 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWRCzech: 100M Query-Document Czech Click Dataset and Its Application to Web Relevance Ranking
May 31, 2024We present CWRCzech, Click Web Ranking dataset for Czech, a 100M query-document Czech click dataset for relevance ranking with user behavior data collected from search engine logs of Seznam.cz. To the best of our knowledge, CWRCzech is the largest click dataset with raw text published so far. It provides document positions in the search results as well as information about user behavior: 27.6M clicked documents and 10.8M dwell times. In addition, we also publish a manually annotated Czech test for the relevance task, containing nearly 50k query-document pairs, each annotated by at least 2 annotators. Finally, we analyze how the user behavior data improve relevance ranking and show that models trained on data automatically harnessed at sufficient scale can surpass the performance of models trained on human annotated data. CWRCzech is published under an academic non-commercial license and is available to the research community at https://github.com/seznam/CWRCzech.
Some Like It Small: Czech Semantic Embedding Models for Industry Applications
Nov 23, 2023This article focuses on the development and evaluation of Small-sized Czech sentence embedding models. Small models are important components for real-time industry applications in resource-constrained environments. Given the limited availability of labeled Czech data, alternative approaches, including pre-training, knowledge distillation, and unsupervised contrastive fine-tuning, are investigated. Comprehensive intrinsic and extrinsic analyses are conducted, showcasing the competitive performance of our models compared to significantly larger counterparts, with approximately 8 times smaller size and 5 times faster speed than conventional Base-sized models. To promote cooperation and reproducibility, both the models and the evaluation pipeline are made publicly accessible. Ultimately, this article presents practical applications of the developed sentence embedding models in Seznam.cz, the Czech search engine. These models have effectively replaced previous counterparts, enhancing the overall search experience for instance, in organic search, featured snippets, and image search. This transition has yielded improved performance.
Czech Grammar Error Correction with a Large and Diverse Corpus
Jan 14, 2022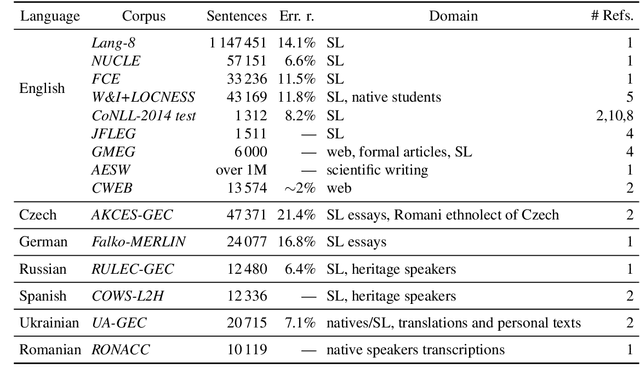
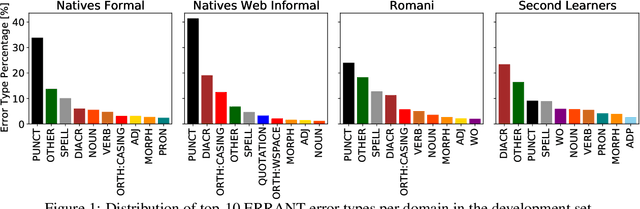
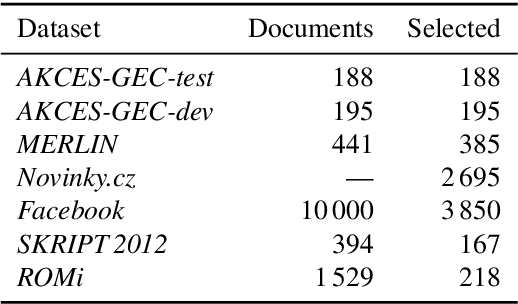
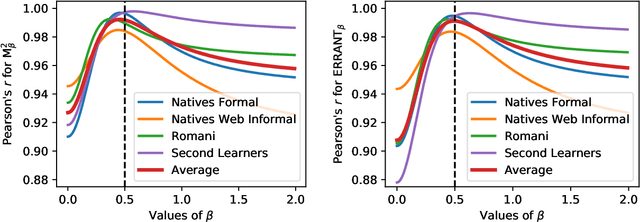
We introduce a large and diverse Czech corpus annotated for grammatical error correction (GEC) with the aim to contribute to the still scarce data resources in this domain for languages other than English. The Grammar Error Correction Corpus for Czech (GECCC) offers a variety of four domains, covering error distributions ranging from high error density essays written by non-native speakers, to website texts, where errors are expected to be much less common. We compare several Czech GEC systems, including several Transformer-based ones, setting a strong baseline to future research. Finally, we meta-evaluate common GEC metrics against human judgements on our data. We make the new Czech GEC corpus publicly available under the CC BY-SA 4.0 license at http://hdl.handle.net/11234/1-4639 .
Siamese BERT-based Model for Web Search Relevance Ranking Evaluated on a New Czech Dataset
Dec 03, 2021


