 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Zero-Shot Learning for Semantic Segmentation of 3D Point Cloud
Aug 23, 2021
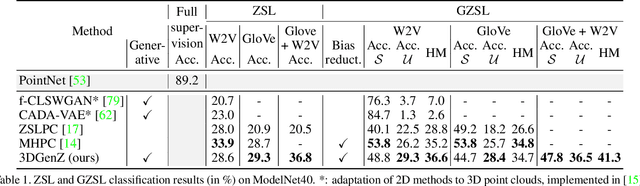
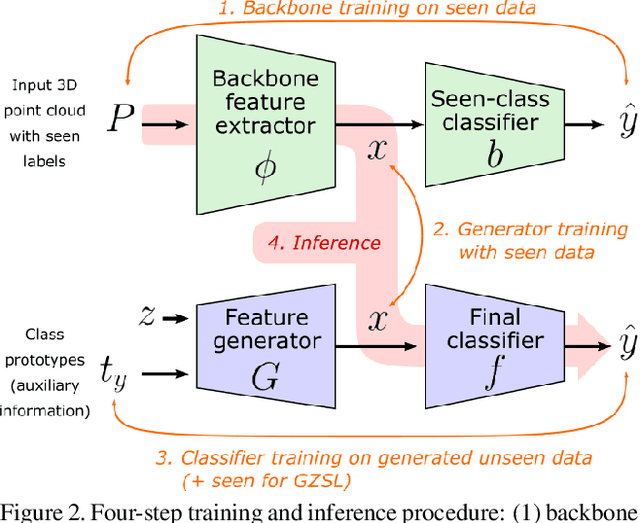
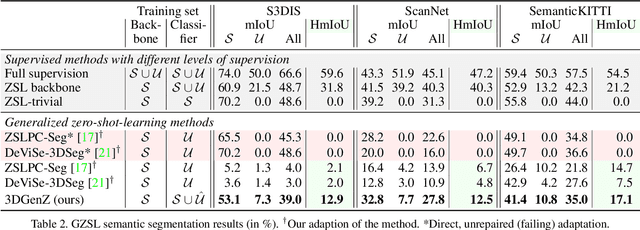
While there has been a number of studies on Zero-Shot Learning (ZSL) for 2D images, its application to 3D data is still recent and scarce, with just a few methods limited to classification. We present the first generative approach for both ZSL and Generalized ZSL (GZSL) on 3D data, that can handle both classification and, for the first time, semantic segmentation. We show that it reaches or outperforms the state of the art on ModelNet40 classification for both inductive ZSL and inductive GZSL. For semantic segmentation, we created three benchmarks for evaluating this new ZSL task, using S3DIS, ScanNet and SemanticKITTI. Our experiments show that our method outperforms strong baselines, which we additionally propose for this task.
BUDA: Boundless Unsupervised Domain Adaptation in Semantic Segmentation
Apr 02, 2020
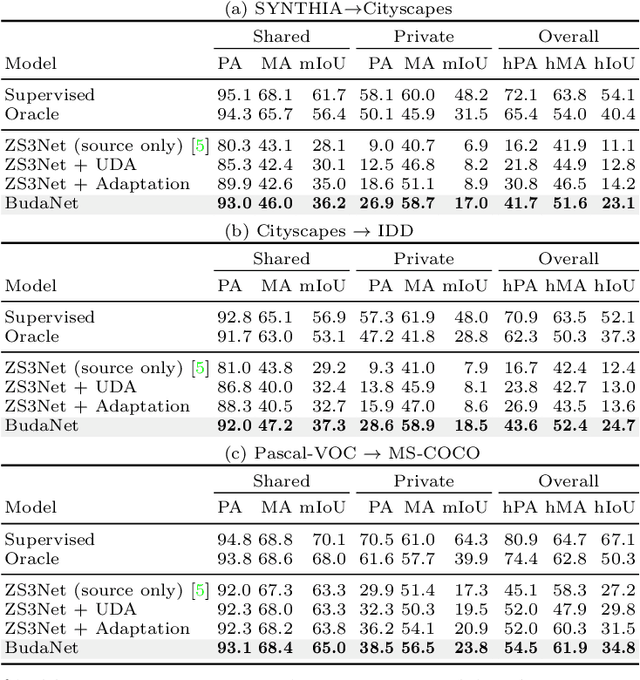
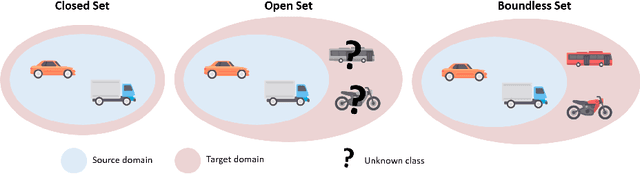
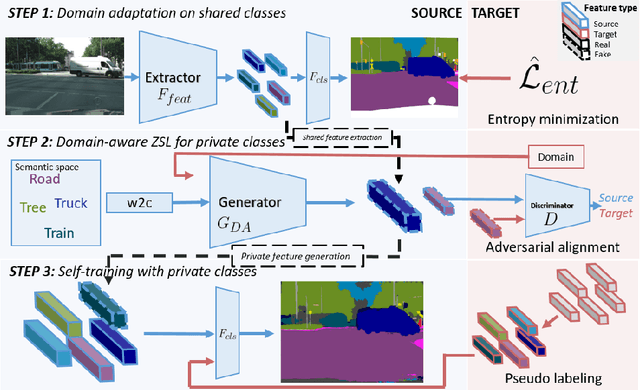
In this work, we define and address "Boundless Unsupervised Domain Adaptation" (BUDA), a novel problem in semantic segmentation. BUDA set-up pictures a realistic scenario where unsupervised target domain not only exhibits a data distribution shift w.r.t. supervised source domain but also includes classes that are absent from the latter. Different to "open-set" and "universal domain adaptation", which both regard never-seen objects as "unknown", BUDA aims at explicit test-time prediction for these never-seen classes. To reach this goal, we propose a novel framework leveraging