 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated test generation to evaluate tool-augmented LLMs as conversational AI agents
Sep 24, 2024Tool-augmented LLMs are a promising approach to create AI agents that can have realistic conversations, follow procedures, and call appropriate functions. However, evaluating them is challenging due to the diversity of possible conversations, and existing datasets focus only on single interactions and function-calling. We present a test generation pipeline to evaluate LLMs as conversational AI agents. Our framework uses LLMs to generate diverse tests grounded on user-defined procedures. For that, we use intermediate graphs to limit the LLM test generator's tendency to hallucinate content that is not grounded on input procedures, and enforces high coverage of the possible conversations. Additionally, we put forward ALMITA, a manually curated dataset for evaluating AI agents in customer support, and use it to evaluate existing LLMs. Our results show that while tool-augmented LLMs perform well in single interactions, they often struggle to handle complete conversations. While our focus is on customer support, our method is general and capable of AI agents for different domains.
Natural language to SQL in low-code platforms
Aug 29, 2023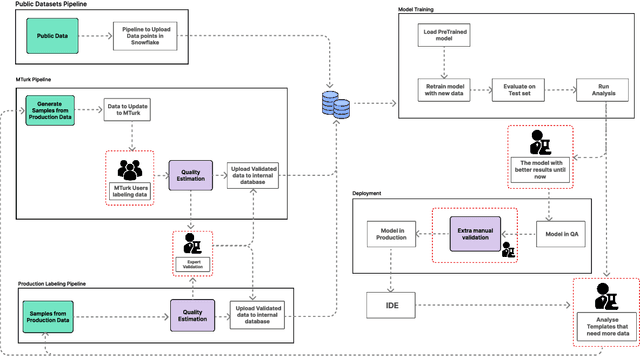
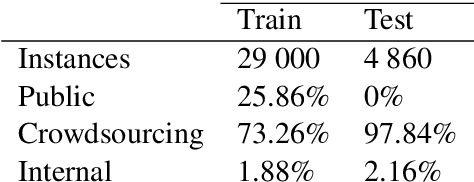
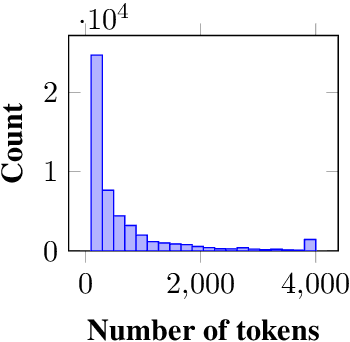
One of the developers' biggest challenges in low-code platforms is retrieving data from a database using SQL queries. Here, we propose a pipeline allowing developers to write natural language (NL) to retrieve data. In this study, we collect, label, and validate data covering the SQL queries most often performed by OutSystems users. We use that data to train a NL model that generates SQL. Alongside this, we describe the entire pipeline, which comprises a feedback loop that allows us to quickly collect production data and use it to retrain our SQL generation model. Using crowd-sourcing, we collect 26k NL and SQL pairs and obtain an additional 1k pairs from production data. Finally, we develop a UI that allows developers to input a NL query in a prompt and receive a user-friendly representation of the resulting SQL query. We use A/B testing to compare four different models in production and observe a 240% improvement in terms of adoption of the feature, 220% in terms of engagement rate, and a 90% decrease in failure rate when compared against the first model that we put into production, showcasing the effectiveness of our pipeline in continuously improving our feature.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