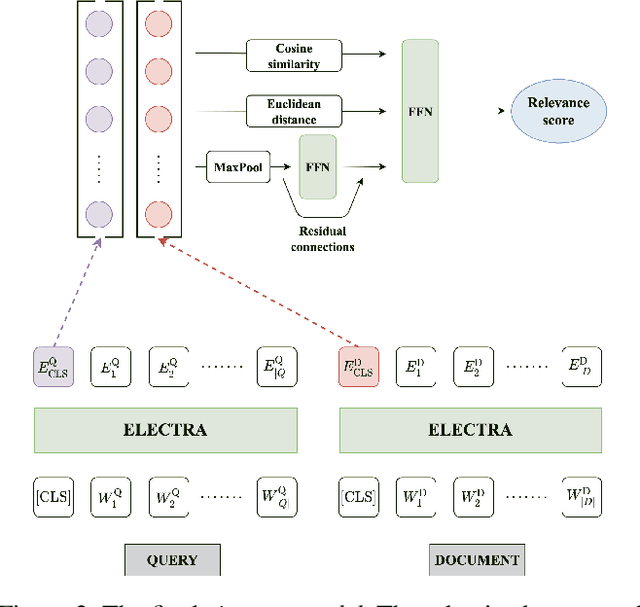
Web search engines focus on serving highly relevant results within hundreds of milliseconds. Pre-trained language transformer models such as BERT are therefore hard to use in this scenario due to their high computational demands. We present our real-time approach to the document ranking problem leveraging a BERT-based siamese architecture. The model is already deployed in a commercial search engine and it improves production performance by more than 3%. For further research and evaluation, we release DaReCzech, a unique data set of 1.6 million Czech user query-document pairs with manually assigned relevance levels. We also release Small-E-Czech, an Electra-small language model pre-trained on a large Czech corpus. We believe this data will support endeavours both of search relevance and multilingual-focused research communities.
Character Transformations for Non-Autoregressive GEC Tagging
Nov 17, 2021
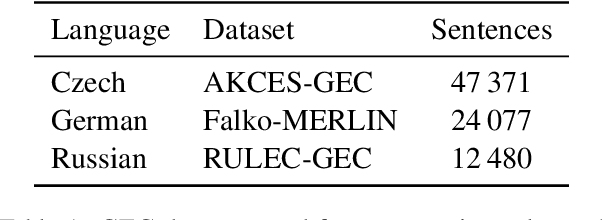
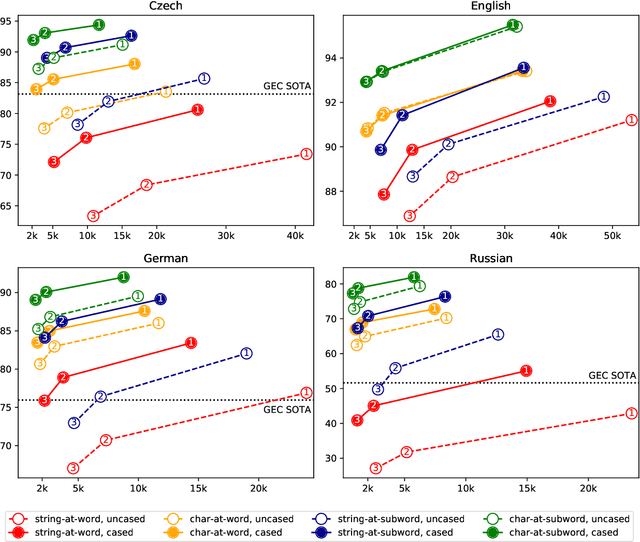

We propose a character-based nonautoregressive GEC approach, with automatically generated character transformations. Recently, per-word classification of correction edits has proven an efficient, parallelizable alternative to current encoder-decoder GEC systems. We show that word replacement edits may be suboptimal and lead to explosion of rules for spelling, diacritization and errors in morphologically rich languages, and propose a method for generating character transformations from GEC corpus. Finally, we train character transformation models for Czech, German and Russian, reaching solid results and dramatic speedup compared to autoregressive systems. The source code is released at https://github.com/ufal/wnut2021_character_transformations_gec.
Understanding Model Robustness to User-generated Noisy Texts
Oct 14, 2021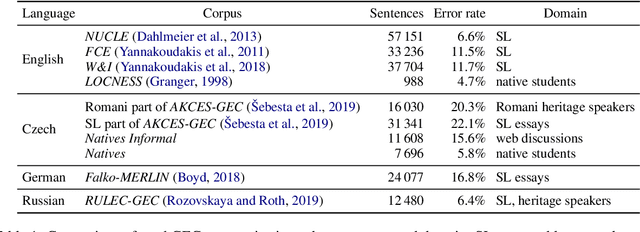

