 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Evidence Fusion for Audio Question Answering
Mar 18, 2026Large audio language models (LALMs) can answer questions about speech, music, and environmental sounds, yet their internal reasoning is largely opaque and difficult to validate. We describe TalTech's solution to the Agent Track of the Interspeech 2026 Audio Reasoning Challenge, in which systems are evaluated on reasoning process quality, specifically the factual accuracy, logical soundness, and completeness of their reasoning chains. Our multi-source ensemble pipeline uses two LALMs that generate independent observations, while a separate text-only reasoning model cross-checks these against outputs from 25 acoustic tools organized into reliability tiers. By grounding every inference step in explicit, reliability-tagged evidence, the system produces dense, verifiable reasoning chains. Our system ranked first in the challenge, outperforming all competing systems by a wide margin in challenge's reasoning quality metric.
EstLLM: Enhancing Estonian Capabilities in Multilingual LLMs via Continued Pretraining and Post-Training
Mar 02, 2026Large language models (LLMs) are predominantly trained on English-centric data, resulting in uneven performance for smaller languages. We study whether continued pretraining (CPT) can substantially improve Estonian capabilities in a pretrained multilingual LLM while preserving its English and general reasoning performance. Using Llama 3.1 8B as the main base model, we perform CPT on a mixture that increases Estonian exposure while approximating the original training distribution through English replay and the inclusion of code, mathematics, and instruction-like data. We subsequently apply supervised fine-tuning, preference optimization, and chat vector merging to introduce robust instruction-following behavior. Evaluation on a comprehensive suite of Estonian benchmarks shows consistent gains in linguistic competence, knowledge, reasoning, translation quality, and instruction-following compared to the original base model and its instruction-tuned variant, while maintaining competitive performance on English benchmarks. These findings indicate that CPT, with an appropriately balanced data mixture, together with post-training alignment, can substantially improve single-language capabilities in pretrained multilingual LLMs.
Optimizing Estonian TV Subtitles with Semi-supervised Learning and LLMs
Jan 09, 2025



This paper presents an approach for generating high-quality, same-language subtitles for Estonian TV content. We fine-tune the Whisper model on human-generated Estonian subtitles and enhance it with iterative pseudo-labeling and large language model (LLM) based post-editing. Our experiments demonstrate notable subtitle quality improvement through pseudo-labeling with an unlabeled dataset. We find that applying LLM-based editing at test time enhances subtitle accuracy, while its use during training does not yield further gains. This approach holds promise for creating subtitle quality close to human standard and could be extended to real-time applications.
TalTech-IRIT-LIS Speaker and Language Diarization Systems for DISPLACE 2024
Jul 17, 2024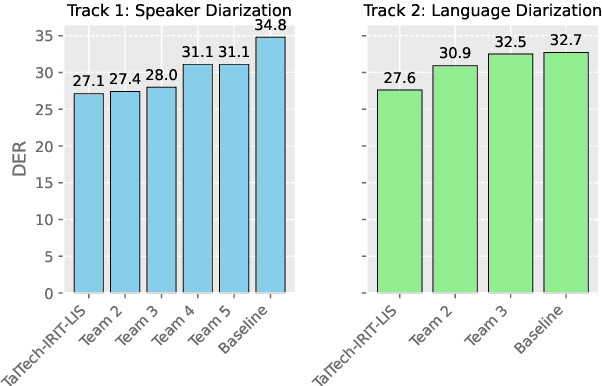


This paper describes the submissions of team TalTech-IRIT-LIS to the DISPLACE 2024 challenge. Our team participated in the speaker diarization and language diarization tracks of the challenge. In the speaker diarization track, our best submission was an ensemble of systems based on the pyannote.audio speaker diarization pipeline utilizing powerset training and our recently proposed PixIT method that performs joint diarization and speech separation. We improve upon PixIT by using the separation outputs for speaker embedding extraction. Our ensemble achieved a diarization error rate of 27.1% on the evaluation dataset. In the language diarization track, we fine-tuned a pre-trained Wav2Vec2-BERT language embedding model on in-domain data, and clustered short segments using AHC and VBx, based on similarity scores from LDA/PLDA. This led to a language diarization error rate of 27.6% on the evaluation data. Both results were ranked first in their respective challenge tracks.
