 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreliminary Report: Enhancing Role Differentiation in Conversational HCI Through Chromostereopsis
Mar 05, 2025We propose leveraging chromostereopsis, a perceptual phenomenon inducing depth perception through color contrast, as a novel approach to visually differentiating conversational roles in text-based AI interfaces. This method aims to implicitly communicate role hierarchy and add a subtle sense of physical space.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Technical notes: Syntax-aware Representation Learning With Pointer Networks
Mar 17, 2019

This is a work-in-progress report, which aims to share preliminary results of a novel sequence-to-sequence schema for dependency parsing that relies on a combination of a BiLSTM and two Pointer Networks (Vinyals et al., 2015), in which the final softmax function has been replaced with the logistic regression. The two pointer networks co-operate to develop a latent syntactic knowledge, by learning the lexical properties of "selection" and the lexical properties of "selectability", respectively. At the moment and without fine-tuning, the parser implementation gets a UAS of 93.14% on the English Penn-treebank (Marcus et al., 1993) annotated with Stanford Dependencies: 2-3% under the SOTA but yet attractive as a baseline of the approach.
Non-Projective Dependency Parsing via Latent Heads Representation (LHR)
Feb 06, 2018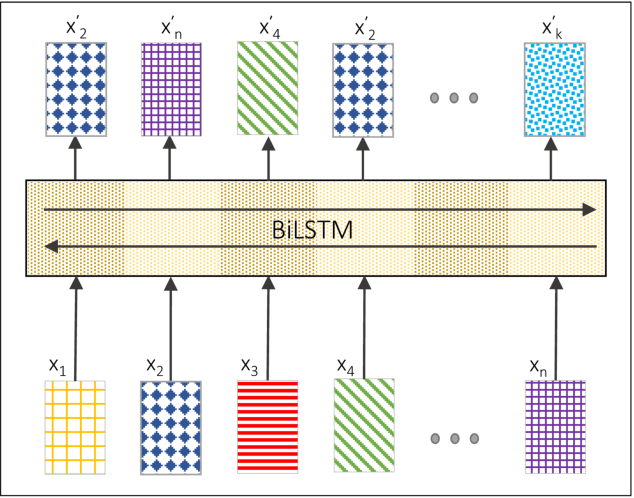

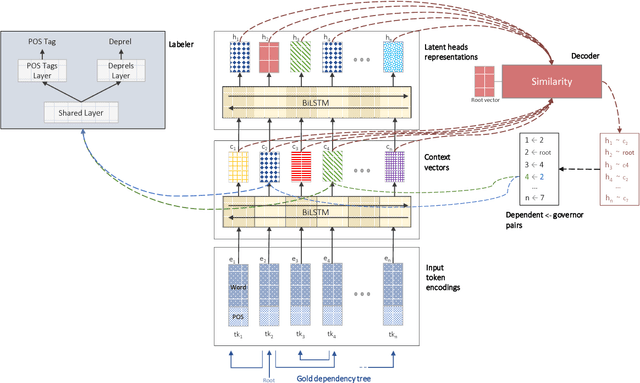
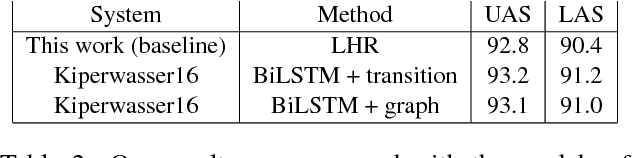
In this paper, we introduce a novel approach based on a bidirectional recurrent autoencoder to perform globally optimized non-projective dependency parsing via semi-supervised learning. The syntactic analysis is completed at the end of the neural process that generates a Latent Heads Representation (LHR), without any algorithmic constraint and with a linear complexity. The resulting "latent syntactic structure" can be used directly in other semantic tasks. The LHR is transformed into the usual dependency tree computing a simple vectors similarity. We believe that our model has the potential to compete with much more complex state-of-the-art parsing architectures.
Notes About a More Aware Dependency Parser
Jul 20, 2015In this paper I explain the reasons that led me to research and conceive a novel technology for dependency parsing, mixing together the strengths of data-driven transition-based and constraint-based approaches. In particular I highlight the problem to infer the reliability of the results of a data-driven transition-based parser, which is extremely important for high-level processes that expect to use correct parsing results. I then briefly introduce a number of notes about a new parser model I'm working on, capable to proceed with the analysis in a "more aware" way, with a more "robust" concept of robustness.