 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
Supervised Anomaly Detection for Complex Industrial Images
May 08, 2024
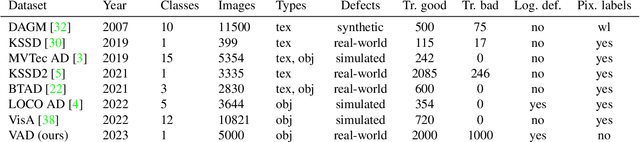

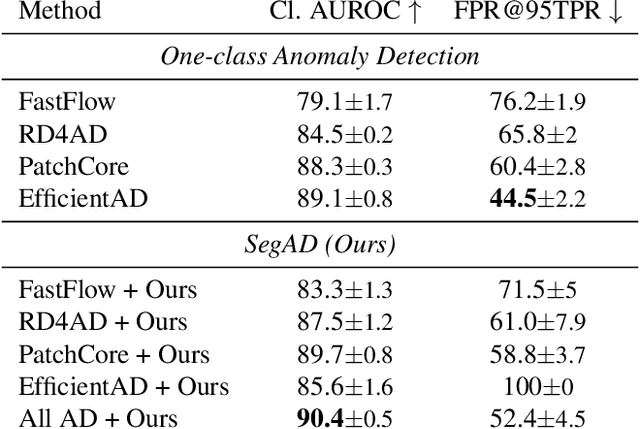
Automating visual inspection in industrial production lines is essential for increasing product quality across various industries. Anomaly detection (AD) methods serve as robust tools for this purpose. However, existing public datasets primarily consist of images without anomalies, limiting the practical application of AD methods in production settings. To address this challenge, we present (1) the Valeo Anomaly Dataset (VAD), a novel real-world industrial dataset comprising 5000 images, including 2000 instances of challenging real defects across more than 20 subclasses. Acknowledging that traditional AD methods struggle with this dataset, we introduce (2) Segmentation-based Anomaly Detector (SegAD). First, SegAD leverages anomaly maps as well as segmentation maps to compute local statistics. Next, SegAD uses these statistics and an optional supervised classifier score as input features for a Boosted Random Forest (BRF) classifier, yielding the final anomaly score. Our SegAD achieves state-of-the-art performance on both VAD (+2.1% AUROC) and the VisA dataset (+0.4% AUROC). The code and the models are publicly available.
Let It Flow: Simultaneous Optimization of 3D Flow and Object Clustering
Apr 12, 2024We study the problem of self-supervised 3D scene flow estimation from real large-scale raw point cloud sequences, which is crucial to various tasks like trajectory prediction or instance segmentation. In the absence of ground truth scene flow labels, contemporary approaches concentrate on deducing optimizing flow across sequential pairs of point clouds by incorporating structure based regularization on flow and object rigidity. The rigid objects are estimated by a variety of 3D spatial clustering methods. While state-of-the-art methods successfully capture overall scene motion using the Neural Prior structure, they encounter challenges in discerning multi-object motions. We identified the structural constraints and the use of large and strict rigid clusters as the main pitfall of the current approaches and we propose a novel clustering approach that allows for combination of overlapping soft clusters as well as non-overlapping rigid clusters representation. Flow is then jointly estimated with progressively growing non-overlapping rigid clusters together with fixed size overlapping soft clusters. We evaluate our method on multiple datasets with LiDAR point clouds, demonstrating the superior performance over the self-supervised baselines reaching new state of the art results. Our method especially excels in resolving flow in complicated dynamic scenes with multiple independently moving objects close to each other which includes pedestrians, cyclists and other vulnerable road users. Our codes will be publicly available.
POP-3D: Open-Vocabulary 3D Occupancy Prediction from Images
Jan 17, 2024



We describe an approach to predict open-vocabulary 3D semantic voxel occupancy map from input 2D images with the objective of enabling 3D grounding, segmentation and retrieval of free-form language queries. This is a challenging problem because of the 2D-3D ambiguity and the open-vocabulary nature of the target tasks, where obtaining annotated training data in 3D is difficult. The contributions of this work are three-fold. First, we design a new model architecture for open-vocabulary 3D semantic occupancy prediction. The architecture consists of a 2D-3D encoder together with occupancy prediction and 3D-language heads. The output is a dense voxel map of 3D grounded language embeddings enabling a range of open-vocabulary tasks. Second, we develop a tri-modal self-supervised learning algorithm that leverages three modalities: (i) images, (ii) language and (iii) LiDAR point clouds, and enables training the proposed architecture using a strong pre-trained vision-language model without the need for any 3D manual language annotations. Finally, we demonstrate quantitatively the strengths of the proposed model on several open-vocabulary tasks: Zero-shot 3D semantic segmentation using existing datasets; 3D grounding and retrieval of free-form language queries, using a small dataset that we propose as an extension of nuScenes. You can find the project page here https://vobecant.github.io/POP3D.