Finetuning End-to-End Models for Estonian Conversational Spoken Language Translation
Jul 04, 2024



This paper investigates the finetuning of end-to-end models for bidirectional Estonian-English and Estonian-Russian conversational speech-to-text translation. Due to the limited availability of speech translation data for Estonian, we created additional training data by web scraping and synthesizing data from speech recognition datasets using machine translation. We evaluated three publicly available end-to-end models: Whisper, OWSM 3.1, and SeamlessM4T. Our results indicate that fine-tuning with synthetic data enhances translation accuracy by a large margin, with SeamlessM4T matching or surpassing cascaded speech translation systems that use state-of-the-art speech recognition and machine translation models.
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Mar 04, 2024



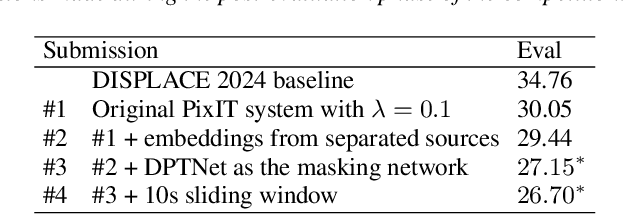
A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
Dialect Adaptation and Data Augmentation for Low-Resource ASR: TalTech Systems for the MADASR 2023 Challenge
Oct 26, 2023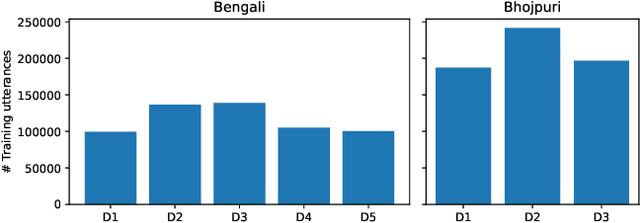
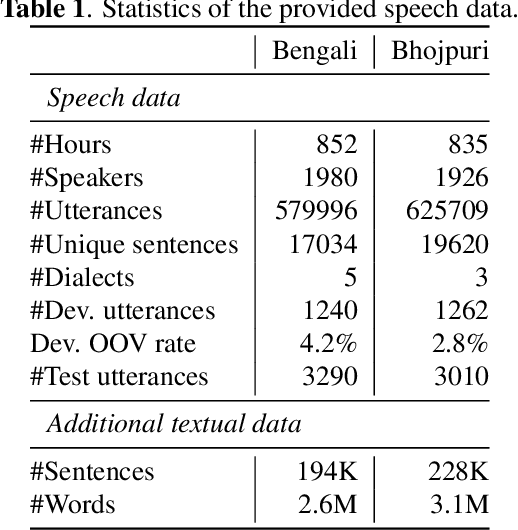

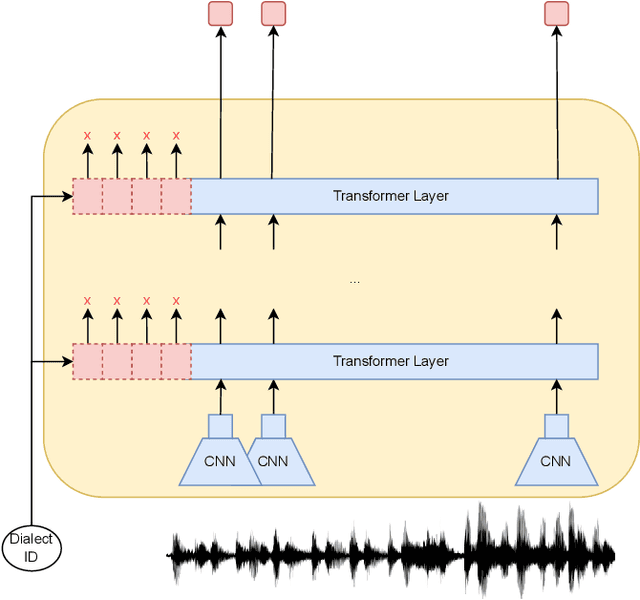
This paper describes Tallinn University of Technology (TalTech) systems developed for the ASRU MADASR 2023 Challenge. The challenge focuses on automatic speech recognition of dialect-rich Indian languages with limited training audio and text data. TalTech participated in two tracks of the challenge: Track 1 that allowed using only the provided training data and Track 3 which allowed using additional audio data. In both tracks, we relied on wav2vec2.0 models. Our methodology diverges from the traditional procedure of finetuning pretrained wav2vec2.0 models in two key points: firstly, through the implementation of the aligned data augmentation technique to enhance the linguistic diversity of the training data, and secondly, via the application of deep prefix tuning for dialect adaptation of wav2vec2.0 models. In both tracks, our approach yielded significant improvements over the provided baselines, achieving the lowest word error rates across all participating teams.