domain adaptation and zero-shot learning techniques to enable "boundless" adaptation on the target domain. Performance is further improved using self-training on target pseudo-labels. For validation, we consider different domain adaptation set-ups, namely synthetic-2-real, country-2-country and dataset-2-dataset. Our framework outperforms the baselines by significant margins, setting competitive standards on all benchmarks for the new task. Code and models are available at:~\url{https://github.com/valeoai/buda}.
Zero-Shot Semantic Segmentation
Jun 03, 2019
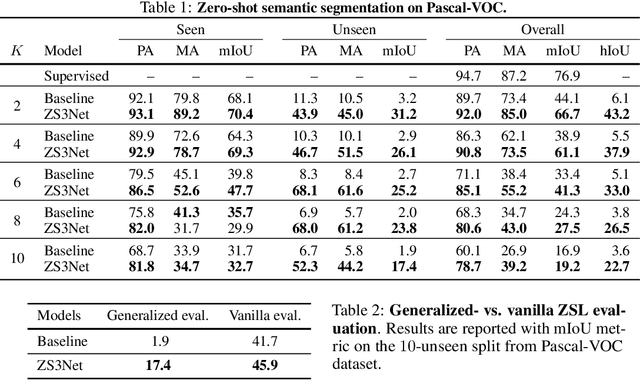
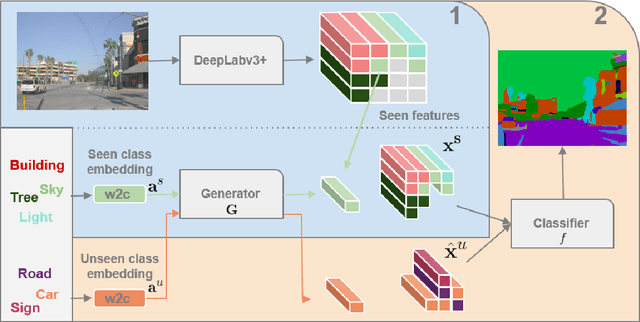
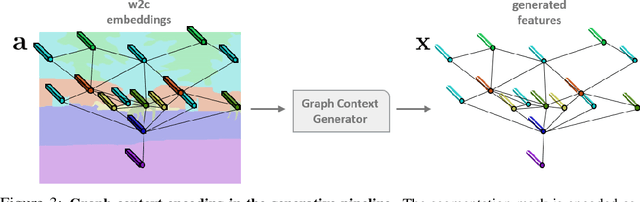
Semantic segmentation models are limited in their ability to scale to large numbers of object classes. In this paper, we introduce the new task of zero-shot semantic segmentation: learning pixel-wise classifiers for never-seen object categories with zero training examples. To this end, we present a novel architecture, ZS3Net, combining a deep visual segmentation model with an approach to generate visual representations from semantic word embeddings. By this way, ZS3Net addresses pixel classification tasks where both seen and unseen categories are faced at test time (so called "generalized" zero-shot classification). Performance is further improved by a self-training step that relies on automatic pseudo-labeling of pixels from unseen classes. On the two standard segmentation datasets, Pascal-VOC and Pascal-Context, we propose zero-shot benchmarks and set competitive baselines. For complex scenes as ones in the Pascal-Context dataset, we extend our approach by using a graph-context encoding to fully leverage spatial context priors coming from class-wise segmentation maps.
