 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialect Adaptation and Data Augmentation for Low-Resource ASR: TalTech Systems for the MADASR 2023 Challenge
Oct 26, 2023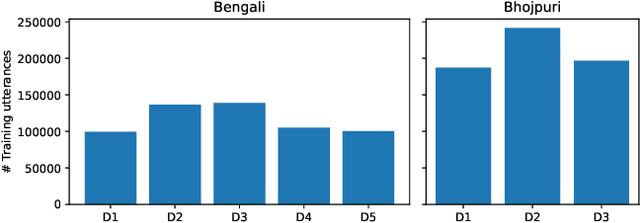
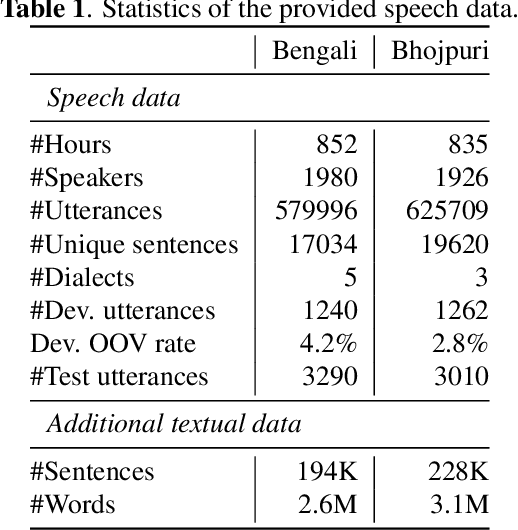

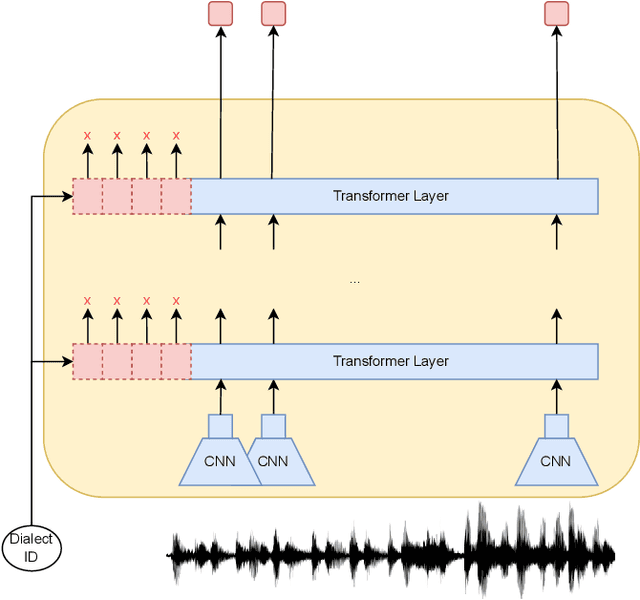
This paper describes Tallinn University of Technology (TalTech) systems developed for the ASRU MADASR 2023 Challenge. The challenge focuses on automatic speech recognition of dialect-rich Indian languages with limited training audio and text data. TalTech participated in two tracks of the challenge: Track 1 that allowed using only the provided training data and Track 3 which allowed using additional audio data. In both tracks, we relied on wav2vec2.0 models. Our methodology diverges from the traditional procedure of finetuning pretrained wav2vec2.0 models in two key points: firstly, through the implementation of the aligned data augmentation technique to enhance the linguistic diversity of the training data, and secondly, via the application of deep prefix tuning for dialect adaptation of wav2vec2.0 models. In both tracks, our approach yielded significant improvements over the provided baselines, achieving the lowest word error rates across all participating teams.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.