Regularizing Self-supervised 3D Scene Flows with Surface Awareness and Cyclic Consistency
Dec 12, 2023Learning without supervision how to predict 3D scene flows from point clouds is central to many vision systems. We propose a novel learning framework for this task which improves the necessary regularization. Relying on the assumption that scene elements are mostly rigid, current smoothness losses are built on the definition of ``rigid clusters" in the input point clouds. The definition of these clusters is challenging and has a major impact on the quality of predicted flows. We introduce two new consistency losses that enlarge clusters while preventing them from spreading over distinct objects. In particular, we enforce \emph{temporal} consistency with a forward-backward cyclic loss and \emph{spatial} consistency by considering surface orientation similarity in addition to spatial proximity. The proposed losses are model-independent and can thus be used in a plug-and-play fashion to significantly improve the performance of existing models, as demonstrated on two top-performing ones. We also showcase the effectiveness and generalization capability of our framework on four standard sensor-unique driving datasets, achieving state-of-the-art performance in 3D scene flow estimation. Our codes are available anonymously on \url{https://github.com/vacany/sac-flow}.
T-UDA: Temporal Unsupervised Domain Adaptation in Sequential Point Clouds
Sep 15, 2023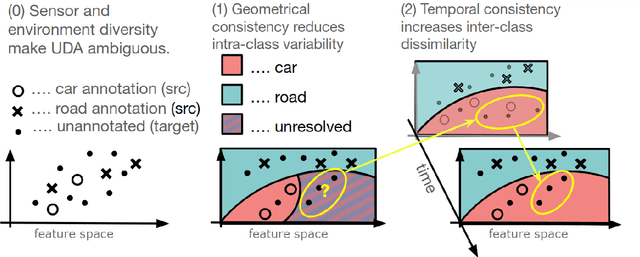
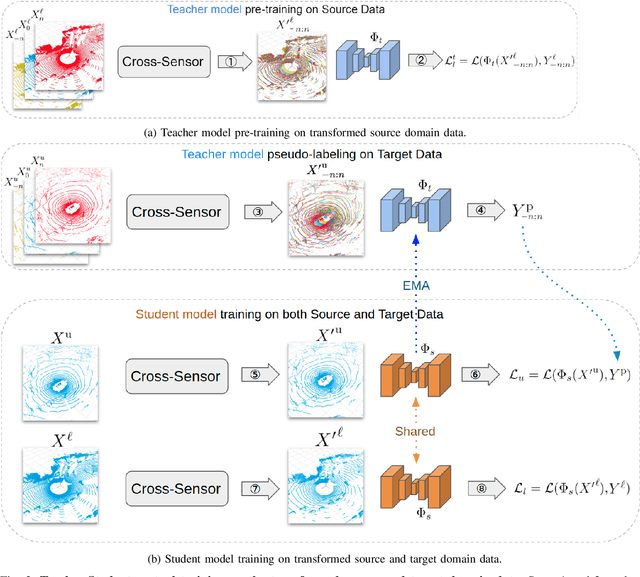
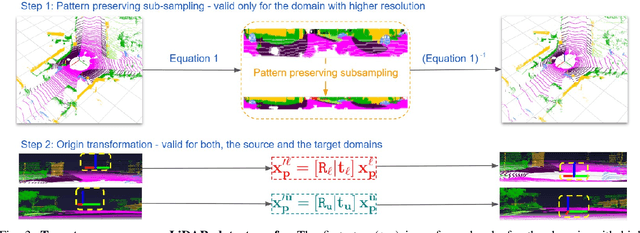
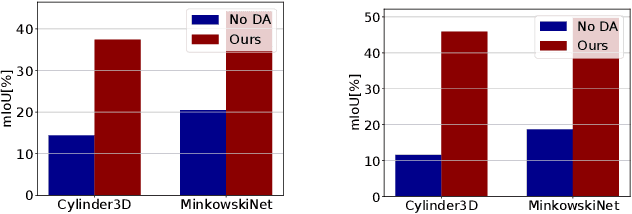
Deep perception models have to reliably cope with an open-world setting of domain shifts induced by different geographic regions, sensor properties, mounting positions, and several other reasons. Since covering all domains with annotated data is technically intractable due to the endless possible variations, researchers focus on unsupervised domain adaptation (UDA) methods that adapt models trained on one (source) domain with annotations available to another (target) domain for which only unannotated data are available. Current predominant methods either leverage semi-supervised approaches, e.g., teacher-student setup, or exploit privileged data, such as other sensor modalities or temporal data consistency. We introduce a novel domain adaptation method that leverages the best of both trends. Our approach combines input data's temporal and cross-sensor geometric consistency with the mean teacher method. Dubbed T-UDA for "temporal UDA", such a combination yields massive performance gains for the task of 3D semantic segmentation of driving scenes. Experiments are conducted on Waymo Open Dataset, nuScenes and SemanticKITTI, for two popular 3D point cloud architectures, Cylinder3D and MinkowskiNet. Our codes are publicly available at https://github.com/ctu-vras/T-UDA.
