 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexing in 73 Languages: A Single Small Model for Multilingual Inflection
Oct 27, 2025We present a compact, single-model approach to multilingual inflection, the task of generating inflected word forms from base lemmas to express grammatical categories. Our model, trained jointly on data from 73 languages, is lightweight, robust to unseen words, and outperforms monolingual baselines in most languages. This demonstrates the effectiveness of multilingual modeling for inflection and highlights its practical benefits: simplifying deployment by eliminating the need to manage and retrain dozens of separate monolingual models. In addition to the standard SIGMORPHON shared task benchmarks, we evaluate our monolingual and multilingual models on 73 Universal Dependencies (UD) treebanks, extracting lemma-tag-form triples and their frequency counts. To ensure realistic data splits, we introduce a novel frequency-weighted, lemma-disjoint train-dev-test resampling procedure. Our work addresses the lack of an open-source, general-purpose, multilingual morphological inflection system capable of handling unseen words across a wide range of languages, including Czech. All code is publicly released at: https://github.com/tomsouri/multilingual-inflection.
* Published in the proceedings of TSD 2025. 12 pages, 1 figure, 4 tables
NameTag 3: A Tool and a Service for Multilingual/Multitagset NER
Jun 06, 2025



We introduce NameTag 3, an open-source tool and cloud-based web service for multilingual, multidataset, and multitagset named entity recognition (NER), supporting both flat and nested entities. NameTag 3 achieves state-of-the-art results on 21 test datasets in 15 languages and remains competitive on the rest, even against larger models. It is available as a command-line tool and as a cloud-based service, enabling use without local installation. NameTag 3 web service currently provides flat NER for 17 languages, trained on 21 corpora and three NE tagsets, all powered by a single 355M-parameter fine-tuned model; and nested NER for Czech, powered by a 126M fine-tuned model. The source code is licensed under open-source MPL 2.0, while the models are distributed under non-commercial CC BY-NC-SA 4.0. Documentation is available at https://ufal.mff.cuni.cz/nametag, source code at https://github.com/ufal/nametag3, and trained models via https://lindat.cz. The REST service and the web application can be found at https://lindat.mff.cuni.cz/services/nametag/. A demonstration video is available at https://www.youtube.com/watch?v=-gaGnP0IV8A.
Open-Source Web Service with Morphological Dictionary-Supplemented Deep Learning for Morphosyntactic Analysis of Czech
Jun 18, 2024We present an open-source web service for Czech morphosyntactic analysis. The system combines a deep learning model with rescoring by a high-precision morphological dictionary at inference time. We show that our hybrid method surpasses two competitive baselines: While the deep learning model ensures generalization for out-of-vocabulary words and better disambiguation, an improvement over an existing morphological analyser MorphoDiTa, at the same time, the deep learning model benefits from inference-time guidance of a manually curated morphological dictionary. We achieve 50% error reduction in lemmatization and 58% error reduction in POS tagging over MorphoDiTa, while also offering dependency parsing. The model is trained on one of the currently largest Czech morphosyntactic corpora, the PDT-C 1.0, with the trained models available at https://hdl.handle.net/11234/1-5293. We provide the tool as a web service deployed at https://lindat.mff.cuni.cz/services/udpipe/. The source code is available at GitHub (https://github.com/ufal/udpipe/tree/udpipe-2), along with a Python client for a simple use. The documentation for the models can be found at https://ufal.mff.cuni.cz/udpipe/2/models#czech_pdtc1.0_model.
CWRCzech: 100M Query-Document Czech Click Dataset and Its Application to Web Relevance Ranking
May 31, 2024We present CWRCzech, Click Web Ranking dataset for Czech, a 100M query-document Czech click dataset for relevance ranking with user behavior data collected from search engine logs of Seznam.cz. To the best of our knowledge, CWRCzech is the largest click dataset with raw text published so far. It provides document positions in the search results as well as information about user behavior: 27.6M clicked documents and 10.8M dwell times. In addition, we also publish a manually annotated Czech test for the relevance task, containing nearly 50k query-document pairs, each annotated by at least 2 annotators. Finally, we analyze how the user behavior data improve relevance ranking and show that models trained on data automatically harnessed at sufficient scale can surpass the performance of models trained on human annotated data. CWRCzech is published under an academic non-commercial license and is available to the research community at https://github.com/seznam/CWRCzech.
