 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Visual Representations for Zero-Shot Classification
Paper and Code
Dec 11, 2017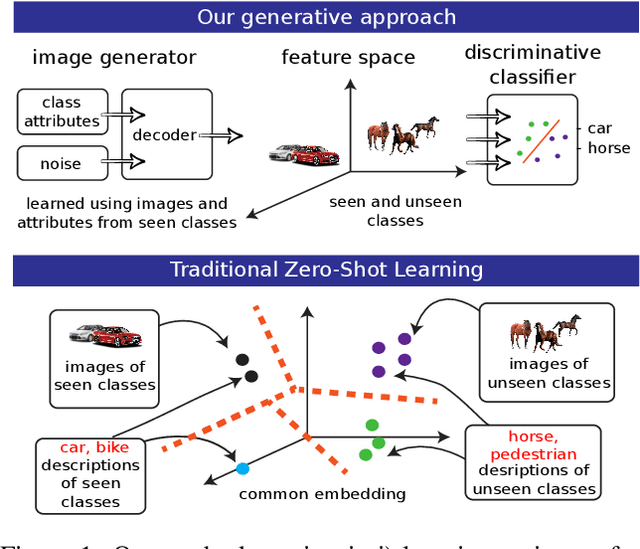
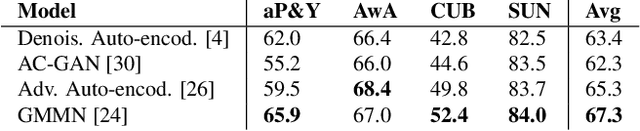
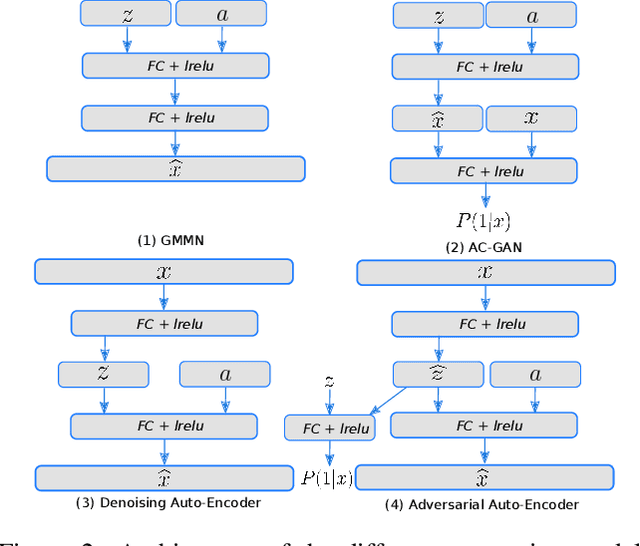
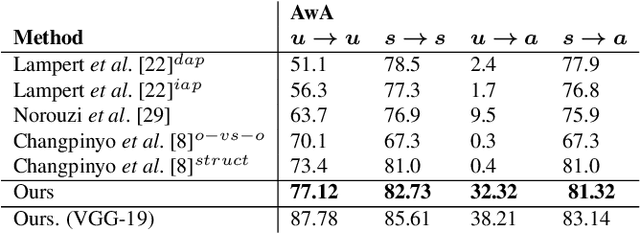
This paper addresses the task of learning an image clas-sifier when some categories are defined by semantic descriptions only (e.g. visual attributes) while the others are defined by exemplar images as well. This task is often referred to as the Zero-Shot classification task (ZSC). Most of the previous methods rely on learning a common embedding space allowing to compare visual features of unknown categories with semantic descriptions. This paper argues that these approaches are limited as i) efficient discrimi-native classifiers can't be used ii) classification tasks with seen and unseen categories (Generalized Zero-Shot Classification or GZSC) can't be addressed efficiently. In contrast , this paper suggests to address ZSC and GZSC by i) learning a conditional generator using seen classes ii) generate artificial training examples for the categories without exemplars. ZSC is then turned into a standard supervised learning problem. Experiments with 4 generative models and 5 datasets experimentally validate the approach, giving state-of-the-art results on both ZSC and GZSC.