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022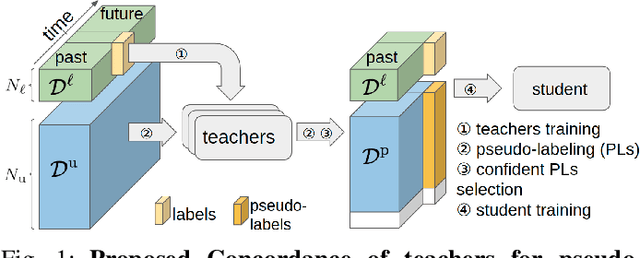

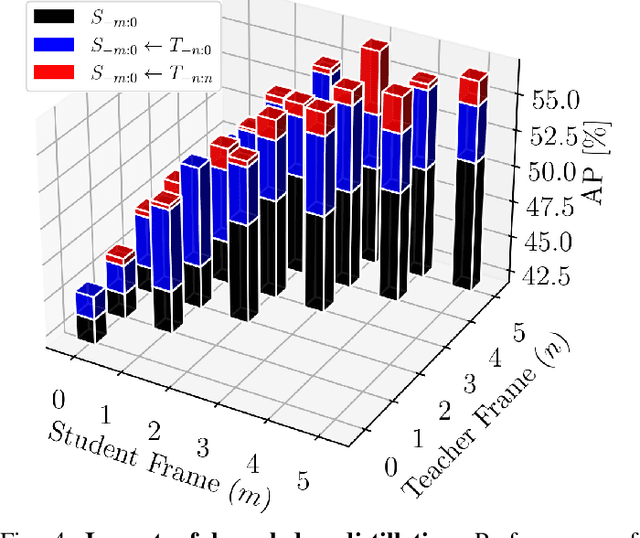
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022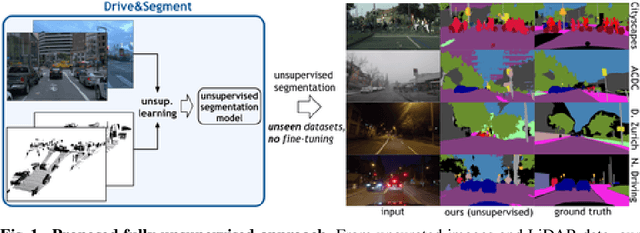
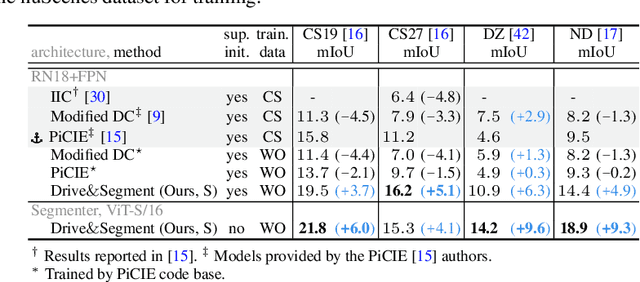
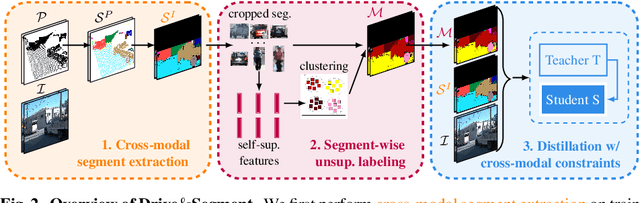
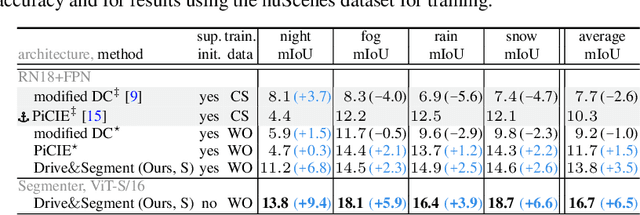
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
Artificial Dummies for Urban Dataset Augmentation
Dec 15, 2020
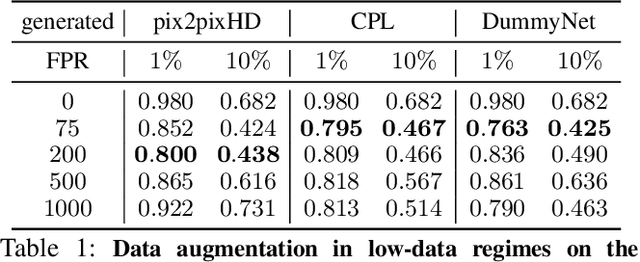
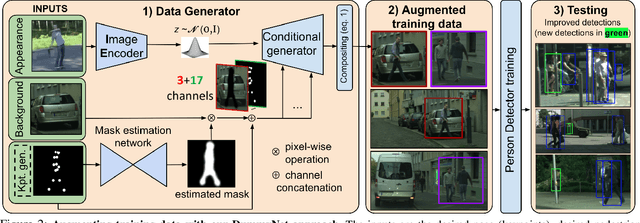
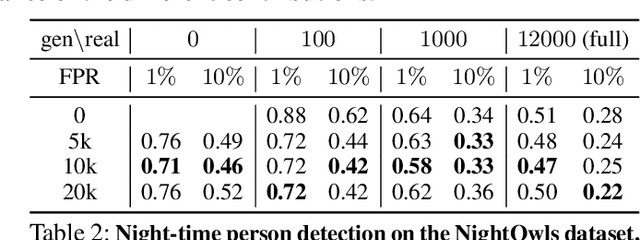
Existing datasets for training pedestrian detectors in images suffer from limited appearance and pose variation. The most challenging scenarios are rarely included because they are too difficult to capture due to safety reasons, or they are very unlikely to happen. The strict safety requirements in assisted and autonomous driving applications call for an extra high detection accuracy also in these rare situations. Having the ability to generate people images in arbitrary poses, with arbitrary appearances and embedded in different background scenes with varying illumination and weather conditions, is a crucial component for the development and testing of such applications. The contributions of this paper are three-fold. First, we describe an augmentation method for controlled synthesis of urban scenes containing people, thus producing rare or never-seen situations. This is achieved with a data generator (called DummyNet) with