 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Doctor-Patient Conversations for Long-form Audio Summarization
Apr 07, 2026Long-context audio reasoning is underserved in both training data and evaluation. Existing benchmarks target short-context tasks, and the open-ended generation tasks most relevant to long-context reasoning pose well-known challenges for automatic evaluation. We propose a synthetic data generation pipeline designed to serve both as a training resource and as a controlled evaluation environment, and instantiate it for first-visit doctor-patient conversations with SOAP note generation as the task. The pipeline has three stages, persona-driven dialogue generation, multi-speaker audio synthesis with overlap/pause modeling, room acoustics, and sound events, and LLM-based reference SOAP note production, built entirely on open-weight models. We release 8,800 synthetic conversations with 1.3k hours of corresponding audio and reference notes. Evaluating current open-weight systems, we find that cascaded approaches still substantially outperform end-to-end models.
On the Use of Self-Supervised Representation Learning for Speaker Diarization and Separation
Dec 17, 2025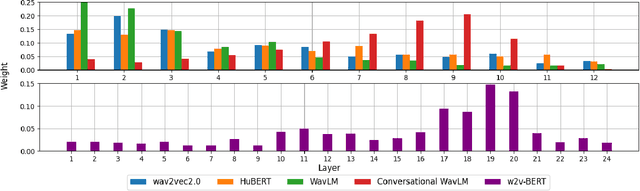

