 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSG0: Continual Urban Scene Generation with Zero Forgetting
Dec 06, 2021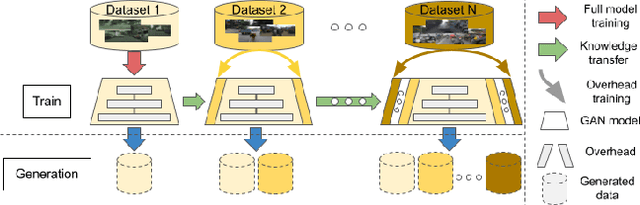
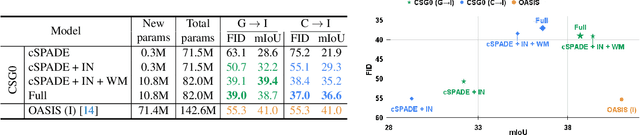
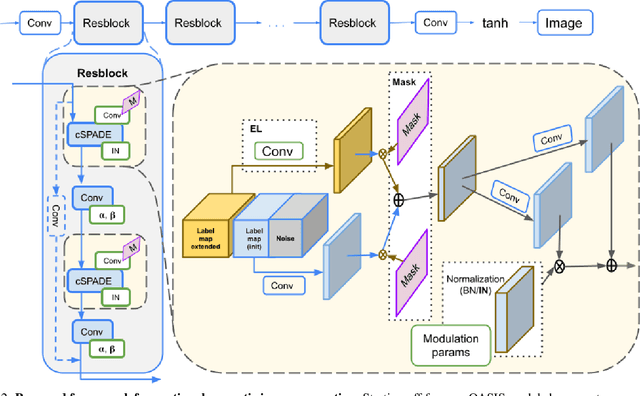
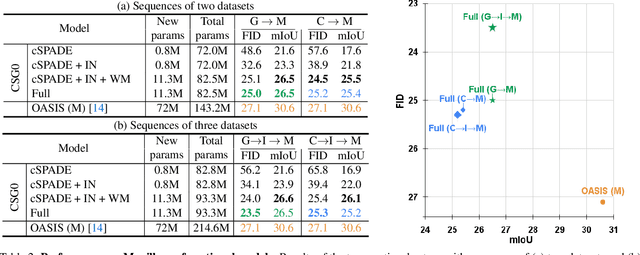
With the rapid advances in generative adversarial networks (GANs), the visual quality of synthesised scenes keeps improving, including for complex urban scenes with applications to automated driving. We address in this work a continual scene generation setup in which GANs are trained on a stream of distinct domains; ideally, the learned models should eventually be able to generate new scenes in all seen domains. This setup reflects the real-life scenario where data are continuously acquired in different places at different times. In such a continual setup, we aim for learning with zero forgetting, i.e., with no degradation in synthesis quality over earlier domains due to catastrophic forgetting. To this end, we introduce a novel framework that not only (i) enables seamless knowledge transfer in continual training but also (ii) guarantees zero forgetting with a small overhead cost. While being more memory efficient, thanks to continual learning, our model obtains better synthesis quality as compared against the brute-force solution that trains one full model for each domain. Especially, under extreme low-data regimes, our approach significantly outperforms the brute-force one by a large margin.
