 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIAL: Deep Interactive and Active Learning for Semantic Segmentation in Remote Sensing
Jan 04, 2022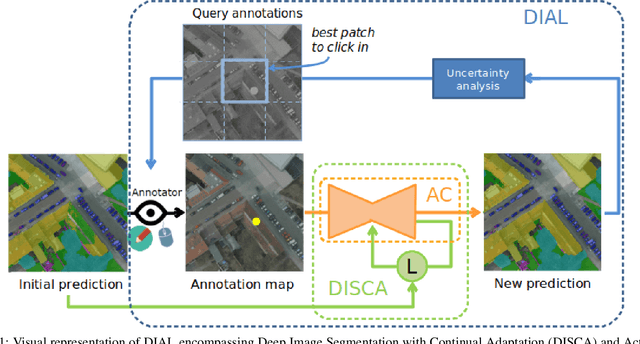

We propose in this article to build up a collaboration between a deep neural network and a human in the loop to swiftly obtain accurate segmentation maps of remote sensing images. In a nutshell, the agent iteratively interacts with the network to correct its initially flawed predictions. Concretely, these interactions are annotations representing the semantic labels. Our methodological contribution is twofold. First, we propose two interactive learning schemes to integrate user inputs into deep neural networks. The first one concatenates the annotations with the other network's inputs. The second one uses the annotations as a sparse ground-truth to retrain the network. Second, we propose an active learning strategy to guide the user towards the most relevant areas to annotate. To this purpose, we compare different state-of-the-art acquisition functions to evaluate the neural network uncertainty such as ConfidNet, entropy or ODIN. Through experiments on three remote sensing datasets, we show the effectiveness of the proposed methods. Notably, we show that active learning based on uncertainty estimation enables to quickly lead the user towards mistakes and that it is thus relevant to guide the user interventions.
OV$^{2}$SLAM : A Fully Online and Versatile Visual SLAM for Real-Time Applications