OOVs in the Spotlight: How to Inflect them?
Apr 13, 2024We focus on morphological inflection in out-of-vocabulary (OOV) conditions, an under-researched subtask in which state-of-the-art systems usually are less effective. We developed three systems: a retrograde model and two sequence-to-sequence (seq2seq) models based on LSTM and Transformer. For testing in OOV conditions, we automatically extracted a large dataset of nouns in the morphologically rich Czech language, with lemma-disjoint data splits, and we further manually annotated a real-world OOV dataset of neologisms. In the standard OOV conditions, Transformer achieves the best results, with increasing performance in ensemble with LSTM, the retrograde model and SIGMORPHON baselines. On the real-world OOV dataset of neologisms, the retrograde model outperforms all neural models. Finally, our seq2seq models achieve state-of-the-art results in 9 out of 16 languages from SIGMORPHON 2022 shared task data in the OOV evaluation (feature overlap) in the large data condition. We release the Czech OOV Inflection Dataset for rigorous evaluation in OOV conditions. Further, we release the inflection system with the seq2seq models as a ready-to-use Python library.
ÚFAL LatinPipe at EvaLatin 2024: Morphosyntactic Analysis of Latin
Apr 08, 2024



We present LatinPipe, the winning submission to the EvaLatin 2024 Dependency Parsing shared task. Our system consists of a fine-tuned concatenation of base and large pre-trained LMs, with a dot-product attention head for parsing and softmax classification heads for morphology to jointly learn both dependency parsing and morphological analysis. It is trained by sampling from seven publicly available Latin corpora, utilizing additional harmonization of annotations to achieve a more unified annotation style. Before fine-tuning, we train the system for a few initial epochs with frozen weights. We also add additional local relative contextualization by stacking the BiLSTM layers on top of the Transformer(s). Finally, we ensemble output probability distributions from seven randomly instantiated networks for the final submission. The code is available at https://github.com/ufal/evalatin2024-latinpipe.
Extending an Event-type Ontology: Adding Verbs and Classes Using Fine-tuned LLMs Suggestions
Jun 03, 2023In this project, we have investigated the use of advanced machine learning methods, specifically fine-tuned large language models, for pre-annotating data for a lexical extension task, namely adding descriptive words (verbs) to an existing (but incomplete, as of yet) ontology of event types. Several research questions have been focused on, from the investigation of a possible heuristics to provide at least hints to annotators which verbs to include and which are outside the current version of the ontology, to the possible use of the automatic scores to help the annotators to be more efficient in finding a threshold for identifying verbs that cannot be assigned to any existing class and therefore they are to be used as seeds for a new class. We have also carefully examined the correlation of the automatic scores with the human annotation. While the correlation turned out to be strong, its influence on the annotation proper is modest due to its near linearity, even though the mere fact of such pre-annotation leads to relatively short annotation times.
