 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalTech-IRIT-LIS Speaker and Language Diarization Systems for DISPLACE 2024
Jul 17, 2024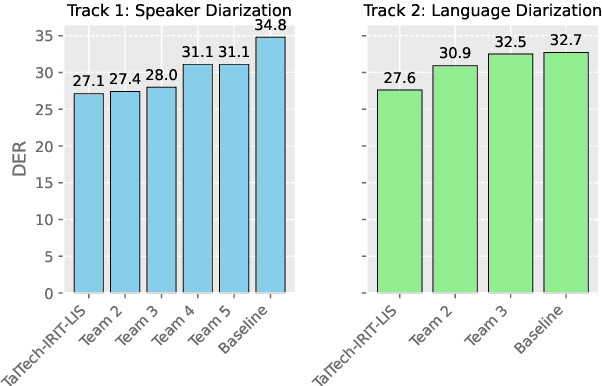


This paper describes the submissions of team TalTech-IRIT-LIS to the DISPLACE 2024 challenge. Our team participated in the speaker diarization and language diarization tracks of the challenge. In the speaker diarization track, our best submission was an ensemble of systems based on the pyannote.audio speaker diarization pipeline utilizing powerset training and our recently proposed PixIT method that performs joint diarization and speech separation. We improve upon PixIT by using the separation outputs for speaker embedding extraction. Our ensemble achieved a diarization error rate of 27.1% on the evaluation dataset. In the language diarization track, we fine-tuned a pre-trained Wav2Vec2-BERT language embedding model on in-domain data, and clustered short segments using AHC and VBx, based on similarity scores from LDA/PLDA. This led to a language diarization error rate of 27.6% on the evaluation data. Both results were ranked first in their respective challenge tracks.
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Mar 04, 2024



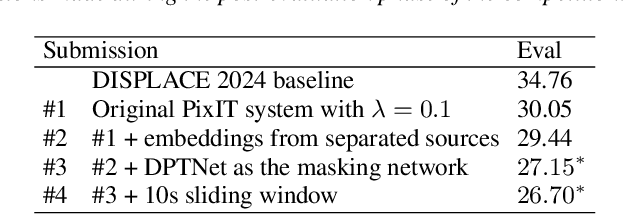
A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
Collar-aware Training for Streaming Speaker Change Detection in Broadcast Speech
May 14, 2022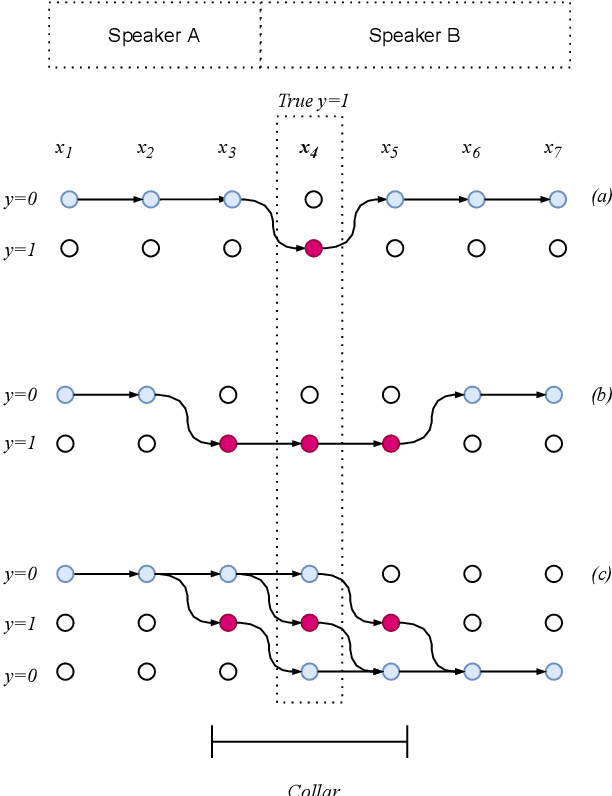
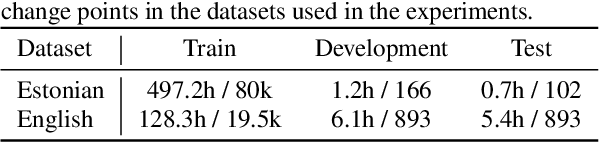

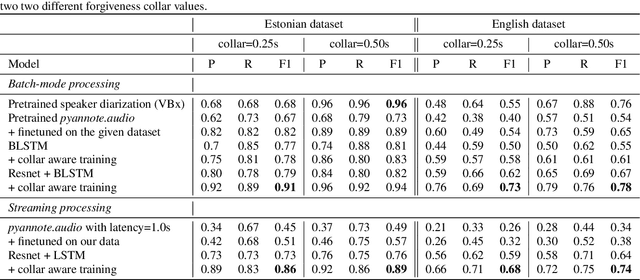
In this paper, we present a novel training method for speaker change detection models. Speaker change detection is often viewed as a binary sequence labelling problem. The main challenges with this approach are the vagueness of annotated change points caused by the silences between speaker turns and imbalanced data due to the majority of frames not including a speaker change. Conventional training methods tackle these by artificially increasing the proportion of positive labels in the training data. Instead, the proposed method uses an objective function which encourages the model to predict a single positive label within a specified collar. This is done by marginalizing over all possible subsequences that have exactly one positive label within the collar. Experiments on English and Estonian datasets show large improvements over the conventional training method. Additionally, the model outputs have peaks concentrated to a single frame, removing the need for post-processing to find the exact predicted change point which is particularly useful for streaming applications.