Feb 08, 2021
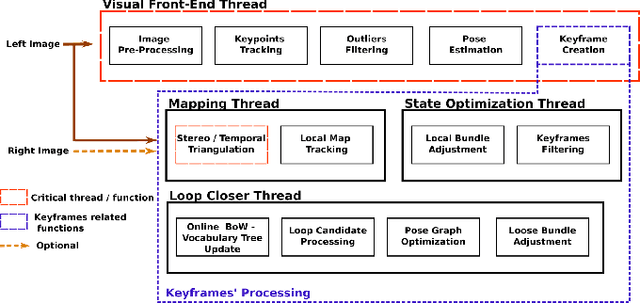
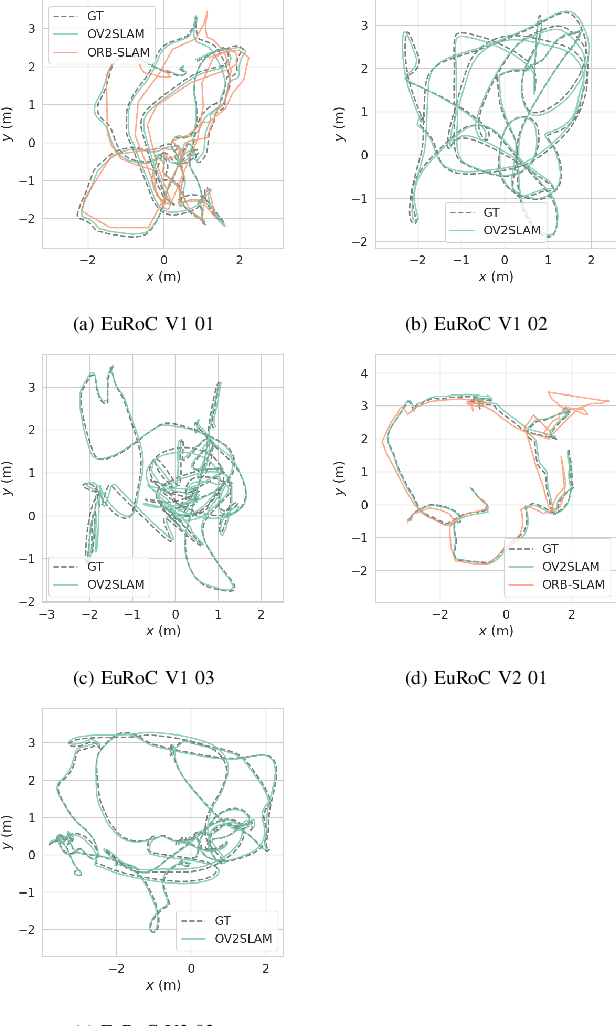
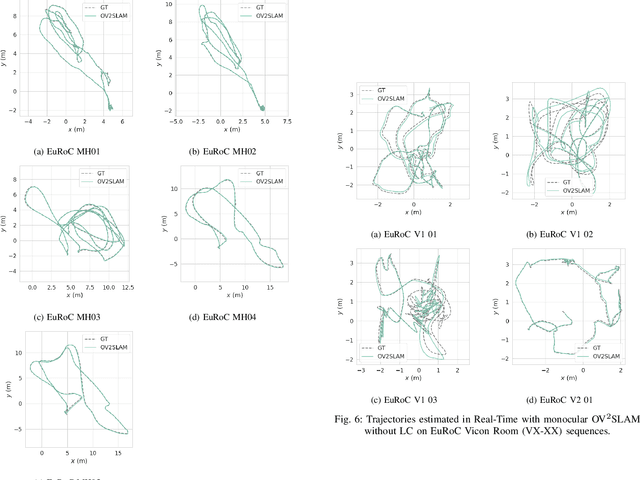
Many applications of Visual SLAM, such as augmented reality, virtual reality, robotics or autonomous driving, require versatile, robust and precise solutions, most often with real-time capability. In this work, we describe OV$^{2}$SLAM, a fully online algorithm, handling both monocular and stereo camera setups, various map scales and frame-rates ranging from a few Hertz up to several hundreds. It combines numerous recent contributions in visual localization within an efficient multi-threaded architecture. Extensive comparisons with competing algorithms shows the state-of-the-art accuracy and real-time performance of the resulting algorithm. For the benefit of the community, we release the source code: \url{https://github.com/ov2slam/ov2slam}.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L). Code is available at : \url{https://github.com/ov2slam/ov2slam}
Interactive Learning for Semantic Segmentation in Earth Observation
Sep 23, 2020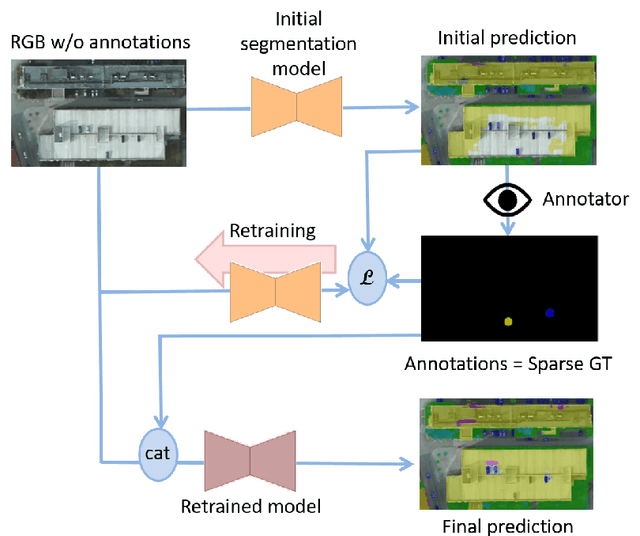


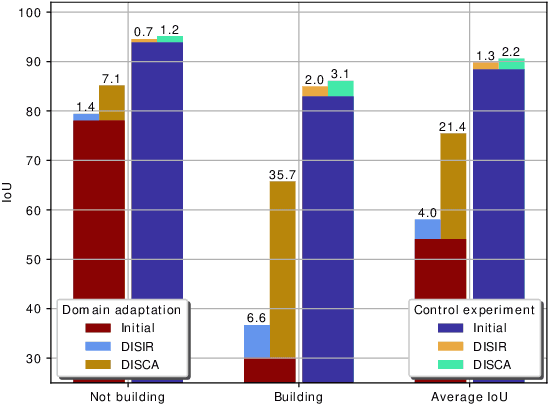
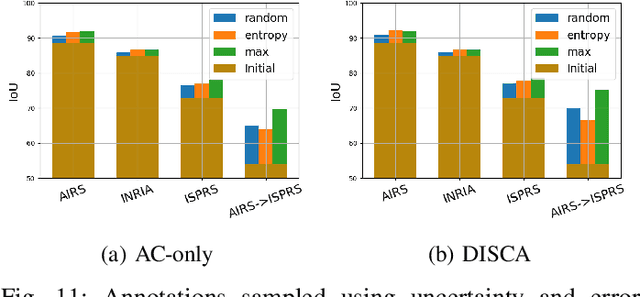
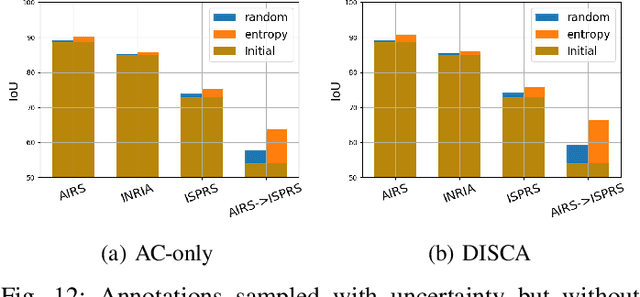