ÚFAL CorPipe at CRAC 2022: Effectivity of Multilingual Models for Coreference Resolution
Sep 15, 2022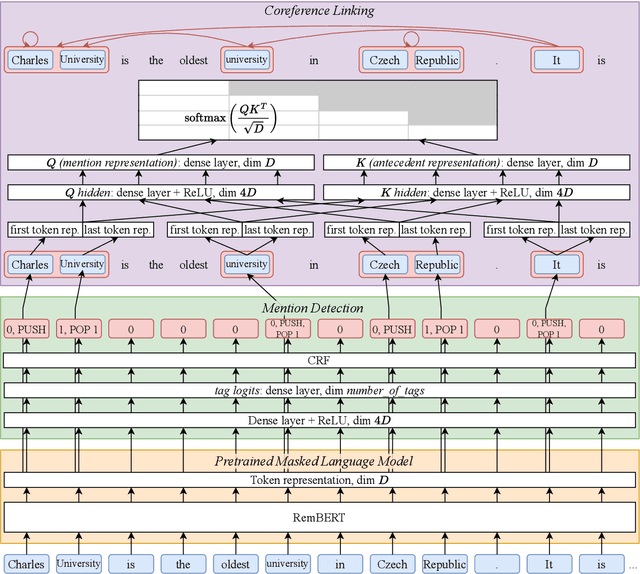
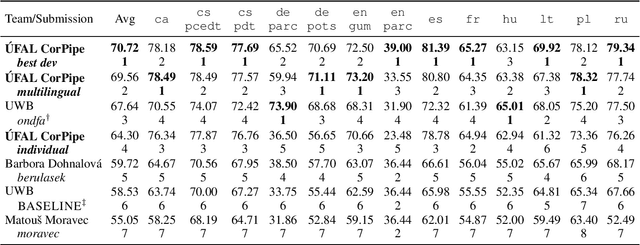
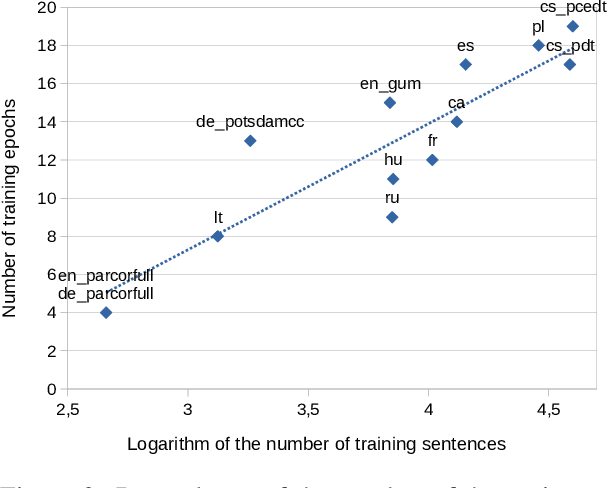

We describe the winning submission to the CRAC 2022 Shared Task on Multilingual Coreference Resolution. Our system first solves mention detection and then coreference linking on the retrieved spans with an antecedent-maximization approach, and both tasks are fine-tuned jointly with shared Transformer weights. We report results of fine-tuning a wide range of pretrained models. The center of this contribution are fine-tuned multilingual models. We found one large multilingual model with sufficiently large encoder to increase performance on all datasets across the board, with the benefit not limited only to the underrepresented languages or groups of typologically relative languages. The source code is available at https://github.com/ufal/crac2022-corpipe.
Czech Grammar Error Correction with a Large and Diverse Corpus
Jan 14, 2022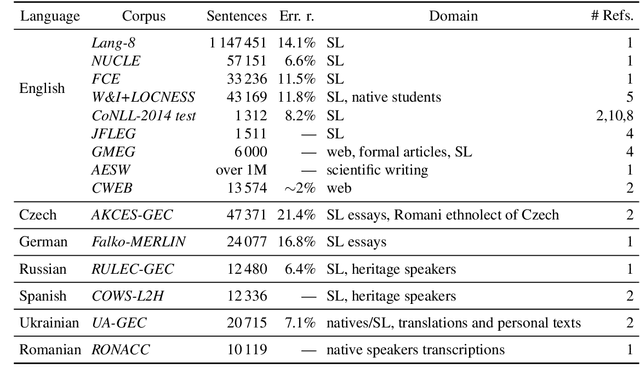
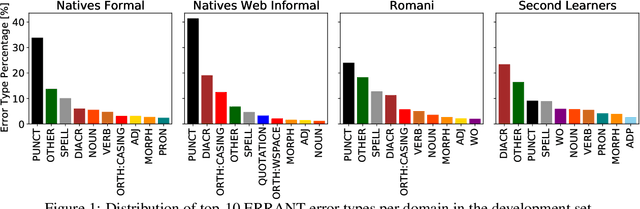
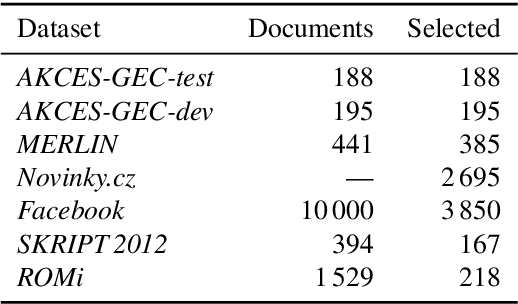
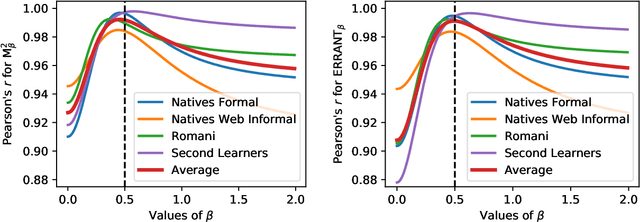
We introduce a large and diverse Czech corpus annotated for grammatical error correction (GEC) with the aim to contribute to the still scarce data resources in this domain for languages other than English. The Grammar Error Correction Corpus