 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Calibration of Classifiers with Many Classes
Nov 05, 2024
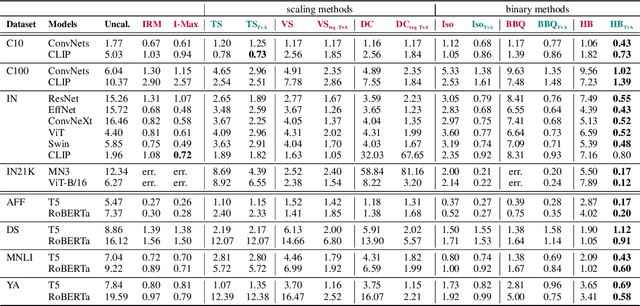


For classification models based on neural networks, the maximum predicted class probability is often used as a confidence score. This score rarely predicts well the probability of making a correct prediction and requires a post-processing calibration step. However, many confidence calibration methods fail for problems with many classes. To address this issue, we transform the problem of calibrating a multiclass classifier into calibrating a single surrogate binary classifier. This approach allows for more efficient use of standard calibration methods. We evaluate our approach on numerous neural networks used for image or text classification and show that it significantly enhances existing calibration methods.
Efficient Exploration of Image Classifier Failures with Bayesian Optimization and Text-to-Image Models
Apr 26, 2024



Image classifiers should be used with caution in the real world. Performance evaluated on a validation set may not reflect performance in the real world. In particular, classifiers may perform well for conditions that are frequently encountered during training, but poorly for other infrequent conditions. In this study, we hypothesize that recent advances in text-to-image generative models make them valuable for benchmarking computer vision models such as image classifiers: they can generate images conditioned by textual prompts that cause classifier failures, allowing failure conditions to be described with textual attributes. However, their generation cost becomes an issue when a large number of synthetic images need to be generated, which is the case when many different attribute combinations need to be tested. We propose an image classifier benchmarking method as an iterative process that alternates image generation, classifier evaluation, and attribute selection. This method efficiently explores the attributes that ultimately lead to poor behavior detection.