 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023


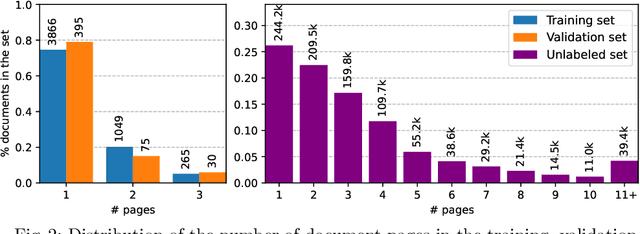
This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
Business Document Information Extraction: Towards Practical Benchmarks
Jun 20, 2022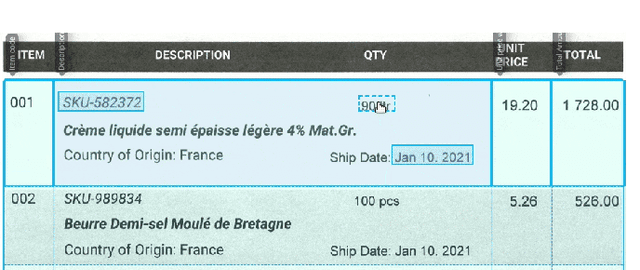
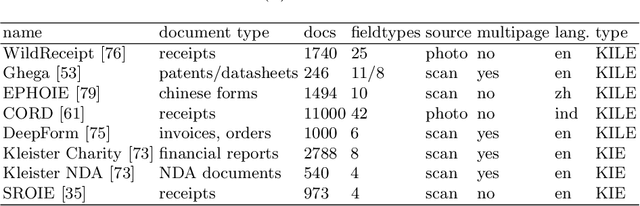
Information extraction from semi-structured documents is crucial for frictionless business-to-business (B2B) communication. While machine learning problems related to Document Information Extraction (IE) have been studied for decades, many common problem definitions and benchmarks do not reflect domain-specific aspects and practical needs for automating B2B document communication. We review the landscape of Document IE problems, datasets and benchmarks. We highlight the practical aspects missing in the common definitions and define the Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) problems. There is a lack of relevant datasets and benchmarks for Document IE on semi-structured business documents as their content is typically legally protected or sensitive. We discuss potential sources of available documents including synthetic data.
Artificial Dummies for Urban Dataset Augmentation
Dec 15, 2020
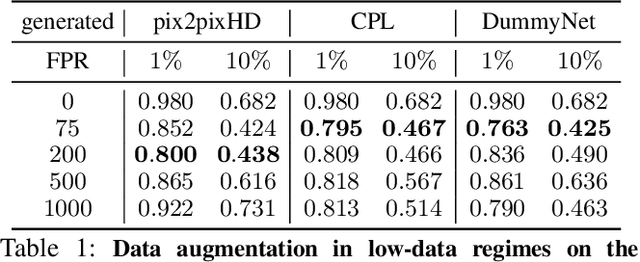
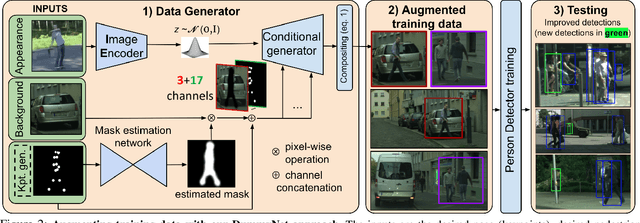
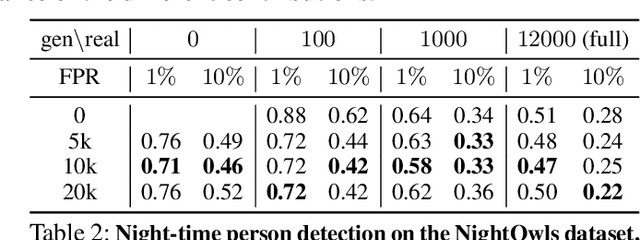
Existing datasets for training pedestrian detectors in images suffer from limited appearance and pose variation. The most challenging scenarios are rarely included because they are too difficult to capture due to safety reasons, or they are very unlikely to happen. The strict safety requirements in assisted and autonomous driving applications call for an extra high detection accuracy also in these rare situations. Having the ability to generate people images in arbitrary poses, with arbitrary appearances and embedded in different background scenes with varying illumination and weather conditions, is a crucial component for the development and testing of such applications. The contributions of this paper are three-fold. First, we describe an augmentation method for controlled synthesis of urban scenes containing people, thus producing rare or never-seen situations. This is achieved with a data generator (called DummyNet) with disentangled control of the pose, the appearance, and the target background scene. Second, the proposed generator relies on novel network architecture and associated loss that takes into account the segmentation of the foreground person and its composition into the background scene. Finally, we demonstrate that the data generated by our DummyNet improve performance of several existing person detectors across various datasets as well as in challenging situations, such as night-time conditions, where only a limited amount of training data is available. In the setup with only day-time data available, we improve the night-time detector by $17\%$ log-average miss rate over the detector trained with the day-time data only.