 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Conditioning with Representation-Aligned Visual Features
Feb 03, 2026While representation alignment with self-supervised models has been shown to improve diffusion model training, its potential for enhancing inference-time conditioning remains largely unexplored. We introduce Representation-Aligned Guidance (REPA-G), a framework that leverages these aligned representations, with rich semantic properties, to enable test-time conditioning from features in generation. By optimizing a similarity objective (the potential) at inference, we steer the denoising process toward a conditioned representation extracted from a pre-trained feature extractor. Our method provides versatile control at multiple scales, ranging from fine-grained texture matching via single patches to broad semantic guidance using global image feature tokens. We further extend this to multi-concept composition, allowing for the faithful combination of distinct concepts. REPA-G operates entirely at inference time, offering a flexible and precise alternative to often ambiguous text prompts or coarse class labels. We theoretically justify how this guidance enables sampling from the potential-induced tilted distribution. Quantitative results on ImageNet and COCO demonstrate that our approach achieves high-quality, diverse generations. Code is available at https://github.com/valeoai/REPA-G.
Leveraging 3D Representation Alignment and RGB Pretrained Priors for LiDAR Scene Generation
Jan 12, 2026LiDAR scene synthesis is an emerging solution to scarcity in 3D data for robotic tasks such as autonomous driving. Recent approaches employ diffusion or flow matching models to generate realistic scenes, but 3D data remains limited compared to RGB datasets with millions of samples. We introduce R3DPA, the first LiDAR scene generation method to unlock image-pretrained priors for LiDAR point clouds, and leverage self-supervised 3D representations for state-of-the-art results. Specifically, we (i) align intermediate features of our generative model with self-supervised 3D features, which substantially improves generation quality; (ii) transfer knowledge from large-scale image-pretrained generative models to LiDAR generation, mitigating limited LiDAR datasets; and (iii) enable point cloud control at inference for object inpainting and scene mixing with solely an unconditional model. On the KITTI-360 benchmark R3DPA achieves state of the art performance. Code and pretrained models are available at https://github.com/valeoai/R3DPA.
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
Don't drop your samples! Coherence-aware training benefits Conditional diffusion
May 30, 2024



Conditional diffusion models are powerful generative models that can leverage various types of conditional information, such as class labels, segmentation masks, or text captions. However, in many real-world scenarios, conditional information may be noisy or unreliable due to human annotation errors or weak alignment. In this paper, we propose the Coherence-Aware Diffusion (CAD), a novel method that integrates coherence in conditional information into diffusion models, allowing them to learn from noisy annotations without discarding data. We assume that each data point has an associated coherence score that reflects the quality of the conditional information. We then condition the diffusion model on both the conditional information and the coherence score. In this way, the model learns to ignore or discount the conditioning when the coherence is low. We show that CAD is theoretically sound and empirically effective on various conditional generation tasks. Moreover, we show that leveraging coherence generates realistic and diverse samples that respect conditional information better than models trained on cleaned datasets where samples with low coherence have been discarded.
Supervised Anomaly Detection for Complex Industrial Images
May 08, 2024
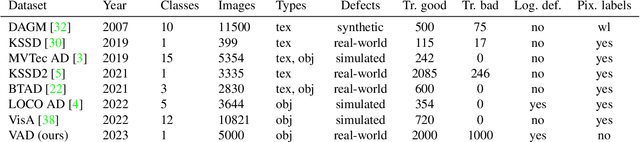

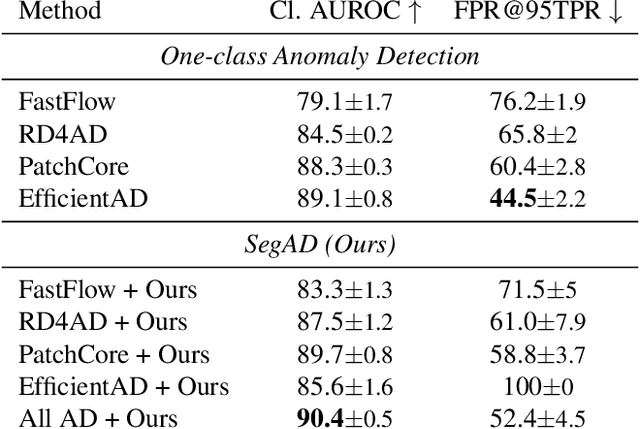
Automating visual inspection in industrial production lines is essential for increasing product quality across various industries. Anomaly detection (AD) methods serve as robust tools for this purpose. However, existing public datasets primarily consist of images without anomalies, limiting the practical application of AD methods in production settings. To address this challenge, we present (1) the Valeo Anomaly Dataset (VAD), a novel real-world industrial dataset comprising 5000 images, including 2000 instances of challenging real defects across more than 20 subclasses. Acknowledging that traditional AD methods struggle with this dataset, we introduce (2) Segmentation-based Anomaly Detector (SegAD). First, SegAD leverages anomaly maps as well as segmentation maps to compute local statistics. Next, SegAD uses these statistics and an optional supervised classifier score as input features for a Boosted Random Forest (BRF) classifier, yielding the final anomaly score. Our SegAD achieves state-of-the-art performance on both VAD (+2.1% AUROC) and the VisA dataset (+0.4% AUROC). The code and the models are publicly available.
A Pytorch Reproduction of Masked Generative Image Transformer
Oct 22, 2023