Dense pixel-wise classification maps output by deep neural networks are of extreme importance for scene understanding. However, these maps are often partially inaccurate due to a variety of possible factors. Therefore, we propose to interactively refine them within a framework named DISCA (Deep Image Segmentation with Continual Adaptation). It consists of continually adapting a neural network to a target image using an interactive learning process with sparse user annotations as ground-truth. We show through experiments on three datasets using synthesized annotations the benefits of the approach, reaching an IoU improvement up to 4.7% for ten sampled clicks. Finally, we exhibit that our approach can be particularly rewarding when it is faced to additional issues such as domain adaptation.
STaRFlow: A SpatioTemporal Recurrent Cell for Lightweight Multi-Frame Optical Flow Estimation
Jul 10, 2020
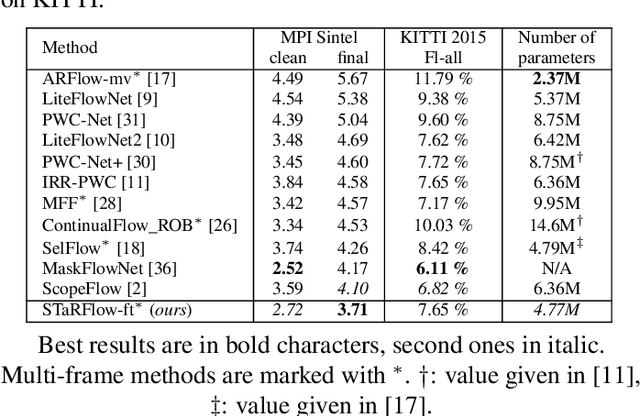
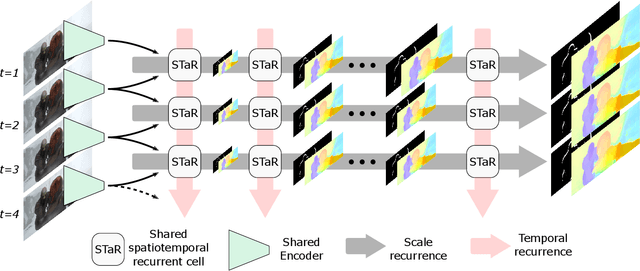
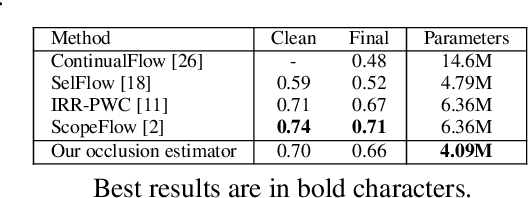
We present a new lightweight CNN-based algorithm for multi-frame optical flow estimation. Our solution introduces a double recurrence over spatial scale and time through repeated use of a generic "STaR" (SpatioTemporal Recurrent) cell. It includes (i) a temporal recurrence based on conveying learned features rather than optical flow estimates; (ii) an occlusion detection process which is coupled with optical flow estimation and therefore uses a very limited number of extra parameters. The resulting STaRFlow algorithm gives state-of-the-art performances on MPI Sintel and Kitti2015 and involves significantly less parameters than all other methods with comparable results.
