 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Graph-Sprints: Accelerated Representation Learning in Continuous-Time Dynamic Graphs
Jul 10, 2024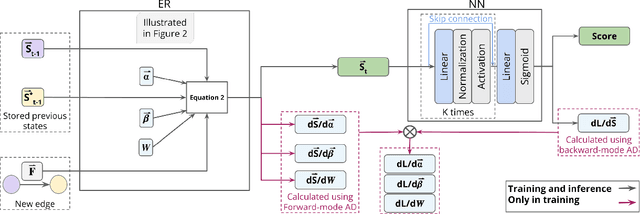



Continuous-time dynamic graphs (CTDGs) are essential for modeling interconnected, evolving systems. Traditional methods for extracting knowledge from these graphs often depend on feature engineering or deep learning. Feature engineering is limited by the manual and time-intensive nature of crafting features, while deep learning approaches suffer from high inference latency, making them impractical for real-time applications. This paper introduces Deep-Graph-Sprints (DGS), a novel deep learning architecture designed for efficient representation learning on CTDGs with low-latency inference requirements. We benchmark DGS against state-of-the-art feature engineering and graph neural network methods using five diverse datasets. The results indicate that DGS achieves competitive performance while improving inference speed up to 12x compared to other deep learning approaches on our tested benchmarks. Our method effectively bridges the gap between deep representation learning and low-latency application requirements for CTDGs.
Natural language to SQL in low-code platforms
Aug 29, 2023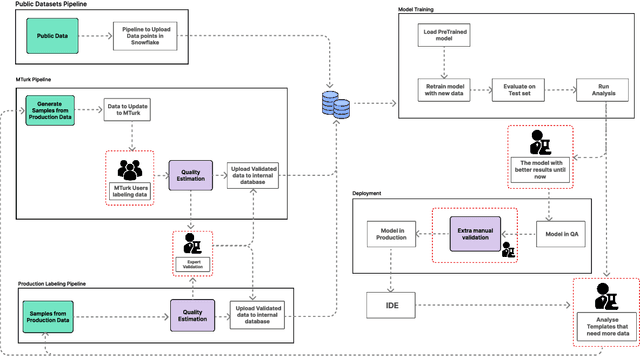
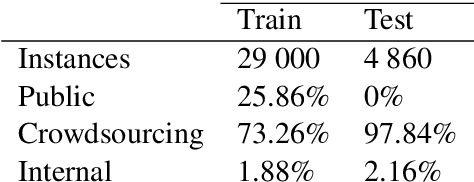
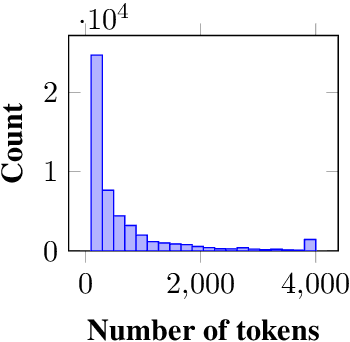
One of the developers' biggest challenges in low-code platforms is retrieving data from a database using SQL queries. Here, we propose a pipeline allowing developers to write natural language (NL) to retrieve data. In this study, we collect, label, and validate data covering the SQL queries most often performed by OutSystems users. We use that data to train a NL model that generates SQL. Alongside this, we describe the entire pipeline, which comprises a feedback loop that allows us to quickly collect production data and use it to retrain our SQL generation model. Using crowd-sourcing, we collect 26k NL and SQL pairs and obtain an additional 1k pairs from production data. Finally, we develop a UI that allows developers to input a NL query in a prompt and receive a user-friendly representation of the resulting SQL query. We use A/B testing to compare four different models in production and observe a 240% improvement in terms of adoption of the feature, 220% in terms of engagement rate, and a 90% decrease in failure rate when compared against the first model that we put into production, showcasing the effectiveness of our pipeline in continuously improving our feature.