Semantic Palette: Guiding Scene Generation with Class Proportions
Jun 03, 2021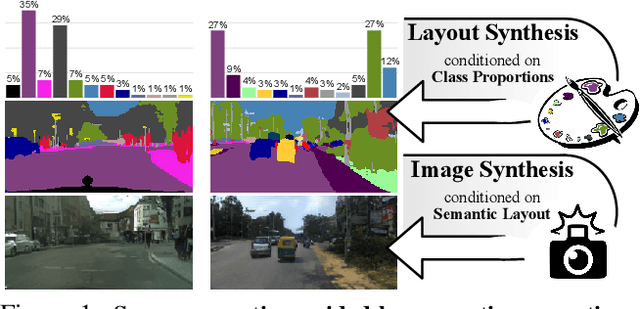
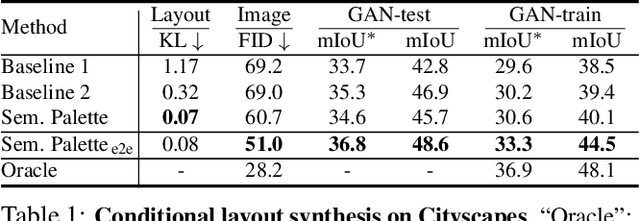
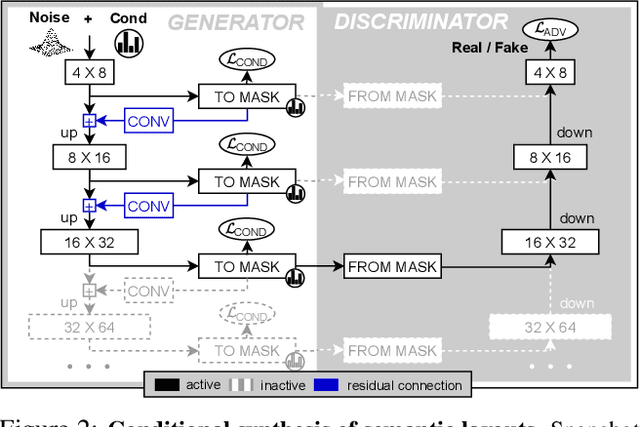
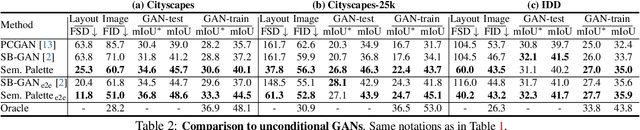
Despite the recent progress of generative adversarial networks (GANs) at synthesizing photo-realistic images, producing complex urban scenes remains a challenging problem. Previous works break down scene generation into two consecutive phases: unconditional semantic layout synthesis and image synthesis conditioned on layouts. In this work, we propose to condition layout generation as well for higher semantic control: given a vector of class proportions, we generate layouts with matching composition. To this end, we introduce a conditional framework with novel architecture designs and learning objectives, which effectively accommodates class proportions to guide the scene generation process. The proposed architecture also allows partial layout editing with interesting applications. Thanks to the semantic control, we can produce layouts close to the real distribution, helping enhance the whole scene generation process. On different metrics and urban scene benchmarks, our models outperform existing baselines. Moreover, we demonstrate the merit of our approach for data augmentation: semantic segmenters trained on real layout-image pairs along with additional ones generated by our approach outperform models only trained on real pairs.
QUEST: Quantized embedding space for transferring knowledge
Dec 03, 2019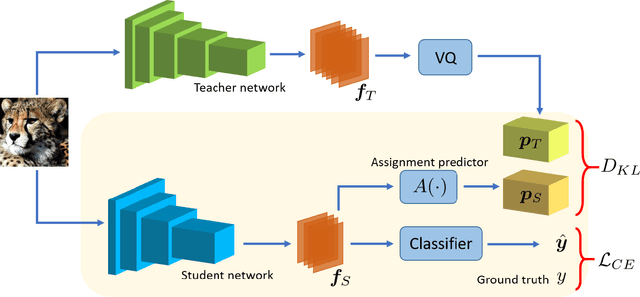

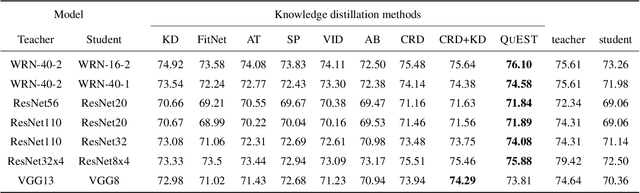
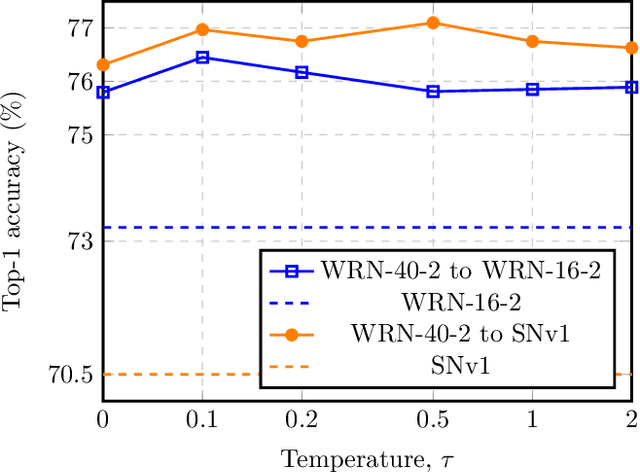
Knowledge distillation refers to the process of training a compact student network to achieve better accuracy by learning from a high capacity teacher network. Most of the existing knowledge distillation methods direct the student to follow the teacher by matching the teacher's output, feature maps or their distribution. In this work, we propose a novel way to achieve this goal: by distilling the knowledge through a quantized space. According to our method, the teacher's feature maps are quantized to represent the main visual concepts encompassed in the feature maps. The student is then asked to predict the quantized representation, which thus forms the task that the student uses to learn from the teacher. Despite its simplicity, we show that our approach is able to yield results that improve the state of the art on knowledge distillation. To that end, we provide an extensive evaluation across several network architectures and most commonly used benchmark datasets.
