 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration of Classifiers with Many Classes
Nov 05, 2024


For classification models based on neural networks, the maximum predicted class probability is often used as a confidence score. This score rarely predicts well the probability of making a correct prediction and requires a post-processing calibration step. However, many confidence calibration methods fail for problems with many classes. To address this issue, we transform the problem of calibrating a multiclass classifier into calibrating a single surrogate binary classifier. This approach allows for more efficient use of standard calibration methods. We evaluate our approach on numerous neural networks used for image or text classification and show that it significantly enhances existing calibration methods.
Efficient Exploration of Image Classifier Failures with Bayesian Optimization and Text-to-Image Models
Apr 26, 2024



Image classifiers should be used with caution in the real world. Performance evaluated on a validation set may not reflect performance in the real world. In particular, classifiers may perform well for conditions that are frequently encountered during training, but poorly for other infrequent conditions. In this study, we hypothesize that recent advances in text-to-image generative models make them valuable for benchmarking computer vision models such as image classifiers: they can generate images conditioned by textual prompts that cause classifier failures, allowing failure conditions to be described with textual attributes. However, their generation cost becomes an issue when a large number of synthetic images need to be generated, which is the case when many different attribute combinations need to be tested. We propose an image classifier benchmarking method as an iterative process that alternates image generation, classifier evaluation, and attribute selection. This method efficiently explores the attributes that ultimately lead to poor behavior detection.
Carpet-bombing patch: attacking a deep network without usual requirements
Dec 12, 2022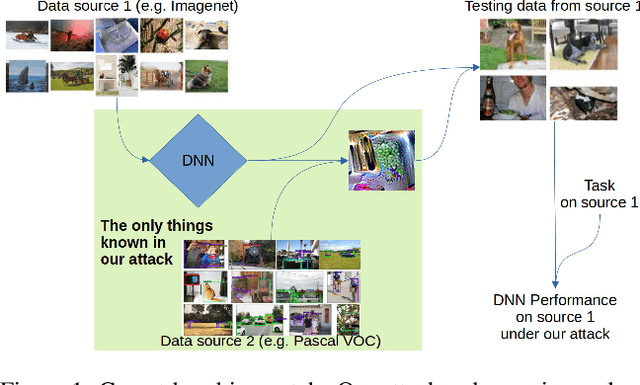


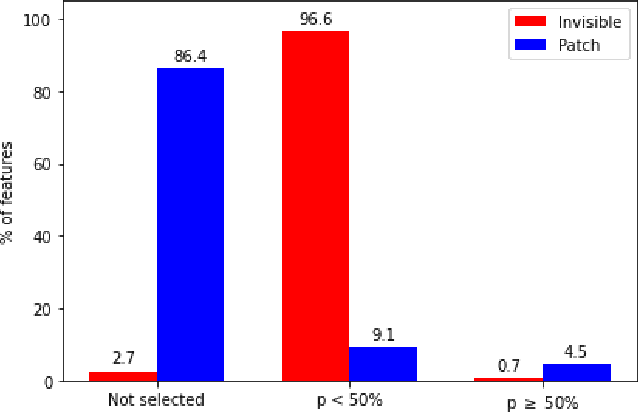
Although deep networks have shown vulnerability to evasion attacks, such attacks have usually unrealistic requirements. Recent literature discussed the possibility to remove or not some of these requirements. This paper contributes to this literature by introducing a carpet-bombing patch attack which has almost no requirement. Targeting the feature representations, this patch attack does not require knowing the network task. This attack decreases accuracy on Imagenet, mAP on Pascal Voc, and IoU on Cityscapes without being aware that the underlying tasks involved classification, detection or semantic segmentation, respectively. Beyond the potential safety issues raised by this attack, the impact of the carpet-bombing attack highlights some interesting property of deep network layer dynamic.
Semantic bottleneck for computer vision tasks
Nov 06, 2018
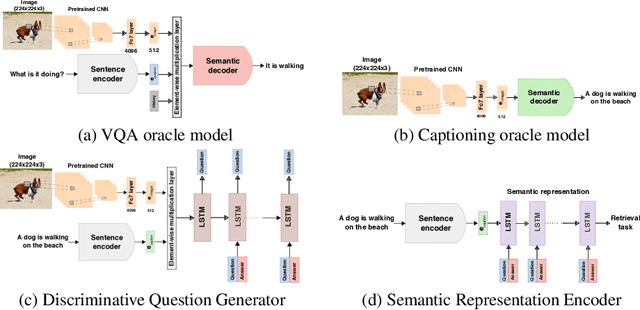


This paper introduces a novel method for the representation of images that is semantic by nature, addressing the question of computation intelligibility in computer vision tasks. More specifically, our proposition is to introduce what we call a semantic bottleneck in the processing pipeline, which is a crossing point in which the representation of the image is entirely expressed with natural language , while retaining the efficiency of numerical representations. We show that our approach is able to generate semantic representations that give state-of-the-art results on semantic content-based image retrieval and also perform very well on image classification tasks. Intelligibility is evaluated through user centered experiments for failure detection.