The GANfather: Controllable generation of malicious activity to improve defence systems
Jul 25, 2023
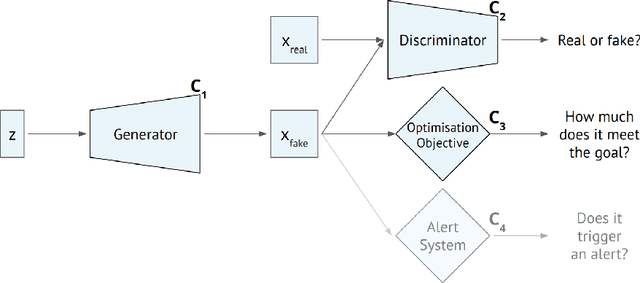
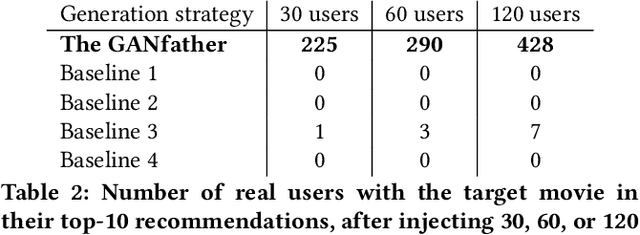
Machine learning methods to aid defence systems in detecting malicious activity typically rely on labelled data. In some domains, such labelled data is unavailable or incomplete. In practice this can lead to low detection rates and high false positive rates, which characterise for example anti-money laundering systems. In fact, it is estimated that 1.7--4 trillion euros are laundered annually and go undetected. We propose The GANfather, a method to generate samples with properties of malicious activity, without label requirements. We propose to reward the generation of malicious samples by introducing an extra objective to the typical Generative Adversarial Networks (GANs) loss. Ultimately, our goal is to enhance the detection of illicit activity using the discriminator network as a novel and robust defence system. Optionally, we may encourage the generator to bypass pre-existing detection systems. This setup then reveals defensive weaknesses for the discriminator to correct. We evaluate our method in two real-world use cases, money laundering and recommendation systems. In the former, our method moves cumulative amounts close to 350 thousand dollars through a network of accounts without being detected by an existing system. In the latter, we recommend the target item to a broad user base with as few as 30 synthetic attackers. In both cases, we train a new defence system to capture the synthetic attacks.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023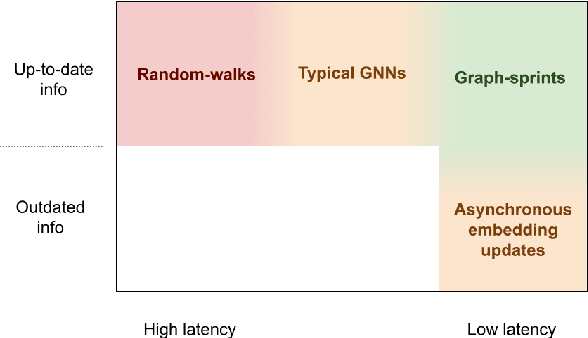

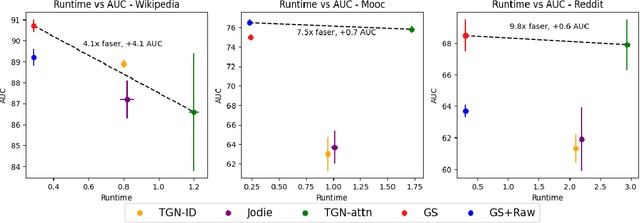

Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.
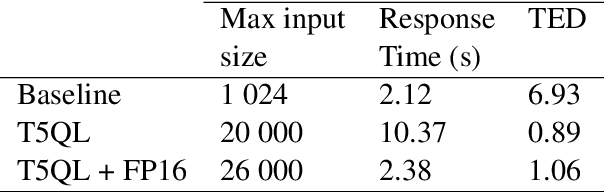
T5QL: Taming language models for SQL generation
Sep 21, 2022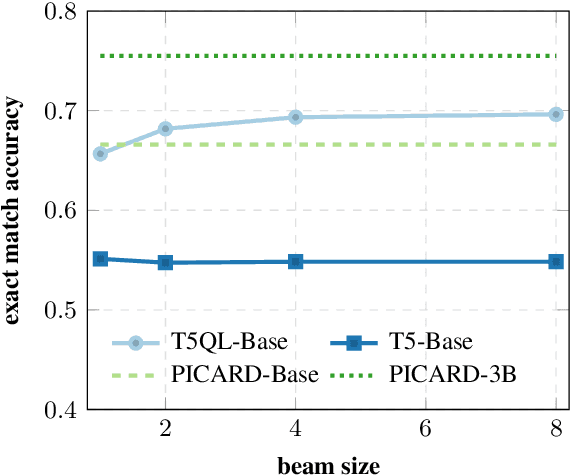
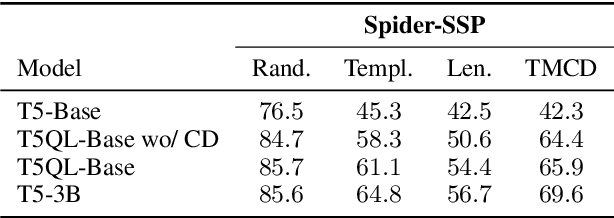
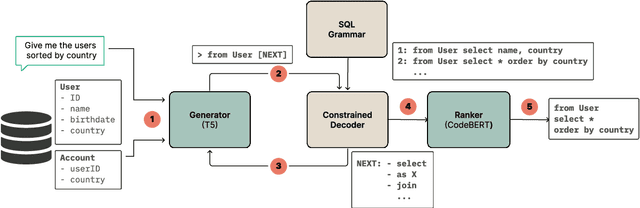
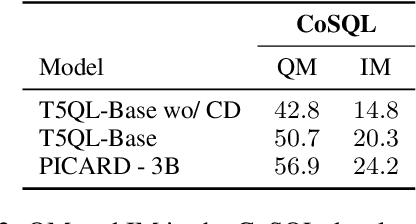
Automatic SQL generation has been an active research area, aiming at streamlining the access to databases by writing natural language with the given intent instead of writing SQL. Current SOTA methods for semantic parsing depend on LLMs to achieve high predictive accuracy on benchmark datasets. This reduces their applicability, since LLMs requires expensive GPUs. Furthermore, SOTA methods are ungrounded and thus not guaranteed to always generate valid SQL. Here we propose T5QL, a new SQL generation method that improves the performance in benchmark datasets when using smaller LMs, namely T5-Base, by 13pp when compared against SOTA methods. Additionally, T5QL is guaranteed to always output valid SQL using a context-free grammar to constrain SQL generation. Finally, we show that dividing semantic parsing in two tasks, candidate SQLs generation and candidate re-ranking, is a promising research avenue that can reduce the need for large LMs.