This dataset does not exist: training models from generated images
Nov 07, 2019

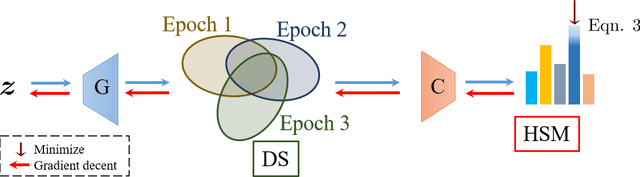

Current generative networks are increasingly proficient in generating high-resolution realistic images. These generative networks, especially the conditional ones, can potentially become a great tool for providing new image datasets. This naturally brings the question: Can we train a classifier only on the generated data? This potential availability of nearly unlimited amounts of training data challenges standard practices for training machine learning models, which have been crafted across the years for limited and fixed size datasets. In this work we investigate this question and its related challenges. We identify ways to improve significantly the performance over naive training on randomly generated images with regular heuristics. We propose three standalone techniques that can be applied at different stages of the pipeline, i.e., data generation, training on generated data, and deploying on real data. We evaluate our proposed approaches on a subset of the ImageNet dataset and show encouraging results compared to classifiers trained on real images.
DADA: Depth-aware Domain Adaptation in Semantic Segmentation
Apr 04, 2019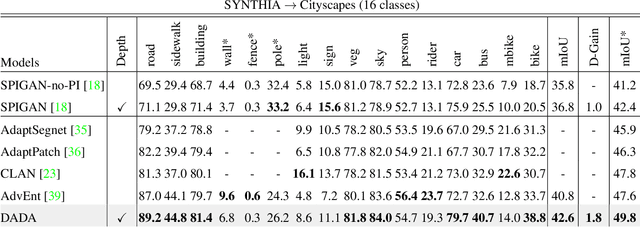
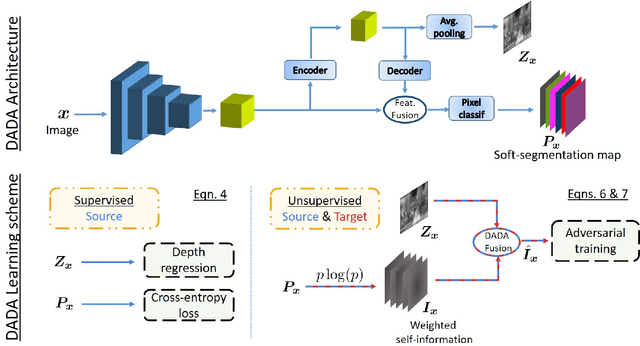
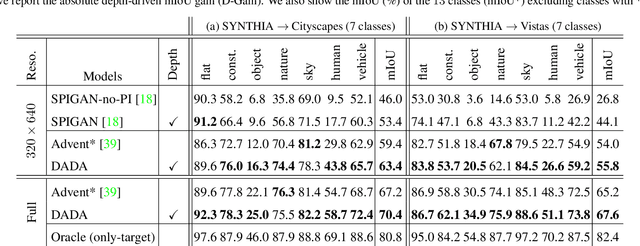

Unsupervised domain adaptation (UDA) is important for applications where large scale annotation of representative data is challenging. For semantic segmentation in particular, it helps deploy on real "target domain" data models that are trained on annotated images from a different "source domain", notably a virtual environment. To this end, most previous works consider semantic segmentation as the only mode of supervision for source domain data, while ignoring other, possibly available, information like depth. In this work, we aim at exploiting at best such a privileged information while training the UDA model. We propose a unified depth-aware UDA framework that leverages in several complementary ways the knowledge of dense depth in the source domain. As a result, the performance of the trained semantic segmentation model on the target domain is boosted. Our novel approach indeed achieves state-of-the-art performance on different challenging synthetic-2-real benchmarks.
ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
Nov 30, 2018

Semantic segmentation is a key problem for many computer vision tasks. While approaches based on convolutional neural networks constantly break new records on different benchmarks, generalizing well to diverse testing environments remains a major challenge. In numerous real world applications, there is indeed a large gap between data distributions in train and test domains, which results in severe performance loss at run-time. In this work, we address the task of unsupervised domain adaptation in semantic segmentation with losses based on the entropy of the pixel-wise predictions. To this end, we propose two novel, complementary methods using (i) entropy loss and (ii) adversarial loss respectively. We demonstrate state-of-the-art performance in semantic segmentation on two challenging "synthetic-2-real" set-ups and show that the approach can also be used for detection.
Learning a Complete Image Indexing Pipeline
Dec 12, 2017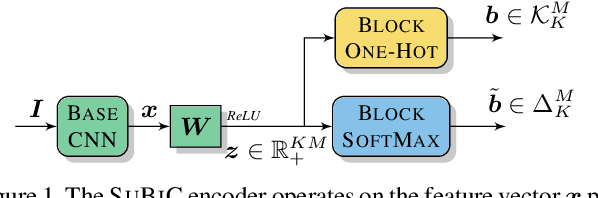

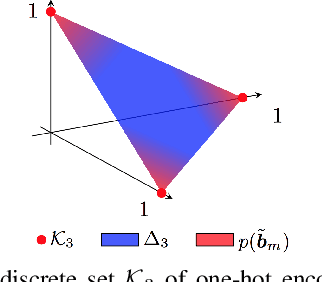
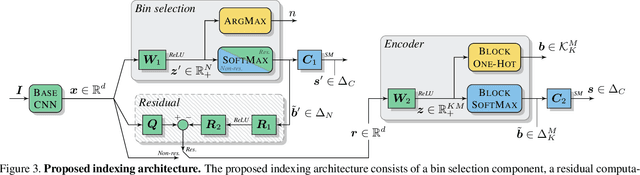
To work at scale, a complete image indexing system comprises two components: An inverted file index to restrict the actual search to only a subset that should contain most of the items relevant to the query; An approximate distance computation mechanism to rapidly scan these lists. While supervised deep learning has recently enabled improvements to the latter, the former continues to be based on unsupervised clustering in the literature. In this work, we propose a first system that learns both components within a unifying neural framework of structured binary encoding.