DISIR: Deep Image Segmentation with Interactive Refinement
Mar 31, 2020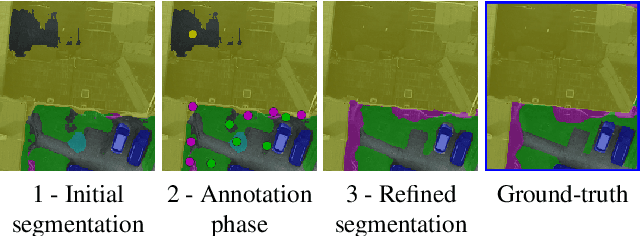
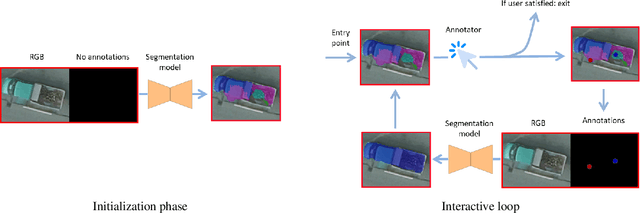

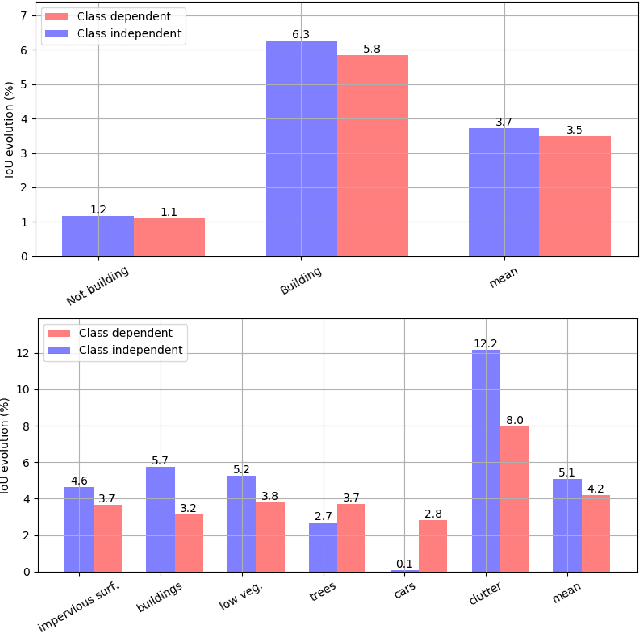
This paper presents an interactive approach for multi-class segmentation of aerial images. Precisely, it is based on a deep neural network which exploits both RGB images and annotations. Starting from an initial output based on the image only, our network then interactively refines this segmentation map using a concatenation of the image and user annotations. Importantly, user annotations modify the inputs of the network - not its weights - enabling a fast and smooth process. Through experiments on two public aerial datasets, we show that user annotations are extremely rewarding: each click corrects roughly 5000 pixels. We analyze the impact of different aspects of our framework such as the representation of the annotations, the volume of training data or the network architecture. Code is available at https://github.com/delair-ai/DISIR.