Collar-aware Training for Streaming Speaker Change Detection in Broadcast Speech
May 14, 2022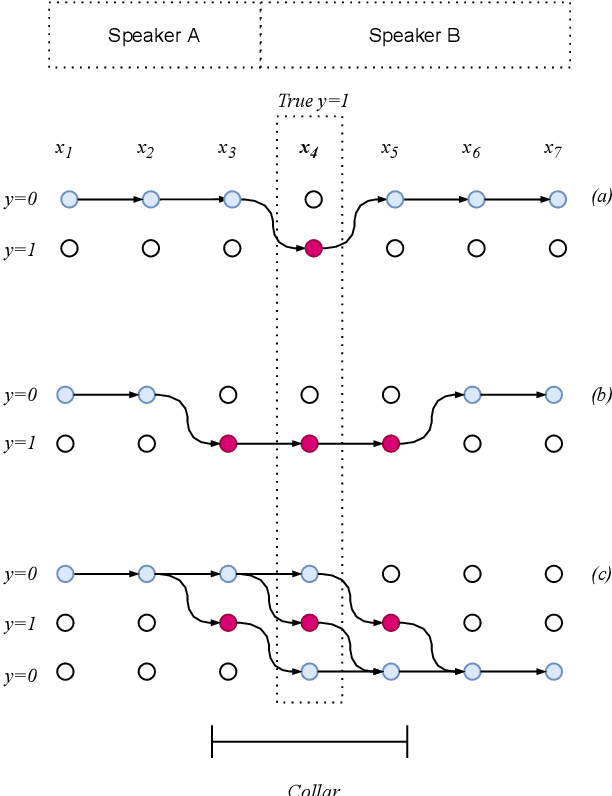
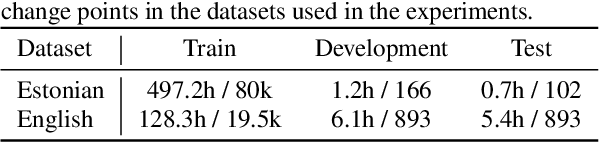

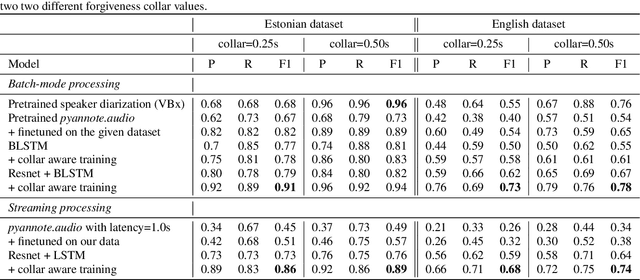
In this paper, we present a novel training method for speaker change detection models. Speaker change detection is often viewed as a binary sequence labelling problem. The main challenges with this approach are the vagueness of annotated change points caused by the silences between speaker turns and imbalanced data due to the majority of frames not including a speaker change. Conventional training methods tackle these by artificially increasing the proportion of positive labels in the training data. Instead, the proposed method uses an objective function which encourages the model to predict a single positive label within a specified collar. This is done by marginalizing over all possible subsequences that have exactly one positive label within the collar. Experiments on English and Estonian datasets show large improvements over the conventional training method. Additionally, the model outputs have peaks concentrated to a single frame, removing the need for post-processing to find the exact predicted change point which is particularly useful for streaming applications.