SUBIC: A supervised, structured binary code for image search
Aug 09, 2017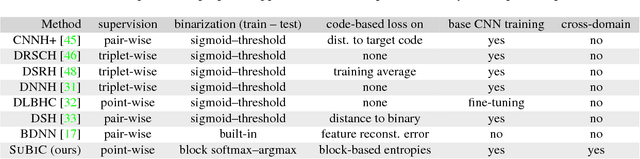
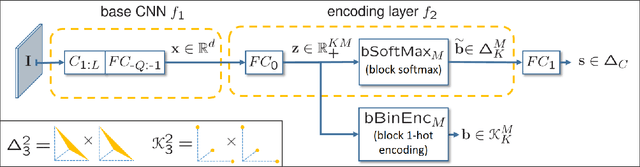
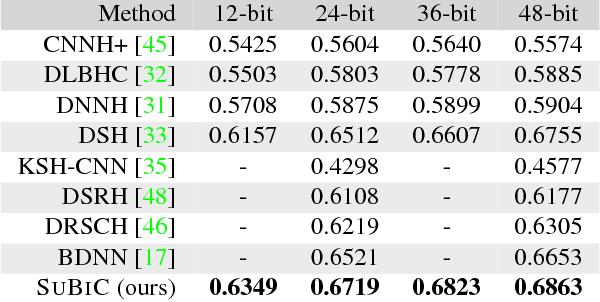
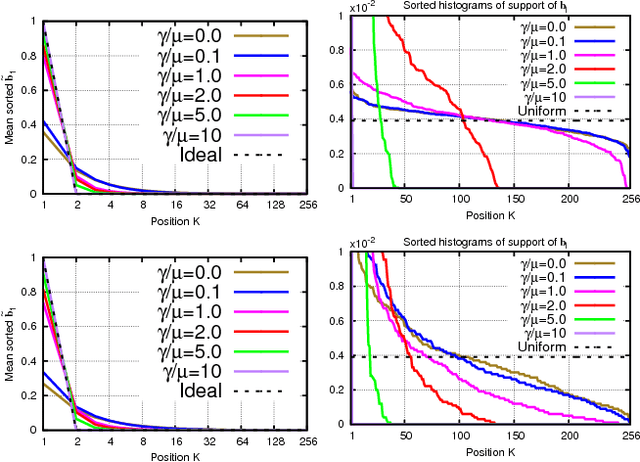
For large-scale visual search, highly compressed yet meaningful representations of images are essential. Structured vector quantizers based on product quantization and its variants are usually employed to achieve such compression while minimizing the loss of accuracy. Yet, unlike binary hashing schemes, these unsupervised methods have not yet benefited from the supervision, end-to-end learning and novel architectures ushered in by the deep learning revolution. We hence propose herein a novel method to make deep convolutional neural networks produce supervised, compact, structured binary codes for visual search. Our method makes use of a novel block-softmax non-linearity and of batch-based entropy losses that together induce structure in the learned encodings. We show that our method outperforms state-of-the-art compact representations based on deep hashing or structured quantization in single and cross-domain category retrieval, instance retrieval and classification. We make our code and models publicly available online.
Approximate search with quantized sparse representations
Aug 10, 2016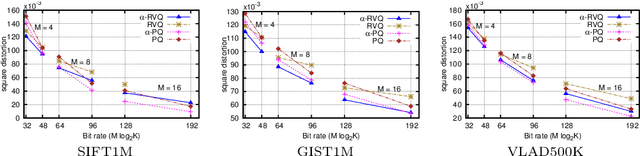
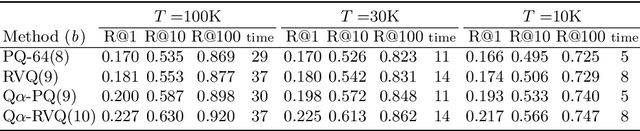
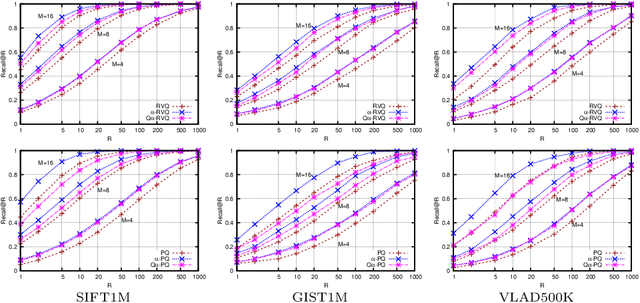
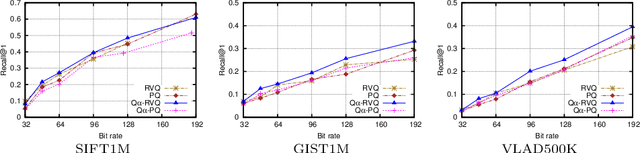
This paper tackles the task of storing a large collection of vectors, such as visual descriptors, and of searching in it. To this end, we propose to approximate database vectors by constrained sparse coding, where possible atom weights are restricted to belong to a finite subset. This formulation encompasses, as particular cases, previous state-of-the-art methods such as product or residual quantization. As opposed to traditional sparse coding methods, quantized sparse coding includes memory usage as a design constraint, thereby allowing us to index a large collection such as the BIGANN billion-sized benchmark. Our experiments, carried out on standard benchmarks, show that our formulation leads to competitive solutions when considering different trade-offs between learning/coding time, index size and search quality.