 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom 2D to 3D: AISG-SLA Visual Localization Challenge
Jul 26, 2024



Research in 3D mapping is crucial for smart city applications, yet the cost of acquiring 3D data often hinders progress. Visual localization, particularly monocular camera position estimation, offers a solution by determining the camera's pose solely through visual cues. However, this task is challenging due to limited data from a single camera. To tackle these challenges, we organized the AISG-SLA Visual Localization Challenge (VLC) at IJCAI 2023 to explore how AI can accurately extract camera pose data from 2D images in 3D space. The challenge attracted over 300 participants worldwide, forming 50+ teams. Winning teams achieved high accuracy in pose estimation using images from a car-mounted camera with low frame rates. The VLC dataset is available for research purposes upon request via vlc-dataset@aisingapore.org.
Eiffel Tower: A Deep-Sea Underwater Dataset for Long-Term Visual Localization
May 09, 2023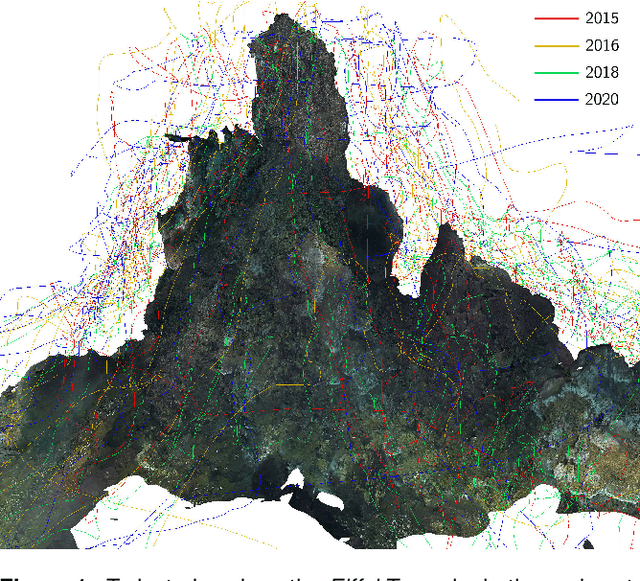