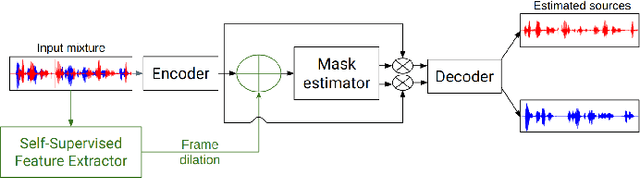

Self-supervised speech models such as wav2vec2.0 and WavLM have been shown to significantly improve the performance of many downstream speech tasks, especially in low-resource settings, over the past few years. Despite this, evaluations on tasks such as Speaker Diarization and Speech Separation remain limited. This paper investigates the quality of recent self-supervised speech representations on these two speaker identity-related tasks, highlighting gaps in the current literature that stem from limitations in the existing benchmarks, particularly the lack of diversity in evaluation datasets and variety in downstream systems associated to both diarization and separation.
SDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
Crossing the Species Divide: Transfer Learning from Speech to Animal Sounds
Sep 04, 2025Self-supervised speech models have demonstrated impressive performance in speech processing, but their effectiveness on non-speech data remains underexplored. We study the transfer learning capabilities of such models on bioacoustic detection and classification tasks. We show that models such as HuBERT, WavLM, and XEUS can generate rich latent representations of animal sounds across taxa. We analyze the models properties with linear probing on time-averaged representations. We then extend the approach to account for the effect of time-wise information with other downstream architectures. Finally, we study the implication of frequency range and noise on performance. Notably, our results are competitive with fine-tuned bioacoustic pre-trained models and show the impact of noise-robust pre-training setups. These findings highlight the potential of speech-based self-supervised learning as an efficient framework for advancing bioacoustic research.
Depth Jitter: Seeing through the Depth
Aug 08, 2025Depth information is essential in computer vision, particularly in underwater imaging, robotics, and autonomous navigation. However, conventional augmentation techniques overlook depth aware transformations, limiting model robustness in real world depth variations. In this paper, we introduce Depth-Jitter, a novel depth-based augmentation technique that simulates natural depth variations to improve generalization. Our approach applies adaptive depth offsetting, guided by depth variance thresholds, to generate synthetic depth perturbations while preserving structural integrity. We evaluate Depth-Jitter on two benchmark datasets, FathomNet and UTDAC2020 demonstrating its impact on model stability under diverse depth conditions. Extensive experiments compare Depth-Jitter against traditional augmentation strategies such as ColorJitter, analyzing performance across varying learning rates, encoders, and loss functions. While Depth-Jitter does not always outperform conventional methods in absolute performance, it consistently enhances model stability and generalization in depth-sensitive environments. These findings highlight the potential of depth-aware augmentation for real-world applications and provide a foundation for further research into depth-based learning strategies. The proposed technique is publicly available to support advancements in depth-aware augmentation. The code is publicly available on \href{https://github.com/mim-team/Depth-Jitter}{github}.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Aligning Multimodal Representations through an Information Bottleneck
Jun 05, 2025Contrastive losses have been extensively used as a tool for multimodal representation learning. However, it has been empirically observed that their use is not effective to learn an aligned representation space. In this paper, we argue that this phenomenon is caused by the presence of modality-specific information in the representation space. Although some of the most widely used contrastive losses maximize the mutual information between representations of both modalities, they are not designed to remove the modality-specific information. We give a theoretical description of this problem through the lens of the Information Bottleneck Principle. We also empirically analyze how different hyperparameters affect the emergence of this phenomenon in a controlled experimental setup. Finally, we propose a regularization term in the loss function that is derived by means of a variational approximation and aims to increase the representational alignment. We analyze in a set of controlled experiments and real-world applications the advantages of including this regularization term.
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025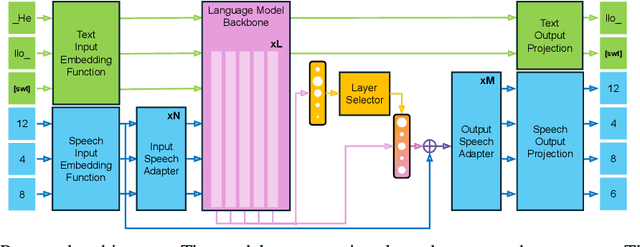
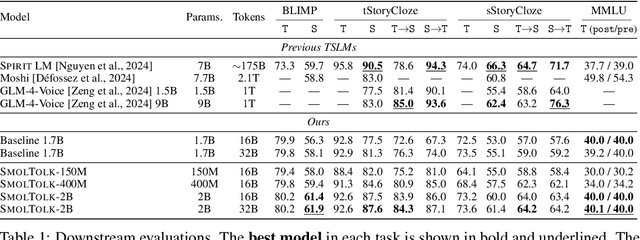
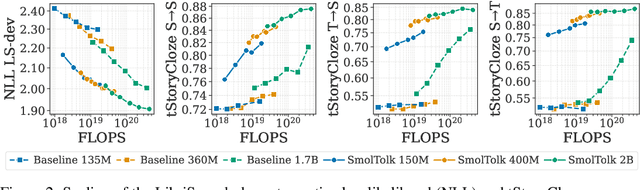
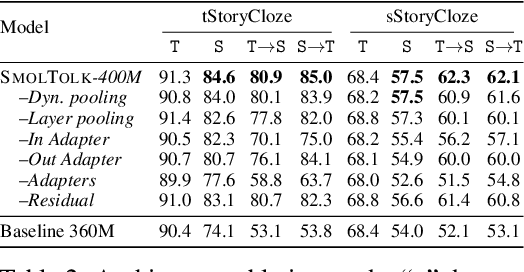
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
TalTech-IRIT-LIS Speaker and Language Diarization Systems for DISPLACE 2024
Jul 17, 2024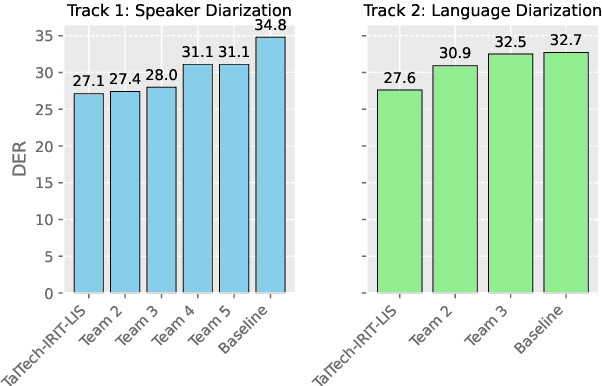
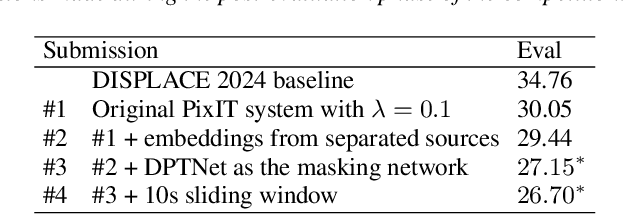


This paper describes the submissions of team TalTech-IRIT-LIS to the DISPLACE 2024 challenge. Our team participated in the speaker diarization and language diarization tracks of the challenge. In the speaker diarization track, our best submission was an ensemble of systems based on the pyannote.audio speaker diarization pipeline utilizing powerset training and our recently proposed PixIT method that performs joint diarization and speech separation. We improve upon PixIT by using the separation outputs for speaker embedding extraction. Our ensemble achieved a diarization error rate of 27.1% on the evaluation dataset. In the language diarization track, we fine-tuned a pre-trained Wav2Vec2-BERT language embedding model on in-domain data, and clustered short segments using AHC and VBx, based on similarity scores from LDA/PLDA. This led to a language diarization error rate of 27.6% on the evaluation data. Both results were ranked first in their respective challenge tracks.