DADA: Depth-aware Domain Adaptation in Semantic Segmentation
Apr 04, 2019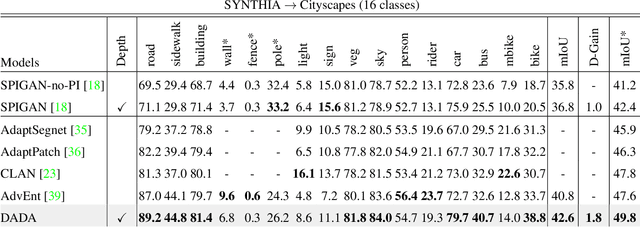
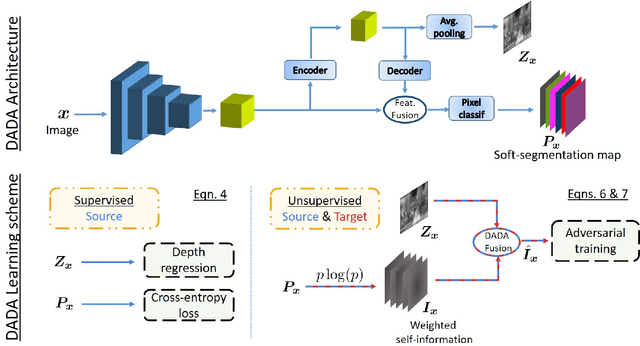
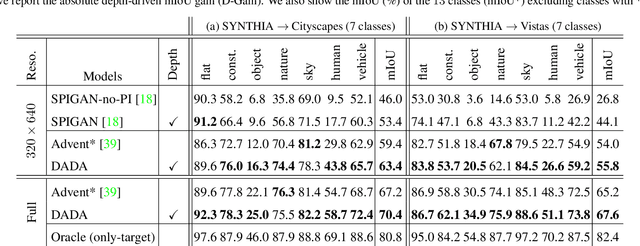

Unsupervised domain adaptation (UDA) is important for applications where large scale annotation of representative data is challenging. For semantic segmentation in particular, it helps deploy on real "target domain" data models that are trained on annotated images from a different "source domain", notably a virtual environment. To this end, most previous works consider semantic segmentation as the only mode of supervision for source domain data, while ignoring other, possibly available, information like depth. In this work, we aim at exploiting at best such a privileged information while training the UDA model. We propose a unified depth-aware UDA framework that leverages in several complementary ways the knowledge of dense depth in the source domain. As a result, the performance of the trained semantic segmentation model on the target domain is boosted. Our novel approach indeed achieves state-of-the-art performance on different challenging synthetic-2-real benchmarks.
ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
Nov 30, 2018

Semantic segmentation is a key problem for many computer vision tasks. While approaches based on convolutional neural networks constantly break new records on different benchmarks, generalizing well to diverse testing environments remains a major challenge. In numerous real world applications, there is indeed a large gap between data distributions in train and test domains, which results in severe performance loss at run-time. In this work, we address the task of unsupervised domain adaptation in semantic segmentation with losses based on the entropy of the pixel-wise predictions. To this end, we propose two novel, complementary methods using (i) entropy loss and (ii) adversarial loss respectively. We demonstrate state-of-the-art performance in semantic segmentation on two challenging "synthetic-2-real" set-ups and show that the approach can also be used for detection.
Semantic bottleneck for computer vision tasks
Nov 06, 2018
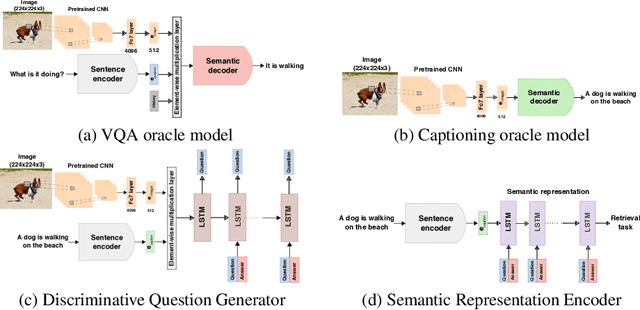


This paper introduces a novel method for the representation of images that is semantic by nature, addressing the question of computation intelligibility in computer vision tasks. More specifically, our proposition is to introduce what we call a semantic bottleneck in the processing pipeline, which is a crossing point in which the representation of the image is entirely expressed with natural language , while retaining the efficiency of numerical representations. We show that our approach is able to generate semantic representations that give state-of-the-art results on semantic content-based image retrieval and also perform very well on image classification tasks. Intelligibility is evaluated through user centered experiments for failure detection.
