis of Czech
Jun 18, 2024We present an open-source web service for Czech morphosyntactic analysis. The system combines a deep learning model with rescoring by a high-precision morphological dictionary at inference time. We show that our hybrid method surpasses two competitive baselines: While the deep learning model ensures generalization for out-of-vocabulary words and better disambiguation, an improvement over an existing morphological analyser MorphoDiTa, at the same time, the deep learning model benefits from inference-time guidance of a manually curated morphological dictionary. We achieve 50% error reduction in lemmatization and 58% error reduction in POS tagging over MorphoDiTa, while also offering dependency parsing. The model is trained on one of the currently largest Czech morphosyntactic corpora, the PDT-C 1.0, with the trained models available at https://hdl.handle.net/11234/1-5293. We provide the tool as a web service deployed at https://lindat.mff.cuni.cz/services/udpipe/. The source code is available at GitHub (https://github.com/ufal/udpipe/tree/udpipe-2), along with a Python client for a simple use. The documentation for the models can be found at https://ufal.mff.cuni.cz/udpipe/2/models#czech_pdtc1.0_model.
CWRCzech: 100M Query-Document Czech Click Dataset and Its Application to Web Relevance Ranking
May 31, 2024We present CWRCzech, Click Web Ranking dataset for Czech, a 100M query-document Czech click dataset for relevance ranking with user behavior data collected from search engine logs of Seznam.cz. To the best of our knowledge, CWRCzech is the largest click dataset with raw text published so far. It provides document positions in the search results as well as information about user behavior: 27.6M clicked documents and 10.8M dwell times. In addition, we also publish a manually annotated Czech test for the relevance task, containing nearly 50k query-document pairs, each annotated by at least 2 annotators. Finally, we analyze how the user behavior data improve relevance ranking and show that models trained on data automatically harnessed at sufficient scale can surpass the performance of models trained on human annotated data. CWRCzech is published under an academic non-commercial license and is available to the research community at https://github.com/seznam/CWRCzech.
ÚFAL LatinPipe at EvaLatin 2024: Morphosyntactic Analysis of Latin
Apr 08, 2024



We present LatinPipe, the winning submission to the EvaLatin 2024 Dependency Parsing shared task. Our system consists of a fine-tuned concatenation of base and large pre-trained LMs, with a dot-product attention head for parsing and softmax classification heads for morphology to jointly learn both dependency parsing and morphological analysis. It is trained by sampling from seven publicly available Latin corpora, utilizing additional harmonization of annotations to achieve a more unified annotation style. Before fine-tuning, we train the system for a few initial epochs with frozen weights. We also add additional local relative contextualization by stacking the BiLSTM layers on top of the Transformer(s). Finally, we ensemble output probability distributions from seven randomly instantiated networks for the final submission. The code is available at https://github.com/ufal/evalatin2024-latinpipe.
Practical End-to-End Optical Music Recognition for Pianoform Music
Mar 20, 2024



The majority of recent progress in Optical Music Recognition (OMR) has been achieved with Deep Learning methods, especially models following the end-to-end paradigm, reading input images and producing a linear sequence of tokens. Unfortunately, many music scores, especially piano music, cannot be easily converted to a linear sequence. This has led OMR researchers to use custom linearized encodings, instead of broadly accepted structured formats for music notation. Their diversity makes it difficult to compare the performance of OMR systems directly. To bring recent OMR model progress closer to useful results: (a) We define a sequential format called Linearized MusicXML, allowing to train an end-to-end model directly and maintaining close cohesion and compatibility with the industry-standard MusicXML format. (b) We create a dev and test set for benchmarking typeset OMR with MusicXML ground truth based on the OpenScore Lieder corpus. They contain 1,438 and 1,493 pianoform systems, each with an image from IMSLP. (c) We train and fine-tune an end-to-end model to serve as a baseline on the dataset and employ the TEDn metric to evaluate the model. We also test our model against the recently published synthetic pianoform dataset GrandStaff and surpass the state-of-the-art results.
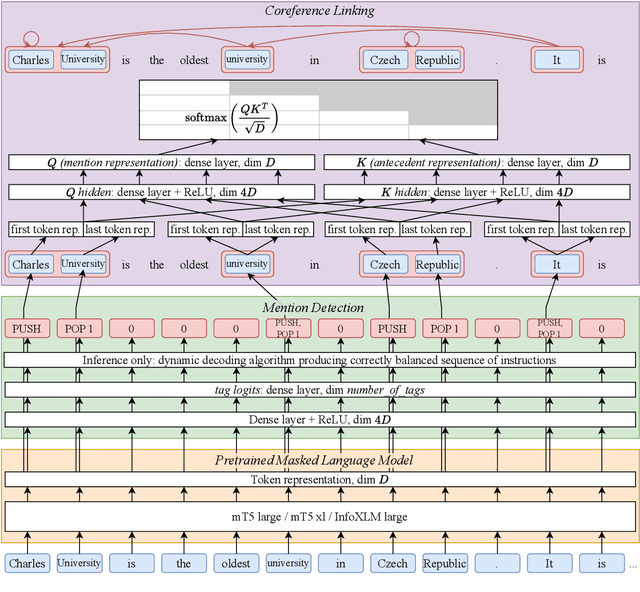
ÚFAL CorPipe at CRAC 2023: Larger Context Improves Multilingual Coreference Resolution
Dec 08, 2023We present CorPipe, the winning entry to the CRAC 2023 Shared Task on Multilingual Coreference Resolution. Our system is an improved version of our earlier multilingual coreference pipeline, and it surpasses other participants by a large margin of 4.5 percent points. CorPipe first performs mention detection, followed by coreference linking via an antecedent-maximization approach on the retrieved spans. Both tasks are trained jointly on all available corpora using a shared pretrained language model. Our main improvements comprise inputs larger than 512 subwords and changing the mention decoding to support ensembling. The source code is available at https://github.com/ufal/crac2023-corpipe.
Quality and Efficiency of Manual Annotation: Pre-annotation Bias
Jun 15, 2023This paper presents an analysis of annotation using an automatic pre-annotation for a mid-level annotation complexity task -- dependency syntax annotation. It compares the annotation efforts made by annotators using a pre-annotated version (with a high-accuracy parser) and those made by fully manual annotation. The aim of the experiment is to judge the final annotation quality when pre-annotation is used. In addition, it evaluates the effect of automatic linguistically-based (rule-formulated) checks and another annotation on the same data available to the annotators, and their influence on annotation quality and efficiency. The experiment confirmed that the pre-annotation is an efficient tool for faster manual syntactic annotation which increases the consistency of the resulting annotation without reducing its quality.