for Czech (GECCC) offers a variety of four domains, covering error distributions ranging from high error density essays written by non-native speakers, to website texts, where errors are expected to be much less common. We compare several Czech GEC systems, including several Transformer-based ones, setting a strong baseline to future research. Finally, we meta-evaluate common GEC metrics against human judgements on our data. We make the new Czech GEC corpus publicly available under the CC BY-SA 4.0 license at http://hdl.handle.net/11234/1-4639 .
Character Transformations for Non-Autoregressive GEC Tagging
Nov 17, 2021
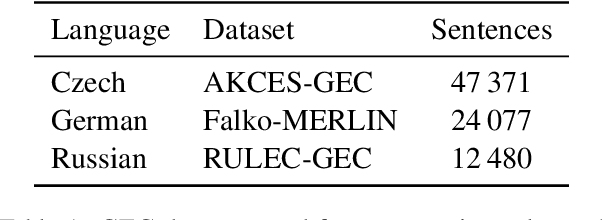
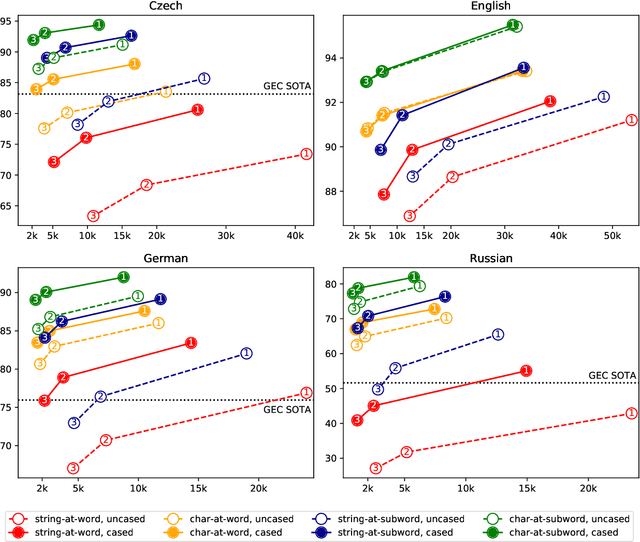

We propose a character-based nonautoregressive GEC approach, with automatically generated character transformations. Recently, per-word classification of correction edits has proven an efficient, parallelizable alternative to current encoder-decoder GEC systems. We show that word replacement edits may be suboptimal and lead to explosion of rules for spelling, diacritization and errors in morphologically rich languages, and propose a method for generating character transformations from GEC corpus. Finally, we train character transformation models for Czech, German and Russian, reaching solid results and dramatic speedup compared to autoregressive systems. The source code is released at https://github.com/ufal/wnut2021_character_transformations_gec.