Anti-Money Laundering Alert Optimization Using Machine Learning with Graphs
Dec 14, 2021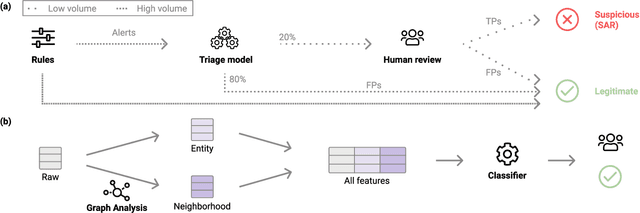

Money laundering is a global problem that concerns legitimizing proceeds from serious felonies (1.7-4 trillion euros annually) such as drug dealing, human trafficking, or corruption. The anti-money laundering systems deployed by financial institutions typically comprise rules aligned with regulatory frameworks. Human investigators review the alerts and report suspicious cases. Such systems suffer from high false-positive rates, undermining their effectiveness and resulting in high operational costs. We propose a machine learning triage model, which complements the rule-based system and learns to predict the risk of an alert accurately. Our model uses both entity-centric engineered features and attributes characterizing inter-entity relations in the form of graph-based features. We leverage time windows to construct the dynamic graph, optimizing for time and space efficiency. We validate our model on a real-world banking dataset and show how the triage model can reduce the number of false positives by 80% while detecting over 90% of true positives. In this way, our model can significantly improve anti-money laundering operations.
GuiltyWalker: Distance to illicit nodes in the Bitcoin network
Feb 10, 2021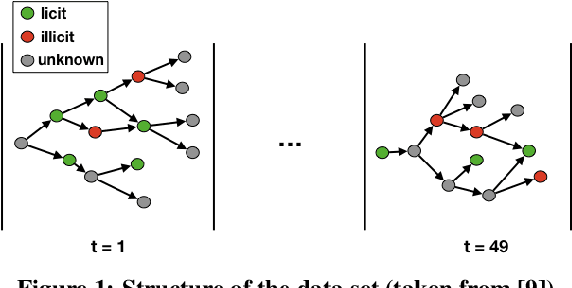
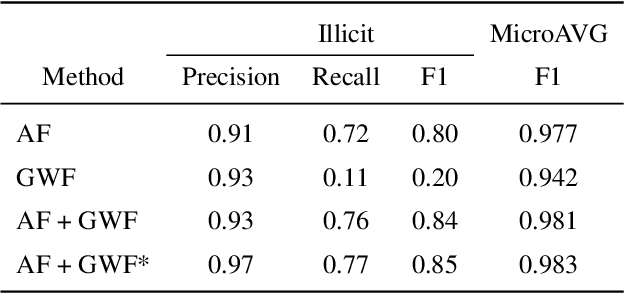
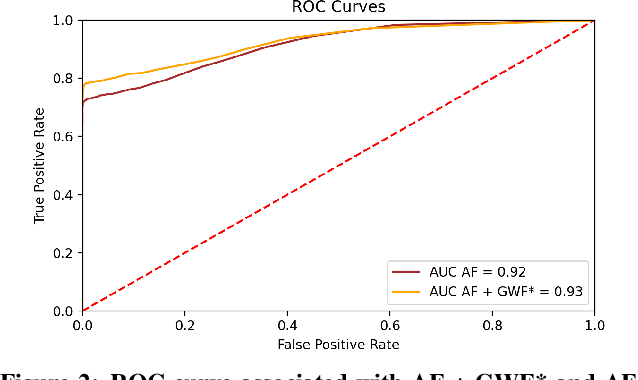
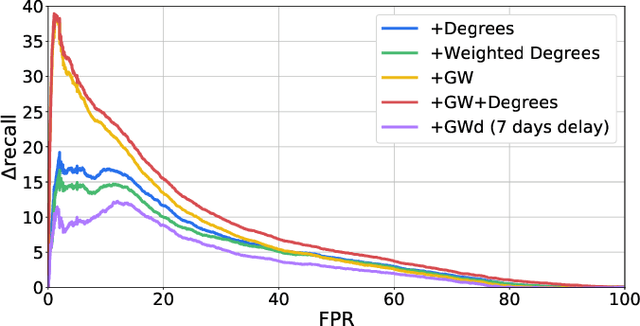