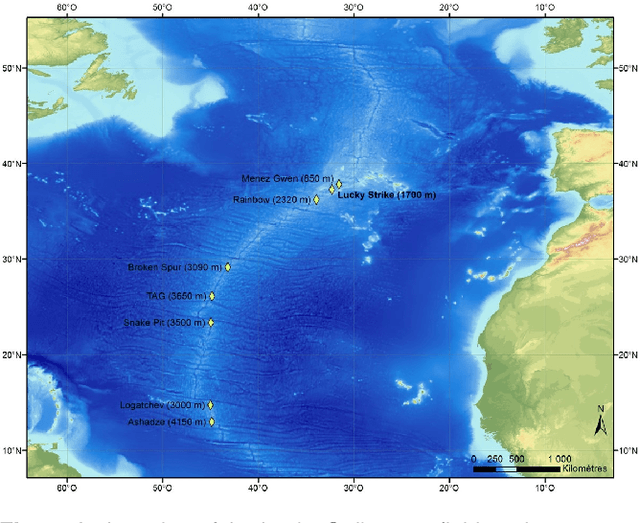

Visual localization plays an important role in the positioning and navigation of robotics systems within previously visited environments. When visits occur over long periods of time, changes in the environment related to seasons or day-night cycles present a major challenge. Under water, the sources of variability are due to other factors such as water conditions or growth of marine organisms. Yet it remains a major obstacle and a much less studied one, partly due to the lack of data. This paper presents a new deep-sea dataset to benchmark underwater long-term visual localization. The dataset is composed of images from four visits to the same hydrothermal vent edifice over the course of five years. Camera poses and a common geometry of the scene were estimated using navigation data and Structure-from-Motion. This serves as a reference when evaluating visual localization techniques. An analysis of the data provides insights about the major changes observed throughout the years. Furthermore, several well-established visual localization methods are evaluated on the dataset, showing there is still room for improvement in underwater long-term visual localization. The data is made publicly available at https://www.seanoe.org/data/00810/92226/.
SUCRe: Leveraging Scene Structure for Underwater Color Restoration
Dec 18, 2022Underwater images are altered by the physical characteristics of the medium through which light rays pass before reaching the optical sensor. Scattering and strong wavelength-dependent absorption significantly modify the captured colors depending on the distance of observed elements to the image plane. In this paper, we aim to recover the original colors of the scene as if the water had no effect on them. We propose two novel methods that rely on different sets of inputs. The first assumes that pixel intensities in the restored image are normally distributed within each color channel, leading to an alternative optimization of the well-known \textit{Sea-thru} method which acts on single images and their distance maps. We additionally introduce SUCRe, a new method that further exploits the scene's 3D Structure for Underwater Color Restoration. By following points in multiple images and tracking their intensities at different distances to the sensor we constrain the optimization of the image formation model parameters. When compared to similar existing approaches, SUCRe provides clear improvements in a variety of scenarios ranging from natural light to deep-sea environments. The code for both approaches is publicly available at https://github.com/clementinboittiaux/sucre .
Hyperspectral 3D Mapping of Underwater Environments
Oct 13, 2021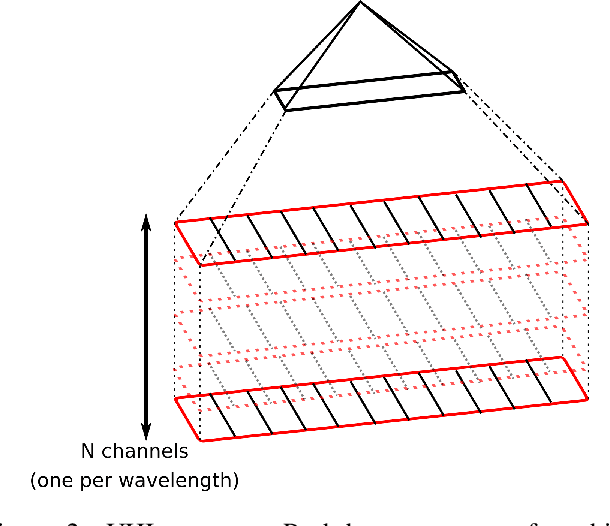