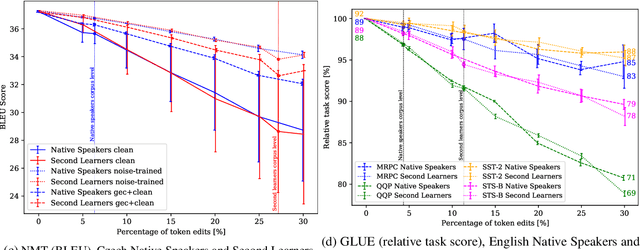
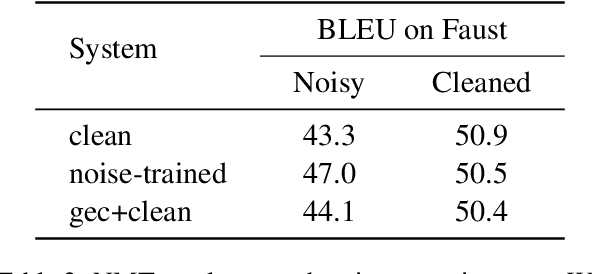
Sensitivity of deep-neural models to input noise is known to be a challenging problem. In NLP, model performance often deteriorates with naturally occurring noise, such as spelling errors. To mitigate this issue, models may leverage artificially noised data. However, the amount and type of generated noise has so far been determined arbitrarily. We therefore propose to model the errors statistically from grammatical-error-correction corpora. We present a thorough evaluation of several state-of-the-art NLP systems' robustness in multiple languages, with tasks including morpho-syntactic analysis, named entity recognition, neural machine translation, a subset of the GLUE benchmark and reading comprehension. We also compare two approaches to address the performance drop: a) training the NLP models with noised data generated by our framework; and b) reducing the input noise with external system for natural language correction. The code is released at https://github.com/ufal/kazitext.
Diacritics Restoration using BERT with Analysis on Czech language
May 24, 2021



We propose a new architecture for diacritics restoration based on contextualized embeddings, namely BERT, and we evaluate it on 12 languages with diacritics. Furthermore, we conduct a detailed error analysis on Czech, a morphologically rich language with a high level of diacritization. Notably, we manually annotate all mispredictions, showing that roughly 44% of them are actually not errors, but either plausible variants (19%), or the system corrections of erroneous data (25%). Finally, we categorize the real errors in detail. We release the code at https://github.com/ufal/bert-diacritics-restoration.
RobeCzech: Czech RoBERTa, a monolingual contextualized language representation model
May 24, 2021



We present RobeCzech, a monolingual RoBERTa language representation model trained on Czech data. RoBERTa is a robustly optimized Transformer-based pretraining approach. We show that RobeCzech considerably outperforms equally-sized multilingual and Czech-trained contextualized language representation models, surpasses current state of the art in all five evaluated NLP tasks and reaches state-of-theart results in four of them. The RobeCzech model is released publicly at https://hdl.handle.net/11234/1-3691 and https://huggingface.co/ufal/robeczech-base.
Grammatical Error Correction in Low-Resource Scenarios
Oct 16, 2019



Grammatical error correction in English is a long studied problem with many existing systems and datasets. However, there has been only a limited research on error correction of other languages. In this paper, we present a new dataset AKCES-GEC on grammatical error correction for Czech. We then make experiments on Czech, German and Russian and show that when utilizing synthetic parallel corpus, Transformer neural machine translation model can reach new state-of-the-art results on these datasets. AKCES-GEC is published under CC BY-NC-SA 4.0 license at https://hdl.handle.net/11234/1-3057 and the source code of the GEC model is available at https://github.com/ufal/low-resource-gec-wnut2019.
CUNI System for the Building Educational Applications 2019 Shared Task: Grammatical Error Correction
Sep 12, 2019

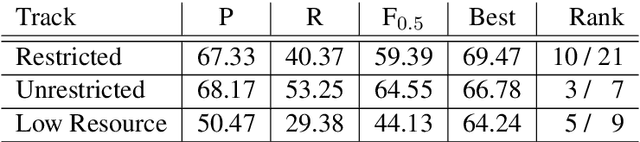

In this paper, we describe our systems submitted to the Building Educational Applications (BEA) 2019 Shared Task (Bryant et al., 2019). We participated in all three tracks. Our models are NMT systems based on the Transformer model, which we improve by incorporating several enhancements: applying dropout to whole source and target words, weighting target subwords, averaging model checkpoints, and using the trained model iteratively for correcting the intermediate translations. The system in the Restricted Track is trained on the provided corpora with oversampled "cleaner" sentences and reaches 59.39 F0.5 score on the test set. The system in the Low-Resource Track is trained from Wikipedia revision histories and reaches 44.13 F0.5 score. Finally, we finetune the system from the Low-Resource Track on restricted data and achieve 64.55 F0.5 score, placing third in the Unrestricted Track.