 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytical Logit Scaling for High-Resolution Sea Ice Topology Retrieval from Weakly Labeled SAR Imagery
Mar 13, 2026High-resolution sea ice mapping using Synthetic Aperture Radar (SAR) is crucial for Arctic navigation and climate monitoring. However, operational ice charts provide only coarse, region-level polygons (weak labels), forcing automated segmentation models to struggle with pixel-level accuracy and often yielding under-confident, blurred concentration maps. In this paper, we propose a weakly supervised deep learning pipeline that fuses Sentinel-1 SAR and AMSR-2 radiometry data using a U-Net architecture trained with a region-based loss. To overcome the severe under-confidence caused by weak labels, we introduce an Analytical Logit Scaling method applied post-inference. By dynamically calculating the temperature and bias based on the latent space percentiles (2\% and 98\%) of each scene, we force a physical binarization of the predictions. This adaptive scaling acts as a topological extractor, successfully revealing fine-grained sea ice fractures (leads) at a 40-meter resolution without requiring any manual pixel-level annotations. Our approach not only resolves local topology but also perfectly preserves regional macroscopic concentrations, achieving a 78\% accuracy on highly fragmented summer scenes, thereby bridging the gap between weakly supervised learning and high-resolution physical segmentation.
Deep Learning-Based Robust Optical Guidance for Hypersonic Platforms
May 09, 2025Sensor-based guidance is required for long-range platforms. To bypass the structural limitation of classical registration on reference image framework, we offer in this paper to encode a stack of images of the scene into a deep network. Relying on a stack is showed to be relevant on bimodal scene (e.g. when the scene can or can not be snowy).
Packed-Ensemble Surrogate Models for Fluid Flow Estimation Arround Airfoil Geometries
Dec 20, 2023Physical based simulations can be very time and computationally demanding tasks. One way of accelerating these processes is by making use of data-driven surrogate models that learn from existing simulations. Ensembling methods are particularly relevant in this domain as their smoothness properties coincide with the smoothness of physical phenomena. The drawback is that they can remain costly. This research project focused on studying Packed-Ensembles that generalize Deep Ensembles but remain faster to train. Several models have been trained and compared in terms of multiple important metrics. PE(8,4,1) has been identified as the clear winner in this particular task, beating down its Deep Ensemble conterpart while accelerating the training time by 25%.
Carpet-bombing patch: attacking a deep network without usual requirements
Dec 12, 2022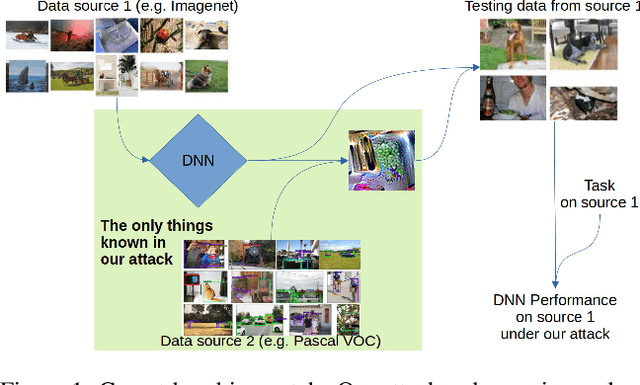


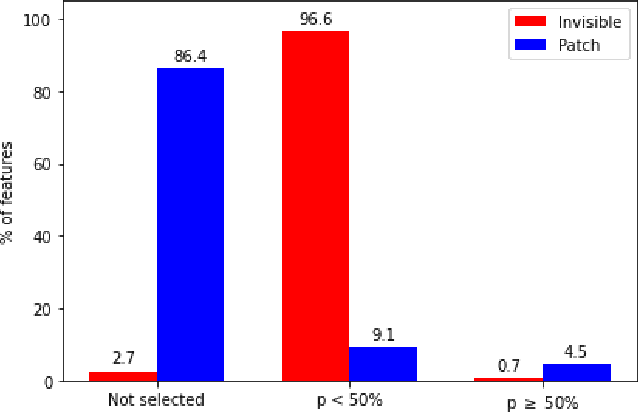
Although deep networks have shown vulnerability to evasion attacks, such attacks have usually unrealistic requirements. Recent literature discussed the possibility to remove or not some of these requirements. This paper contributes to this literature by introducing a carpet-bombing patch attack which has almost no requirement. Targeting the feature representations, this patch attack does not require knowing the network task. This attack decreases accuracy on Imagenet, mAP on Pascal Voc, and IoU on Cityscapes without being aware that the underlying tasks involved classification, detection or semantic segmentation, respectively. Beyond the potential safety issues raised by this attack, the impact of the carpet-bombing attack highlights some interesting property of deep network layer dynamic.