Generating Visual Representations for Zero-Shot Classification
Dec 11, 2017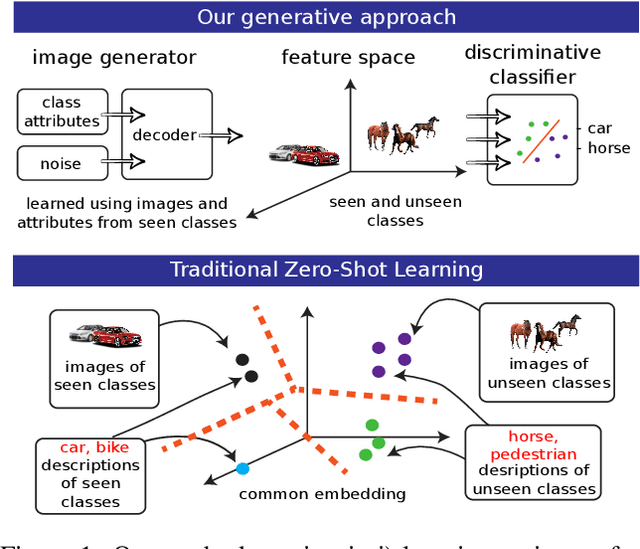
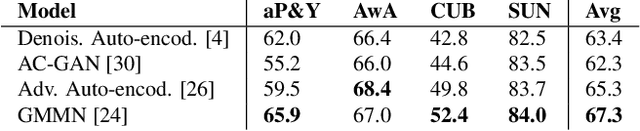
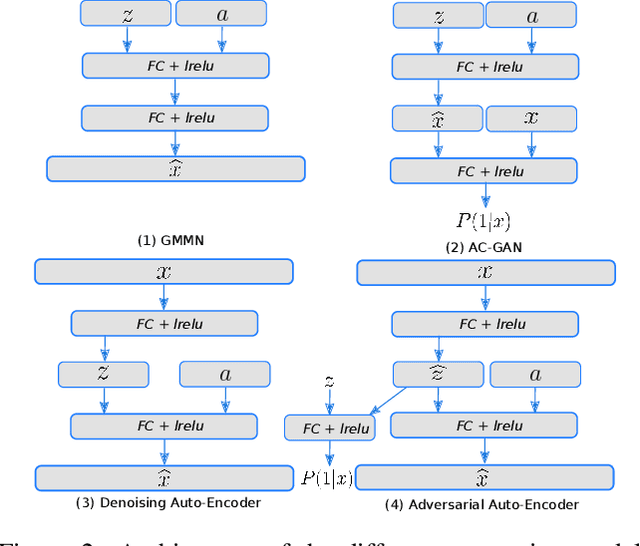
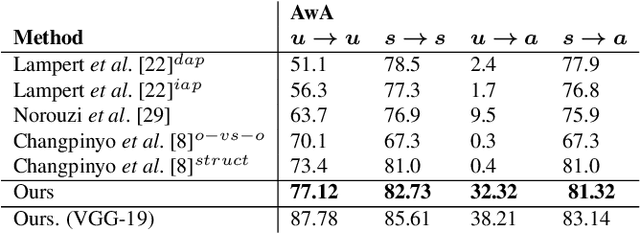
This paper addresses the task of learning an image clas-sifier when some categories are defined by semantic descriptions only (e.g. visual attributes) while the others are defined by exemplar images as well. This task is often referred to as the Zero-Shot classification task (ZSC). Most of the previous methods rely on learning a common embedding space allowing to compare visual features of unknown categories with semantic descriptions. This paper argues that these approaches are limited as i) efficient discrimi-native classifiers can't be used ii) classification tasks with seen and unseen categories (Generalized Zero-Shot Classification or GZSC) can't be addressed efficiently. In contrast , this paper suggests to address ZSC and GZSC by i) learning a conditional generator using seen classes ii) generate artificial training examples for the categories without exemplars. ZSC is then turned into a standard supervised learning problem. Experiments with 4 generative models and 5 datasets experimentally validate the approach, giving state-of-the-art results on both ZSC and GZSC.