Pretraining Approaches for Spoken Language Recognition: TalTech Submission to the OLR 2021 Challenge
May 14, 2022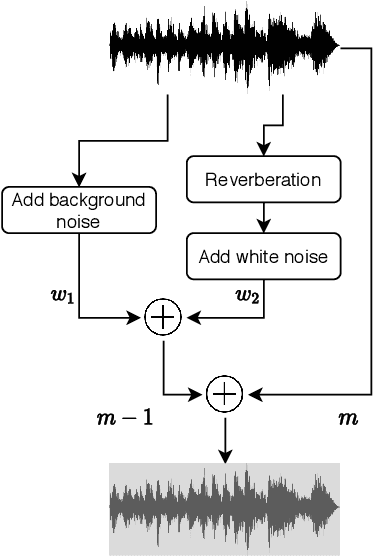
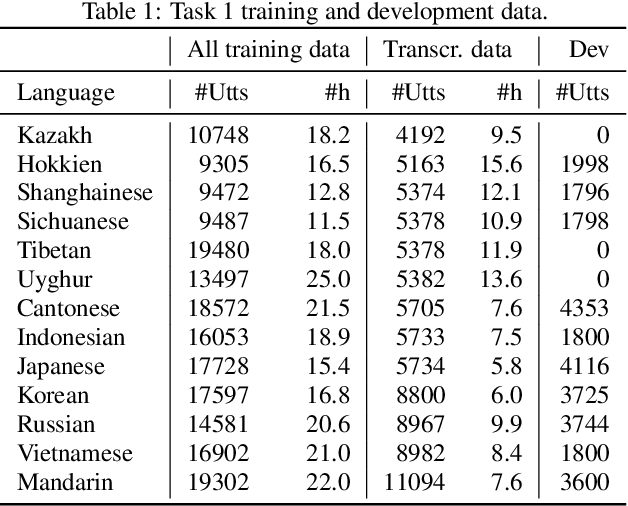
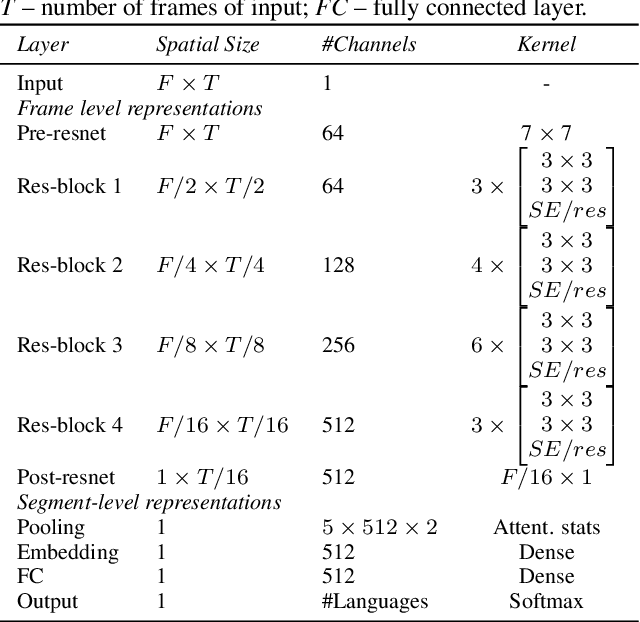
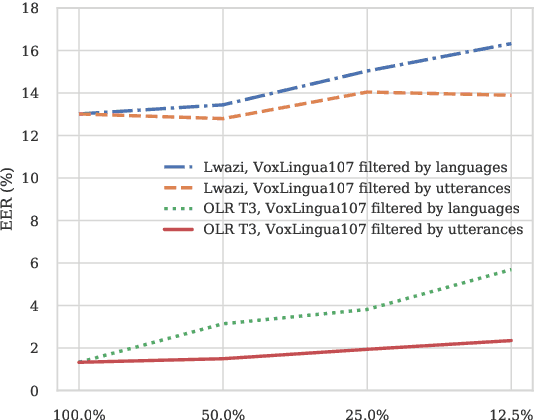
This paper investigates different pretraining approaches to spoken language identification. The paper is based on our submission to the Oriental Language Recognition 2021 Challenge. We participated in two tracks of the challenge: constrained and unconstrained language recognition. For the constrained track, we first trained a Conformer-based encoder-decoder model for multilingual automatic speech recognition (ASR), using the provided training data that had transcripts available. The shared encoder of the multilingual ASR model was then finetuned for the language identification task. For the unconstrained task, we relied on both externally available pretrained models as well as external data: the multilingual XLSR-53 wav2vec2.0 model was finetuned on the VoxLingua107 corpus for the language recognition task, and finally finetuned on the provided target language training data, augmented with CommonVoice data. Our primary metric $C_{\rm avg}$ values on the Test set are 0.0079 for the constrained task and 0.0119 for the unconstrained task which resulted in the second place in both rankings. In post-evaluation experiments, we study the amount of target language data needed for training an accurate backend model, the importance of multilingual pretraining data, and compare different models as finetuning starting points.