DIAL: Deep Interactive and Active Learning for Semantic Segmentation in Remote Sensing
Jan 04, 2022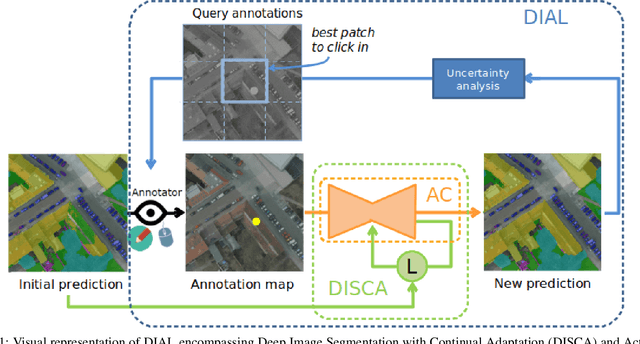

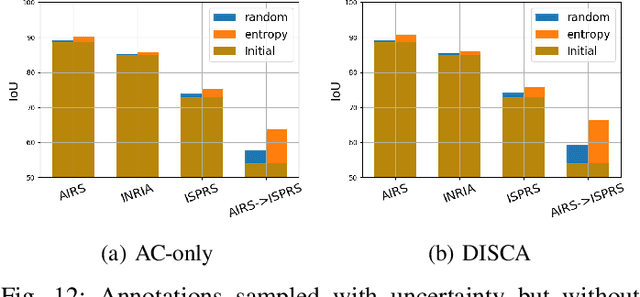
We propose in this article to build up a collaboration between a deep neural network and a human in the loop to swiftly obtain accurate segmentation maps of remote sensing images. In a nutshell, the agent iteratively interacts with the network to correct its initially flawed predictions. Concretely, these interactions are annotations representing the semantic labels. Our methodological contribution is twofold. First, we propose two interactive learning schemes to integrate user inputs into deep neural networks. The first one concatenates the annotations with the other network's inputs. The second one uses the annotations as a sparse ground-truth to retrain the network. Second, we propose an active learning strategy to guide the user towards the most relevant areas to annotate. To this purpose, we compare different state-of-the-art acquisition functions to evaluate the neural network uncertainty such as ConfidNet, entropy or ODIN. Through experiments on three remote sensing datasets, we show the effectiveness of the proposed methods. Notably, we show that active learning based on uncertainty estimation enables to quickly lead the user towards mistakes and that it is thus relevant to guide the user interventions.
Weakly-supervised continual learning for class-incremental segmentation
Jan 04, 2022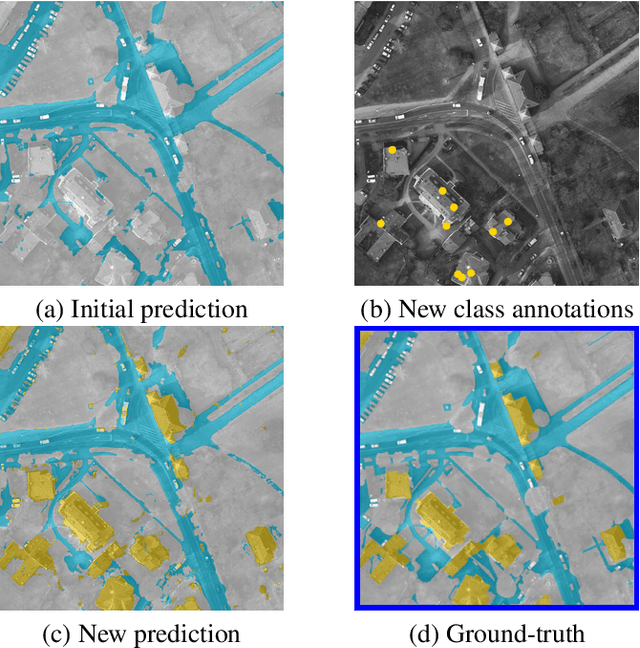


Transfer learning is a powerful way to adapt existing deep learning models to new emerging use-cases in remote sensing. Starting from a neural network already trained for semantic segmentation, we propose to modify its label space to swiftly adapt it to new classes under weak supervision. To alleviate the background shift and the catastrophic forgetting problems inherent to this form of continual learning, we compare different regularization terms and leverage a pseudo-label strategy. We experimentally show the relevance of our approach on three public remote sensing datasets.