Generating Visual Representations for Zero-Shot Classification
Dec 11, 2017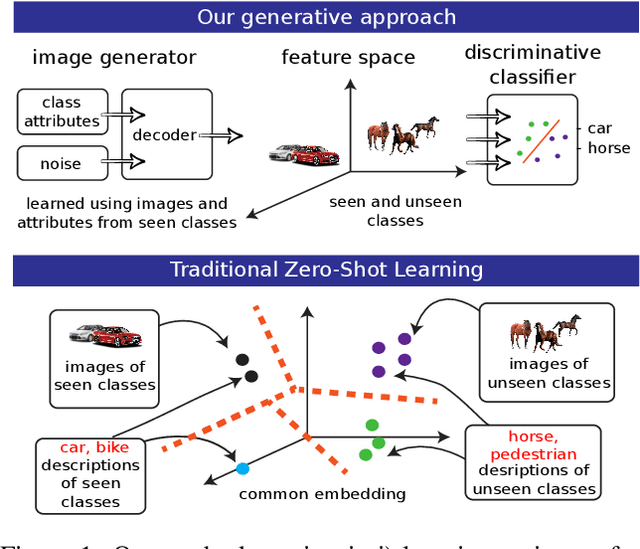
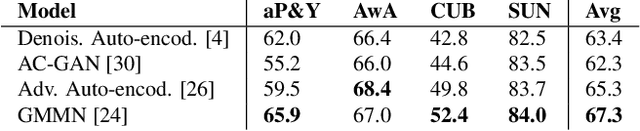
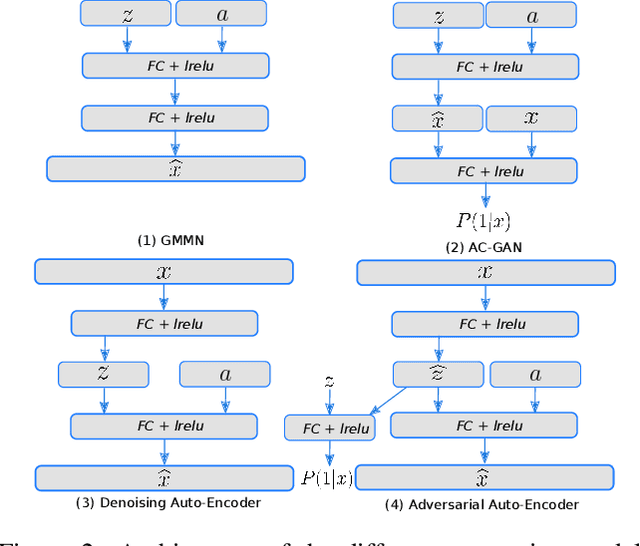
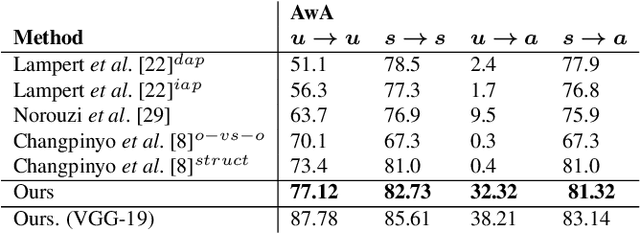
This paper addresses the task of learning an image clas-sifier when some categories are defined by semantic descriptions only (e.g. visual attributes) while the others are defined by exemplar images as well. This task is often referred to as the Zero-Shot classification task (ZSC). Most of the previous methods rely on learning a common embedding space allowing to compare visual features of unknown categories with semantic descriptions. This paper argues that these approaches are limited as i) efficient discrimi-native classifiers can't be used ii) classification tasks with seen and unseen categories (Generalized Zero-Shot Classification or GZSC) can't be addressed efficiently. In contrast , this paper suggests to address ZSC and GZSC by i) learning a conditional generator using seen classes ii) generate artificial training examples for the categories without exemplars. ZSC is then turned into a standard supervised learning problem. Experiments with 4 generative models and 5 datasets experimentally validate the approach, giving state-of-the-art results on both ZSC and GZSC.