In this technical report, we present a reproduction of MaskGIT: Masked Generative Image Transformer, using PyTorch. The approach involves leveraging a masked bidirectional transformer architecture, enabling image generation with only few steps (8~16 steps) for 512 x 512 resolution images, i.e., ~64x faster than an auto-regressive approach. Through rigorous experimentation and optimization, we achieved results that closely align with the findings presented in the original paper. We match the reported FID of 7.32 with our replication and obtain 7.59 with similar hyperparameters on ImageNet at resolution 512 x 512. Moreover, we improve over the official implementation with some minor hyperparameter tweaking, achieving FID of 7.26. At the lower resolution of 256 x 256 pixels, our reimplementation scores 6.80, in comparison to the original paper's 6.18. To promote further research on Masked Generative Models and facilitate their reproducibility, we released our code and pre-trained weights openly at https://github.com/valeoai/MaskGIT-pytorch/
Instance-Aware Observer Network for Out-of-Distribution Object Segmentation
Jul 20, 2022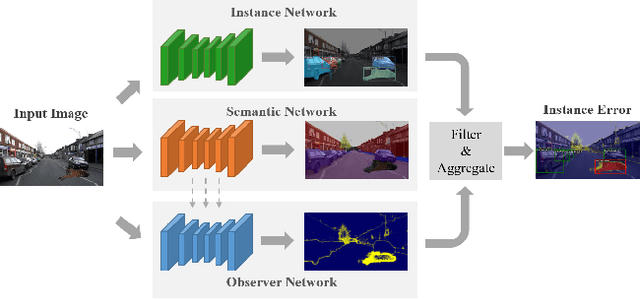
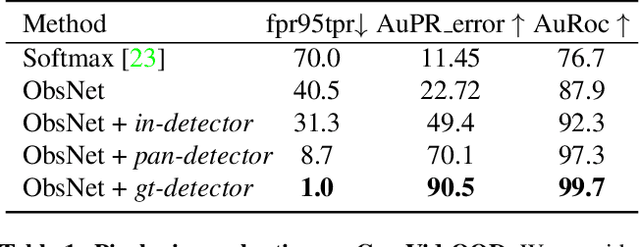

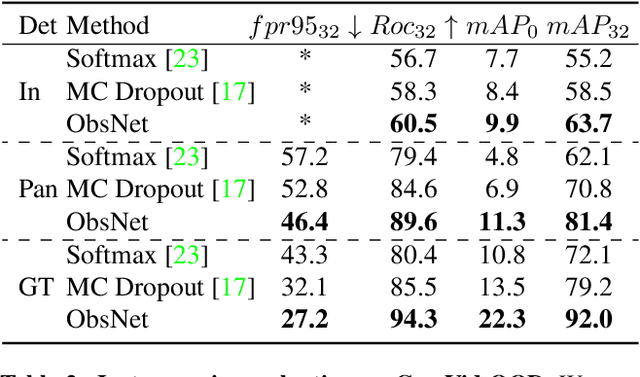
Recent work on Observer Network has shown promising results on Out-Of-Distribution (OOD) detection for semantic segmentation. These methods have difficulty in precisely locating the point of interest in the image, i.e, the anomaly. This limitation is due to the difficulty of fine-grained prediction at the pixel level. To address this issue, we provide instance knowledge to the observer. We extend the approach of ObsNet by harnessing an instance-wise mask prediction. We use an additional, class agnostic, object detector to filter and aggregate observer predictions. Finally, we predict an unique anomaly score for each instance in the image. We show that our proposed method accurately disentangle in-distribution objects from Out-Of-Distribution objects on three datasets.
Triggering Failures: Out-Of-Distribution detection by learning from local adversarial attacks in Semantic Segmentation
Aug 03, 2021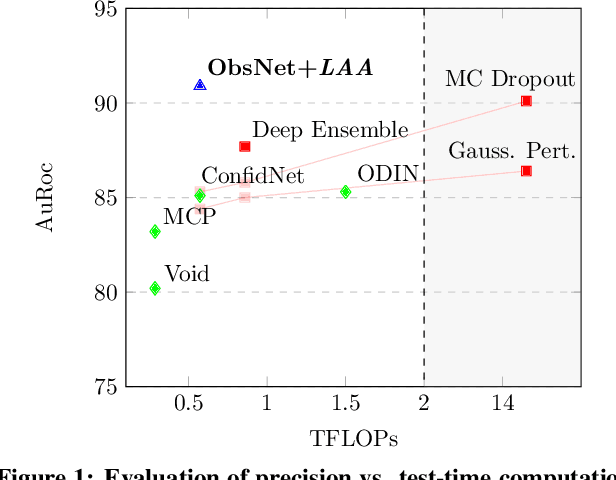