Demotivate adversarial defense in remote sensing
May 28, 2021
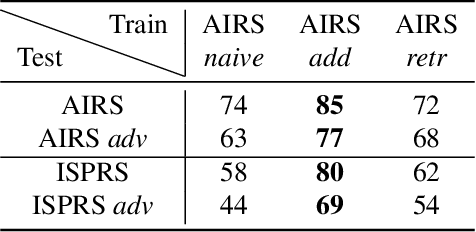
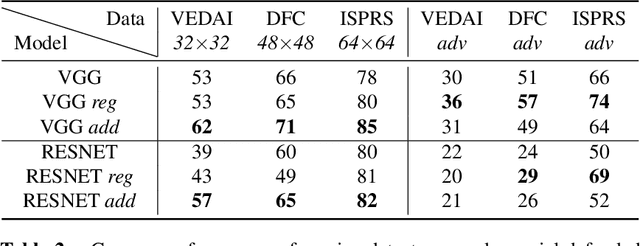
Convolutional neural networks are currently the state-of-the-art algorithms for many remote sensing applications such as semantic segmentation or object detection. However, these algorithms are extremely sensitive to over-fitting, domain change and adversarial examples specifically designed to fool them. While adversarial attacks are not a threat in most remote sensing applications, one could wonder if strengthening networks to adversarial attacks could also increase their resilience to over-fitting and their ability to deal with the inherent variety of worldwide data. In this work, we study both adversarial retraining and adversarial regularization as adversarial defenses to this purpose. However, we show through several experiments on public remote sensing datasets that adversarial robustness seems uncorrelated to geographic and over-fitting robustness.
Learning-based vs Model-free Adaptive Control of a MAV under Wind Gust
Jan 29, 2021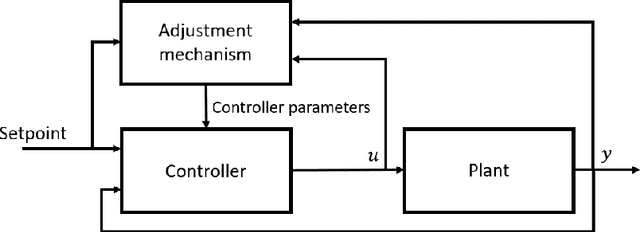
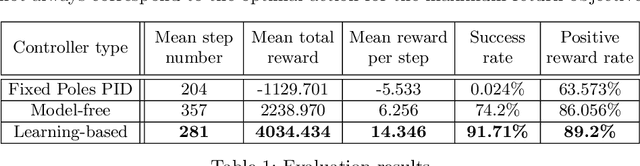
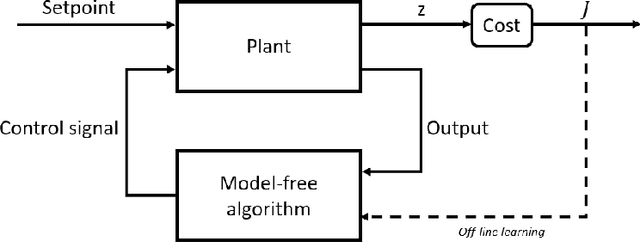

Navigation problems under unknown varying conditions are among the most important and well-studied problems in the control field. Classic model-based adaptive control methods can be applied only when a convenient model of the plant or environment is provided. Recent model-free adaptive control methods aim at removing this dependency by learning the physical characteristics of the plant and/or process directly from sensor feedback. Although there have been prior attempts at improving these techniques, it remains an open question as to whether it is possible to cope with real-world uncertainties in a control system that is fully based on either paradigm. We propose a conceptually simple learning-based approach composed of a full state feedback controller, tuned robustly by a deep reinforcement learning framework based on the Soft Actor-Critic algorithm. We compare it, in realistic simulations, to a model-free controller that uses the same deep reinforcement learning framework for the control of a micro aerial vehicle under wind gust. The results indicate the great potential of learning-based adaptive control methods in modern dynamical systems.