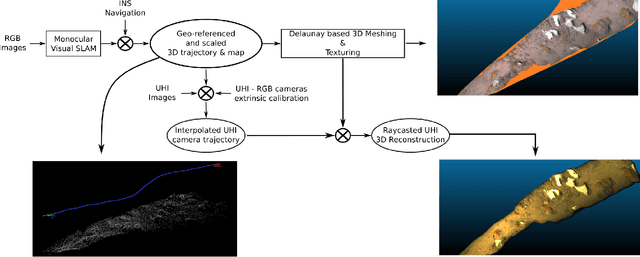

Hyperspectral imaging has been increasingly used for underwater survey applications over the past years. As many hyperspectral cameras work as push-broom scanners, their use is usually limited to the creation of photo-mosaics based on a flat surface approximation and by interpolating the camera pose from dead-reckoning navigation. Yet, because of drift in the navigation and the mostly wrong flat surface assumption, the quality of the obtained photo-mosaics is often too low to support adequate analysis.In this paper we present an initial method for creating hyperspectral 3D reconstructions of underwater environments. By fusing the data gathered by a classical RGB camera, an inertial navigation system and a hyperspectral push-broom camera, we show that the proposed method creates highly accurate 3D reconstructions with hyperspectral textures. We propose to combine techniques from simultaneous localization and mapping, structure-from-motion and 3D reconstruction and advantageously use them to create 3D models with hyperspectral texture, allowing us to overcome the flat surface assumption and the classical limitation of dead-reckoning navigation.
* ICCV'21 - Computer Vision in the Ocean Workshop
OV$^{2}$SLAM : A Fully Online and Versatile Visual SLAM for Real-Time Applications
Feb 08, 2021
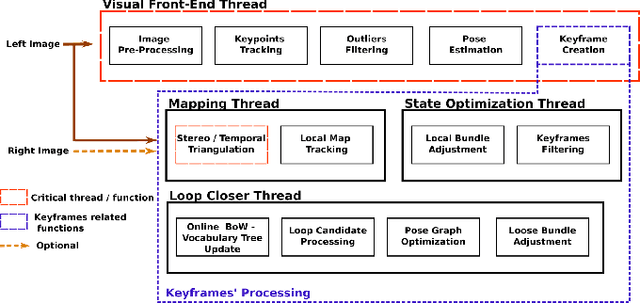
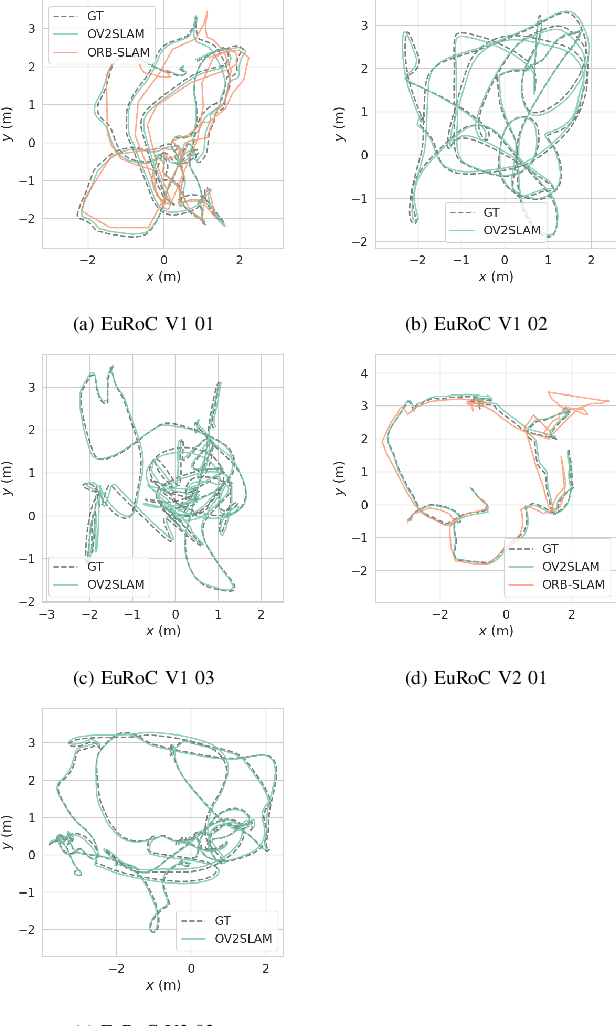
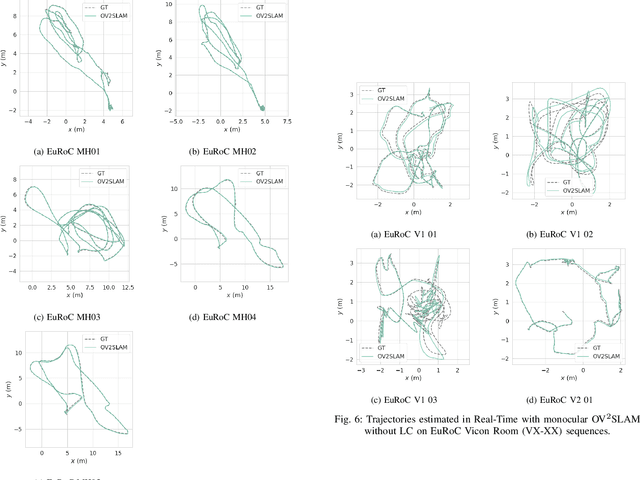
Many applications of Visual SLAM, such as augmented reality, virtual reality, robotics or autonomous driving, require versatile, robust and precise solutions, most often with real-time capability. In this work, we describe OV$^{2}$SLAM, a fully online algorithm, handling both monocular and stereo camera setups, various map scales and frame-rates ranging from a few Hertz up to several hundreds. It combines numerous recent contributions in visual localization within an efficient multi-threaded architecture. Extensive comparisons with competing algorithms shows the state-of-the-art accuracy and real-time performance of the resulting algorithm. For the benefit of the community, we release the source code: \url{https://github.com/ov2slam/ov2slam}.
* Accepted for publication in IEEE Robotics and Automation Letters (RA-L). Code is available at : \url{https://github.com/ov2slam/ov2slam}
Technical Report: Co-learning of geometry and semantics for online 3D mapping
Nov 04, 2019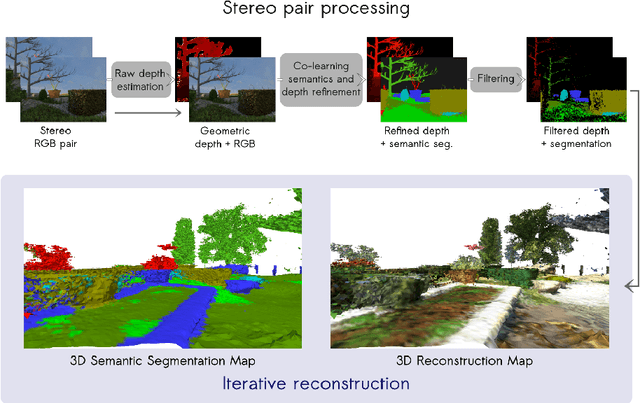