Improving Language Identification of Accented Speech
Apr 01, 2022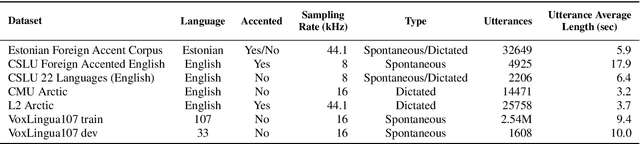
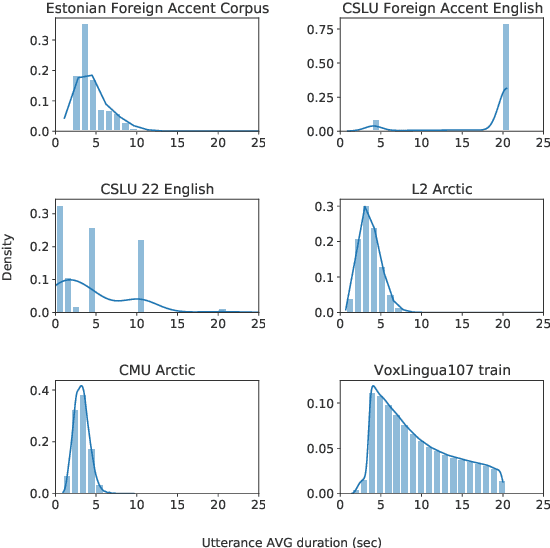
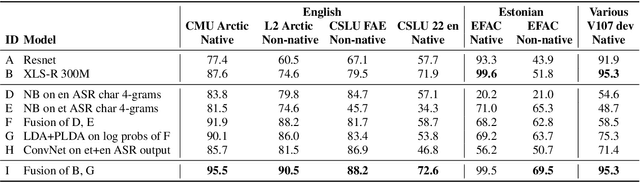
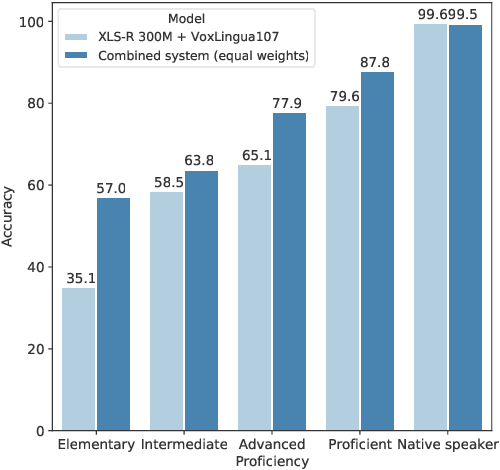
Language identification from speech is a common preprocessing step in many spoken language processing systems. In recent years, this field has seen a fast progress, mostly due to the use of self-supervised models pretrained on multilingual data and the use of large training corpora. This paper shows that for speech with a non-native or regional accent, the accuracy of spoken language identification systems drops dramatically, and that the accuracy of identifying the language is inversely correlated with the strength of the accent. We also show that using the output of a lexicon-free speech recognition system of the particular language helps to improve language identification performance on accented speech by a large margin, without sacrificing accuracy on native speech. We obtain relative error rate reductions ranging from to 35 to 63% over the state-of-the-art model across several non-native speech datasets.