SALAD: Self-Assessment Learning for Action Detection
Nov 13, 2020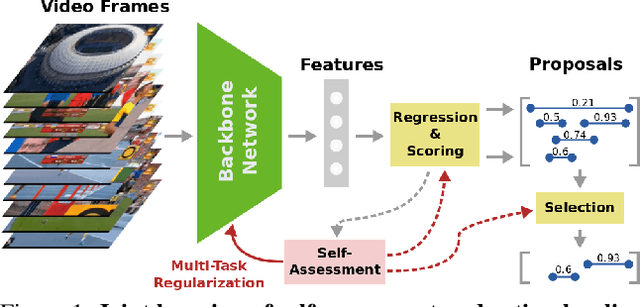
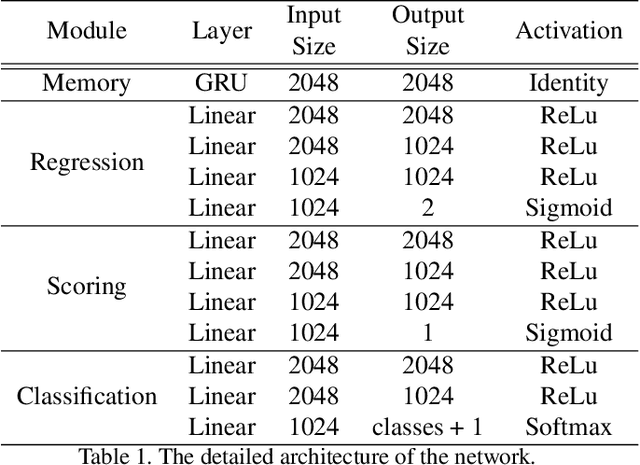
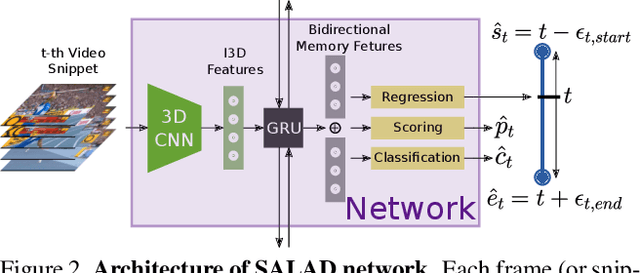
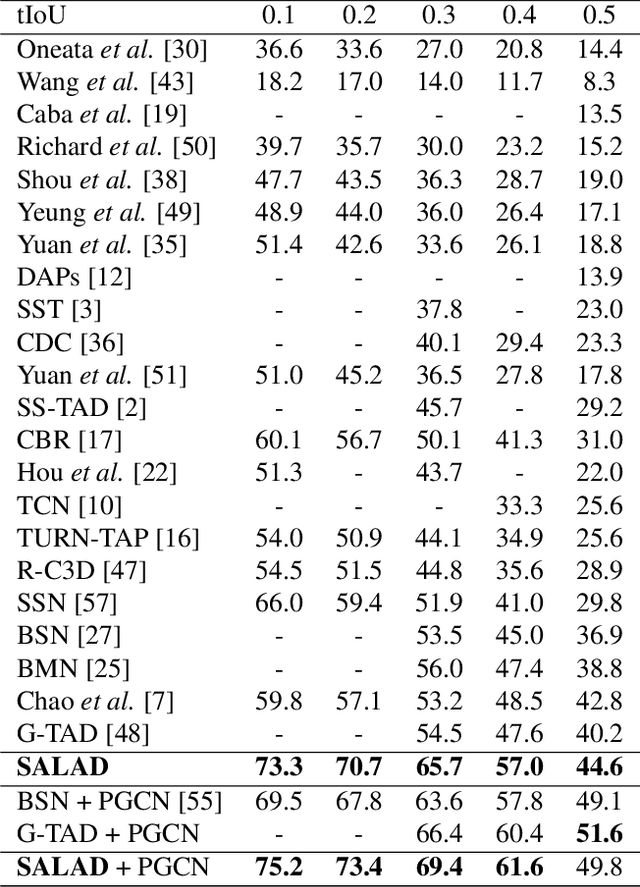
Literature on self-assessment in machine learning mainly focuses on the production of well-calibrated algorithms through consensus frameworks i.e. calibration is seen as a problem. Yet, we observe that learning to be properly confident could behave like a powerful regularization and thus, could be an opportunity to improve performance.Precisely, we show that used within a framework of action detection, the learning of a self-assessment score is able to improve the whole action localization process.Experimental results show that our approach outperforms the state-of-the-art on two action detection benchmarks. On THUMOS14 dataset, the mAP at tIoU@0.5 is improved from 42.8\% to 44.6\%, and from 50.4\% to 51.7\% on ActivityNet1.3 dataset. For lower tIoU values, we achieve even more significant improvements on both datasets.