Hard Negative Mining for Metric Learning Based Zero-Shot Classification
Aug 26, 2016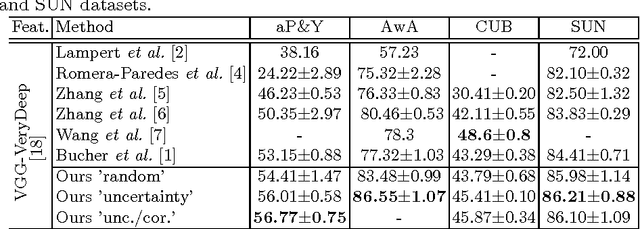
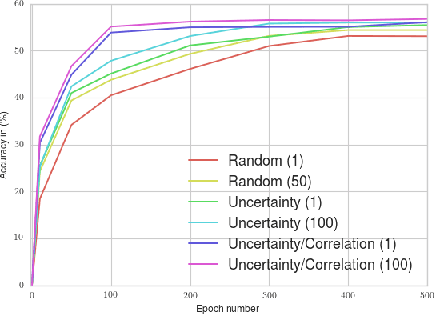
Zero-Shot learning has been shown to be an efficient strategy for domain adaptation. In this context, this paper builds on the recent work of Bucher et al. [1], which proposed an approach to solve Zero-Shot classification problems (ZSC) by introducing a novel metric learning based objective function. This objective function allows to learn an optimal embedding of the attributes jointly with a measure of similarity between images and attributes. This paper extends their approach by proposing several schemes to control the generation of the negative pairs, resulting in a significant improvement of the performance and giving above state-of-the-art results on three challenging ZSC datasets.
Improving Semantic Embedding Consistency by Metric Learning for Zero-Shot Classification
Jul 27, 2016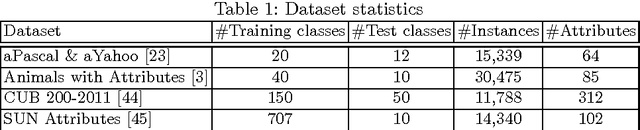
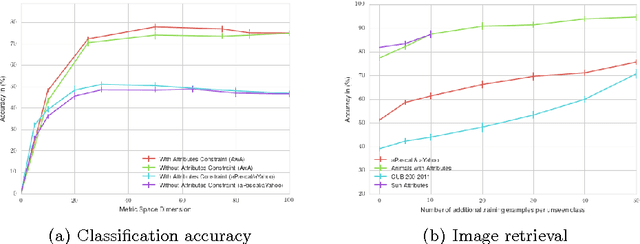
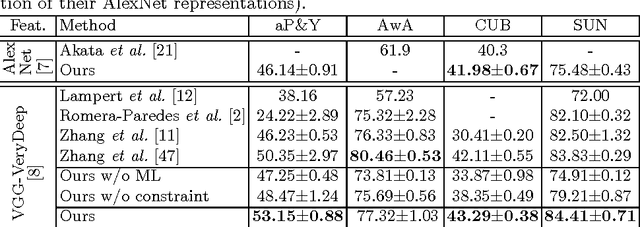
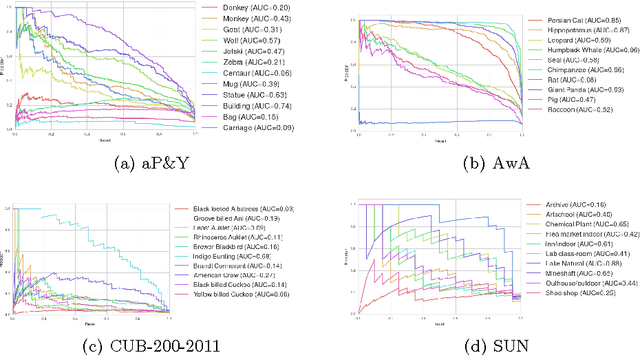
This paper addresses the task of zero-shot image classification. The key contribution of the proposed approach is to control the semantic embedding of images -- one of the main ingredients of zero-shot learning -- by formulating it as a metric learning problem. The optimized empirical criterion associates two types of sub-task constraints: metric discriminating capacity and accurate attribute prediction. This results in a novel expression of zero-shot learning not requiring the notion of class in the training phase: only pairs of image/attributes, augmented with a consistency indicator, are given as ground truth. At test time, the learned model can predict the consistency of a test image with a given set of attributes , allowing flexible ways to produce recognition inferences. Despite its simplicity, the proposed approach gives state-of-the-art results on four challenging datasets used for zero-shot recognition evaluation.