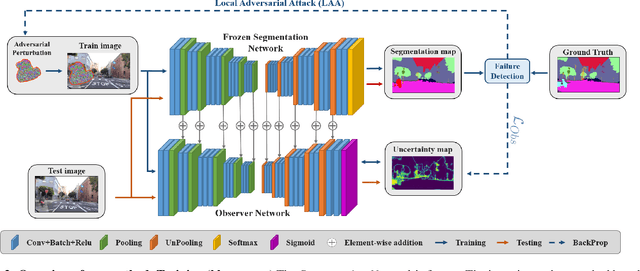
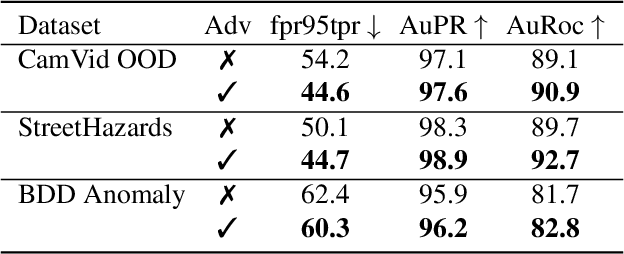
In this paper, we tackle the detection of out-of-distribution (OOD) objects in semantic segmentation. By analyzing the literature, we found that current methods are either accurate or fast but not both which limits their usability in real world applications. To get the best of both aspects, we propose to mitigate the common shortcomings by following four design principles: decoupling the OOD detection from the segmentation task, observing the entire segmentation network instead of just its output, generating training data for the OOD detector by leveraging blind spots in the segmentation network and focusing the generated data on localized regions in the image to simulate OOD objects. Our main contribution is a new OOD detection architecture called ObsNet associated with a dedicated training scheme based on Local Adversarial Attacks (LAA). We validate the soundness of our approach across numerous ablation studies. We also show it obtains top performances both in speed and accuracy when compared to ten recent methods of the literature on three different datasets.
Learning Uncertainty For Safety-Oriented Semantic Segmentation In Autonomous Driving
May 28, 2021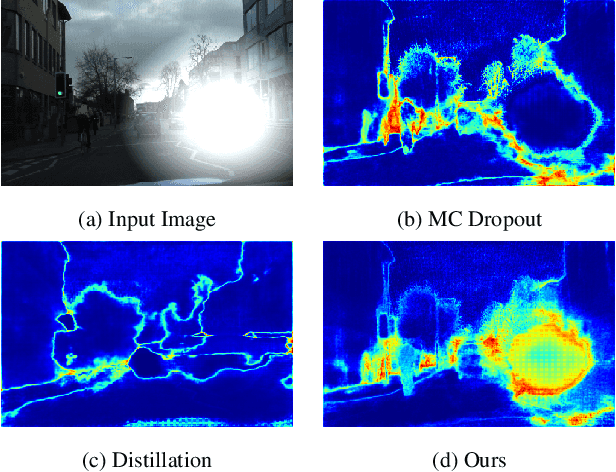

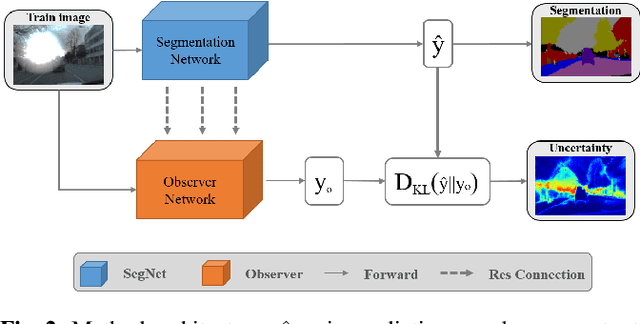

In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. We show experimentally that our proposed approach is much less computationally intensive at inference time than competing methods (e.g. MCDropout), while delivering better results on safety-oriented evaluation metrics on the CamVid dataset, especially in the case of glare artifacts.
This dataset does not exist: training models from generated images
Nov 07, 2019

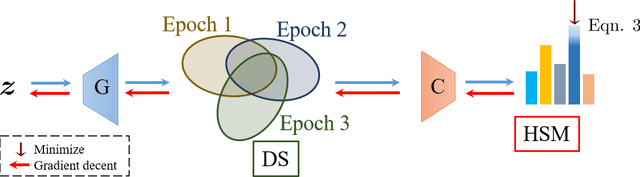

Current generative networks are increasingly proficient in generating high-resolution realistic images. These generative networks, especially the conditional ones, can potentially become a great tool for providing new image datasets. This naturally brings the question: Can we train a classifier only on the generated data? This potential availability of nearly unlimited amounts of training data challenges standard practices for training machine learning models, which have been crafted across the years for limited and fixed size datasets. In this work we investigate this question and its related challenges. We identify ways to improve significantly the performance over naive training on randomly generated images with regular heuristics. We propose three standalone techniques that can be applied at different stages of the pipeline, i.e., data generation, training on generated data, and deploying on real data. We evaluate our proposed approaches on a subset of the ImageNet dataset and show encouraging results compared to classifiers trained on real images.