disentangled control of the pose, the appearance, and the target background scene. Second, the proposed generator relies on novel network architecture and associated loss that takes into account the segmentation of the foreground person and its composition into the background scene. Finally, we demonstrate that the data generated by our DummyNet improve performance of several existing person detectors across various datasets as well as in challenging situations, such as night-time conditions, where only a limited amount of training data is available. In the setup with only day-time data available, we improve the night-time detector by $17\%$ log-average miss rate over the detector trained with the day-time data only.
Yes, we GAN: Applying Adversarial Techniques for Autonomous Driving
Feb 09, 2019
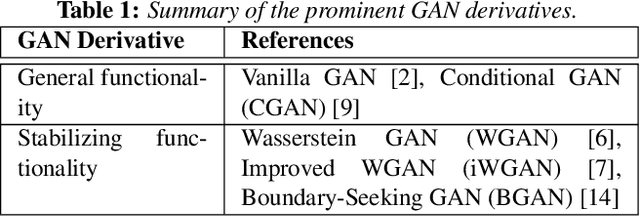
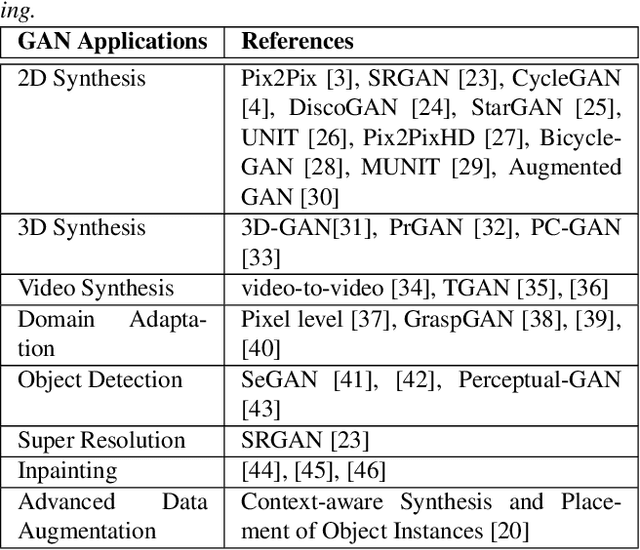
Generative Adversarial Networks (GAN) have gained a lot of popularity from their introduction in 2014 till present. Research on GAN is rapidly growing and there are many variants of the original GAN focusing on various aspects of deep learning. GAN are perceived as the most impactful direction of machine learning in the last decade. This paper focuses on the application of GAN in autonomous driving including topics such as advanced data augmentation, loss function learning, semi-supervised learning, etc. We formalize and review key applications of adversarial techniques and discuss challenges and open problems to be addressed.