T5QL: Taming language models for SQL generation
Sep 21, 2022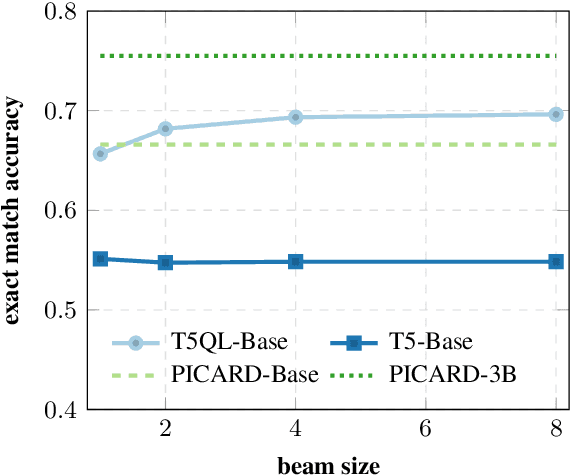
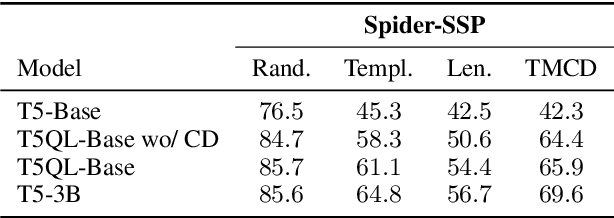
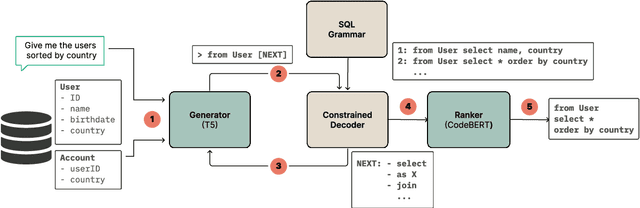
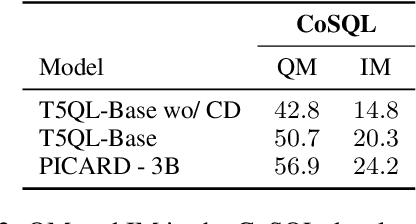
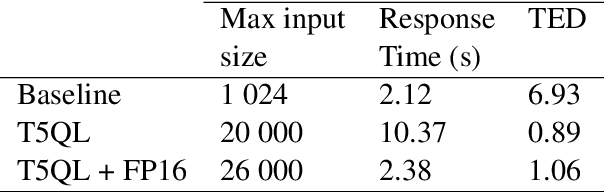
Automatic SQL generation has been an active research area, aiming at streamlining the access to databases by writing natural language with the given intent instead of writing SQL. Current SOTA methods for semantic parsing depend on LLMs to achieve high predictive accuracy on benchmark datasets. This reduces their applicability, since LLMs requires expensive GPUs. Furthermore, SOTA methods are ungrounded and thus not guaranteed to always generate valid SQL. Here we propose T5QL, a new SQL generation method that improves the performance in benchmark datasets when using smaller LMs, namely T5-Base, by 13pp when compared against SOTA methods. Additionally, T5QL is guaranteed to always output valid SQL using a context-free grammar to constrain SQL generation. Finally, we show that dividing semantic parsing in two tasks, candidate SQLs generation and candidate re-ranking, is a promising research avenue that can reduce the need for large LMs.
Time Series Imputation
Mar 22, 2019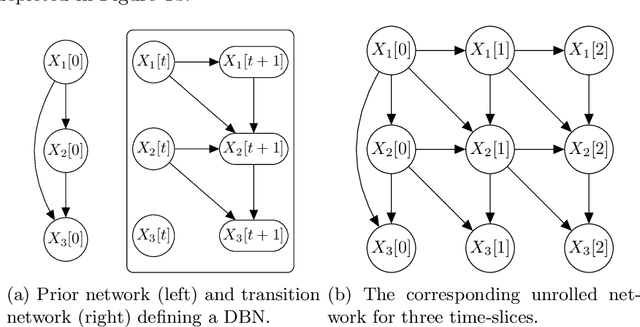
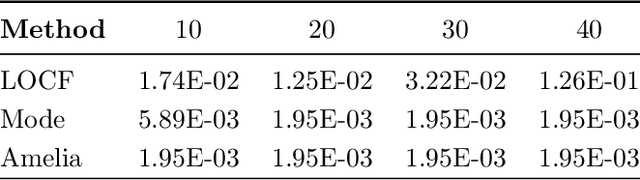
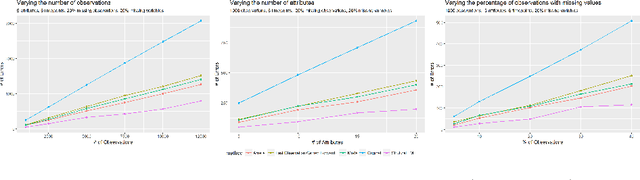
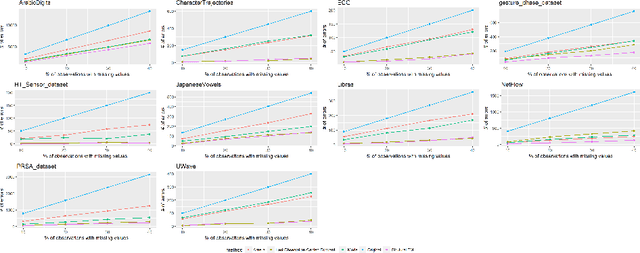
Multivariate time series is a very active topic in the research community and many machine learning tasks are being used in order to extract information from this type of data. However, in real-world problems data has missing values, which may difficult the application of machine learning techniques to extract information. In this paper we focus on the task of imputation of time series. Many imputation methods for time series are based on regression methods. Unfortunately, these methods perform poorly when the variables are categorical. To address this case, we propose a new imputation method based on Expectation Maximization over dynamic Bayesian networks. The approach is assessed with synthetic and real data, and it outperforms several state-of-the art methods.