 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


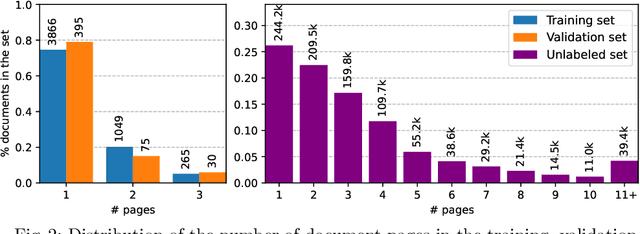
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
Siamese BERT-based Model for Web Search Relevance Ranking Evaluated on a New Czech Dataset
Dec 03, 2021


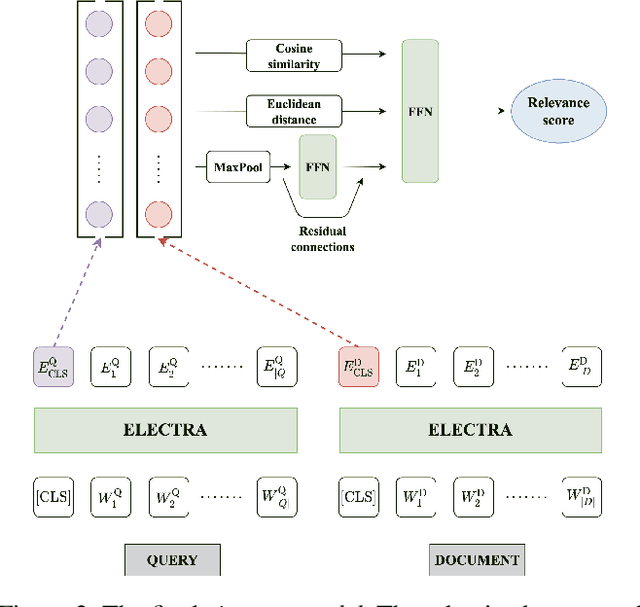
Web search engines focus on serving highly relevant results within hundreds of milliseconds. Pre-trained language transformer models such as BERT are therefore hard to use in this scenario due to their high computational demands. We present our real-time approach to the document ranking problem leveraging a BERT-based siamese architecture. The model is already deployed in a commercial search engine and it improves production performance by more than 3%. For further research and evaluation, we release DaReCzech, a unique data set of 1.6 million Czech user query-document pairs with manually assigned relevance levels. We also release Small-E-Czech, an Electra-small language model pre-trained on a large Czech corpus. We believe this data will support endeavours both of search relevance and multilingual-focused research communities.