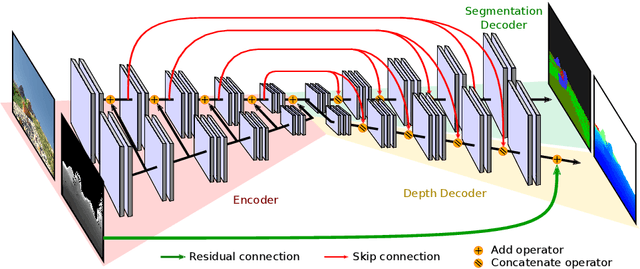
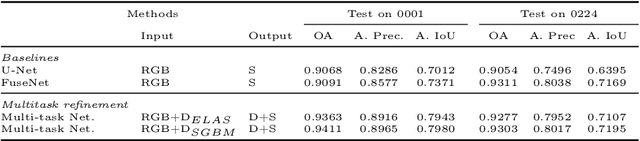
This paper is a technical report about our submission for the ECCV 2018 3DRMS Workshop Challenge on Semantic 3D Reconstruction \cite{Tylecek2018rms}. In this paper, we address 3D semantic reconstruction for autonomous navigation using co-learning of depth map and semantic segmentation. The core of our pipeline is a deep multi-task neural network which tightly refines depth and also produces accurate semantic segmentation maps. Its inputs are an image and a raw depth map produced from a pair of images by standard stereo vision. The resulting semantic 3D point clouds are then merged in order to create a consistent 3D mesh, in turn used to produce dense semantic 3D reconstruction maps. The performances of each step of the proposed method are evaluated on the dataset and multiple tasks of the 3DRMS Challenge, and repeatedly surpass state-of-the-art approaches.
AQUALOC: An Underwater Dataset for Visual-Inertial-Pressure Localization
Oct 31, 2019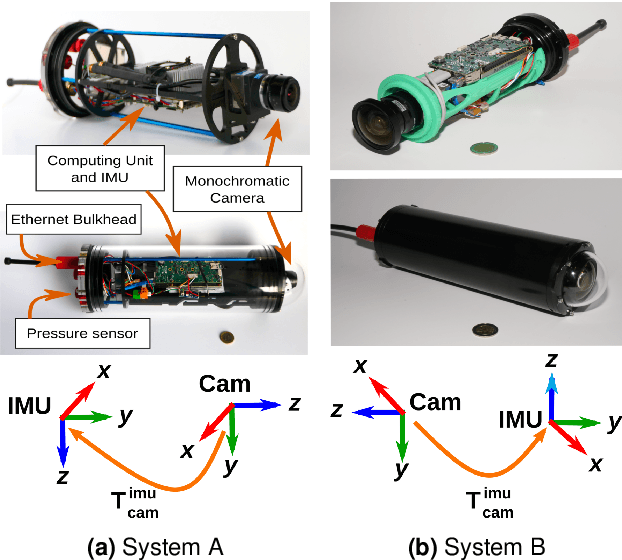