Hard Negative Mining for Metric Learning Based Zero-Shot Classification
Aug 26, 2016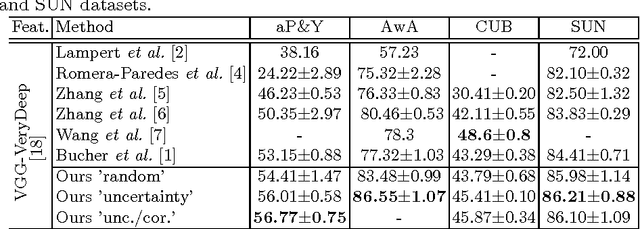
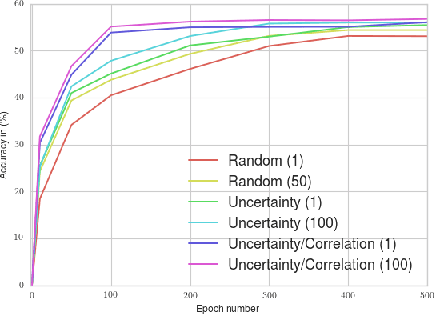
Zero-Shot learning has been shown to be an efficient strategy for domain adaptation. In this context, this paper builds on the recent work of Bucher et al. [1], which proposed an approach to solve Zero-Shot classification problems (ZSC) by introducing a novel metric learning based objective function. This objective function allows to learn an optimal embedding of the attributes jointly with a measure of similarity between images and attributes. This paper extends their approach by proposing several schemes to control the generation of the negative pairs, resulting in a significant improvement of the performance and giving above state-of-the-art results on three challenging ZSC datasets.
Improving Semantic Embedding Consistency by Metric Learning for Zero-Shot Classification
Jul 27, 2016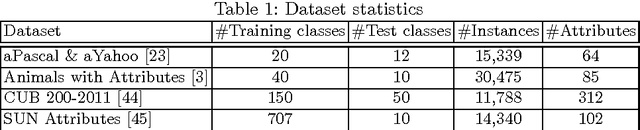
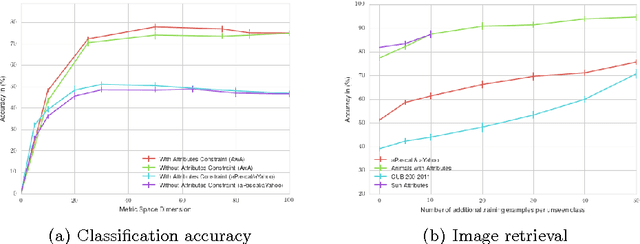
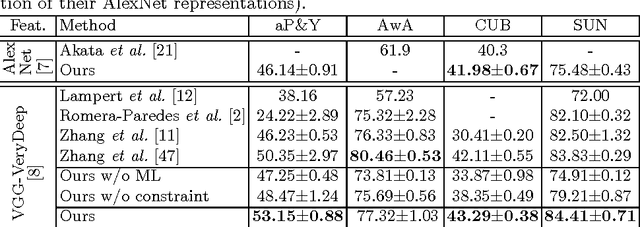
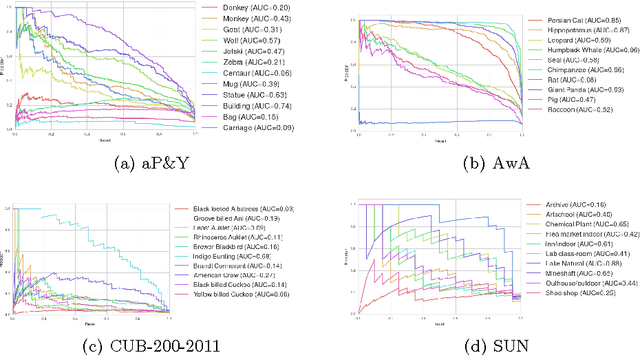
This paper addresses the task of zero-shot image classification. The key contribution of the proposed approach is to control the semantic embedding of images -- one of the main ingredients of zero-shot learning -- by formulating it as a metric learning problem. The optimized empirical criterion associates two types of sub-task constraints: metric discriminating capacity and accurate attribute prediction. This results in a novel expression of zero-shot learning not requiring the notion of class in the training phase: only pairs of image/attributes, augmented with a consistency indicator, are given as ground truth. At test time, the learned model can predict the consistency of a test image with a given set of attributes , allowing flexible ways to produce recognition inferences. Despite its simplicity, the proposed approach gives state-of-the-art results on four challenging datasets used for zero-shot recognition evaluation.