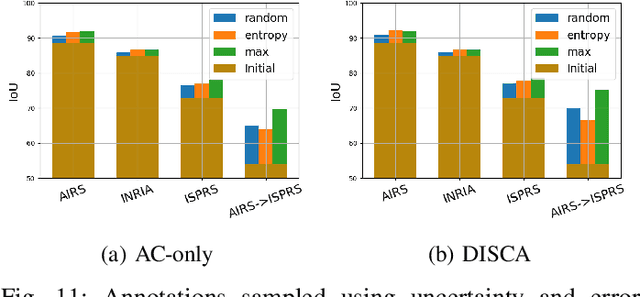
Interactive Learning for Semantic Segmentation in Earth Observation
Sep 23, 2020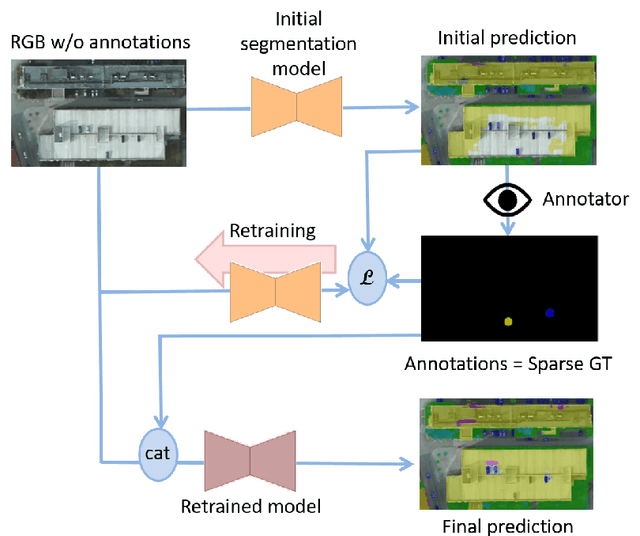


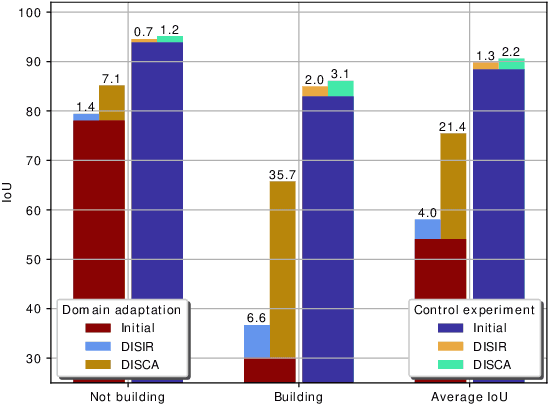
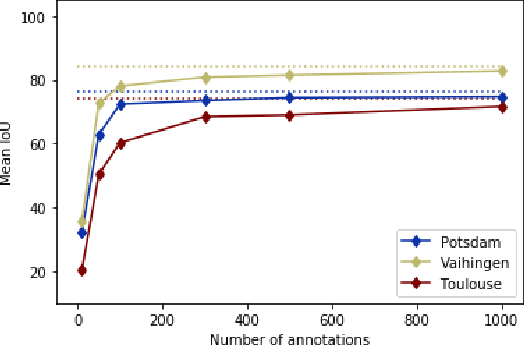
Dense pixel-wise classification maps output by deep neural networks are of extreme importance for scene understanding. However, these maps are often partially inaccurate due to a variety of possible factors. Therefore, we propose to interactively refine them within a framework named DISCA (Deep Image Segmentation with Continual Adaptation). It consists of continually adapting a neural network to a target image using an interactive learning process with sparse user annotations as ground-truth. We show through experiments on three datasets using synthesized annotations the benefits of the approach, reaching an IoU improvement up to 4.7% for ten sampled clicks. Finally, we exhibit that our approach can be particularly rewarding when it is faced to additional issues such as domain adaptation.