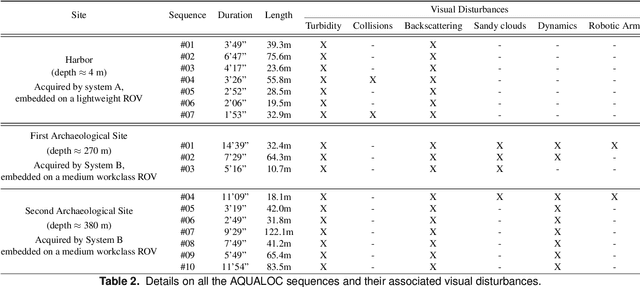
We present a new dataset, dedicated to the development of simultaneous localization and mapping methods for underwater vehicles navigating close to the seabed. The data sequences composing this dataset are recorded in three different environments: a harbor at a depth of a few meters, a first archaeological site at a depth of 270 meters and a second site at a depth of 380 meters. The data acquisition is performed using Remotely Operated Vehicles equipped with a monocular monochromatic camera, a low-cost inertial measurement unit, a pressure sensor and a computing unit, all embedded in a single enclosure. The sensors' measurements are recorded synchronously on the computing unit and seventeen sequences have been created from all the acquired data. These sequences are made available in the form of ROS bags and as raw data. For each sequence, a trajectory has also been computed offline using a Structure-from-Motion library in order to allow the comparison with real-time localization methods. With the release of this dataset, we wish to provide data difficult to acquire and to encourage the development of vision-based localization methods dedicated to the underwater environment. The dataset can be downloaded from: http://www.lirmm.fr/aqualoc/
The Aqualoc Dataset: Towards Real-Time Underwater Localization from a Visual-Inertial-Pressure Acquisition System
Sep 19, 2018


This paper presents a new underwater dataset acquired from a visual-inertial-pressure acquisition system and meant to be used to benchmark visual odometry, visual SLAM and multi-sensors SLAM solutions. The dataset is publicly available and contains ground-truth trajectories for evaluation.
Real-time Monocular Visual Odometry for Turbid and Dynamic Underwater Environments
Jul 03, 2018
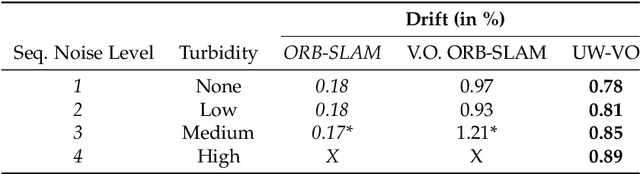


In the context of robotic underwater operations, the visual degradations induced by the medium properties make difficult the exclusive use of cameras for localization purpose. Hence, most localization methods are based on expensive navigational sensors associated with acoustic positioning. On the other hand, visual odometry and visual SLAM have been exhaustively studied for aerial or terrestrial applications, but state-of-the-art algorithms fail underwater. In this paper we tackle the problem of using a simple low-cost camera for underwater localization and propose a new monocular visual odometry method dedicated to the underwater environment. We evaluate different tracking methods and show that optical flow based tracking is more suited to underwater images than classical approaches based on descriptors. We also propose a keyframe-based visual odometry approach highly relying on nonlinear optimization. The proposed algorithm has been assessed on both simulated and real underwater datasets and outperforms state-of-the-art visual SLAM methods under many of the most challenging conditions. The main application of this work is the localization of Remotely Operated Vehicles (ROVs) used for underwater archaeological missions but the developed system can be used in any other applications as long as visual information is available.