Money laundering is a global phenomenon with wide-reaching social and economic consequences. Cryptocurrencies are particularly susceptible due to the lack of control by authorities and their anonymity. Thus, it is important to develop new techniques to detect and prevent illicit cryptocurrency transactions. In our work, we propose new features based on the structure of the graph and past labels to boost the performance of machine learning methods to detect money laundering. Our method, GuiltyWalker, performs random walks on the bitcoin transaction graph and computes features based on the distance to illicit transactions. We combine these new features with features proposed by Weber et al. and observe an improvement of about 5pp regarding illicit classification. Namely, we observe that our proposed features are particularly helpful during a black market shutdown, where the algorithm by Weber et al. was low performing.
Machine learning methods to detect money laundering in the Bitcoin blockchain in the presence of label scarcity
May 29, 2020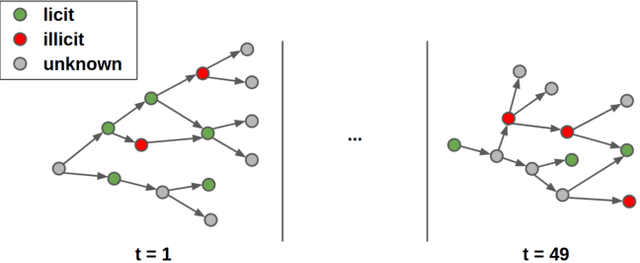
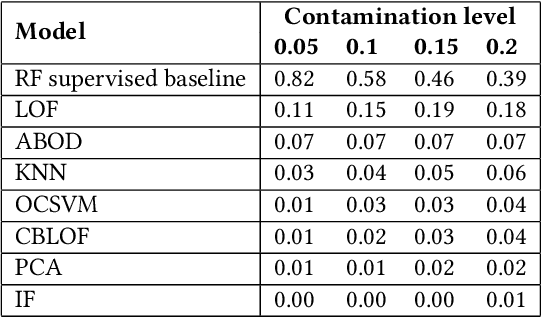
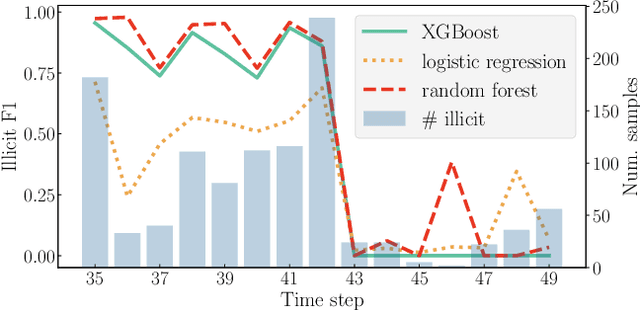
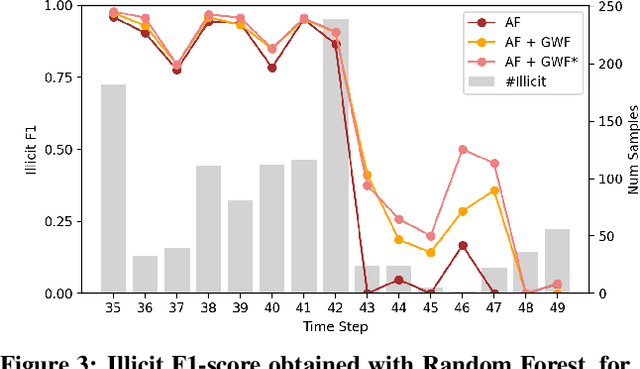
Every year, criminals launder billions of dollars acquired from serious felonies (e.g., terrorism, drug smuggling, or human trafficking) harming countless people and economies. Cryptocurrencies, in particular, have developed as a haven for money laundering activity. Machine Learning can be used to detect these illicit patterns. However, labels are so scarce that traditional supervised algorithms are inapplicable. Here, we address money laundering detection assuming minimal access to labels. First, we show that existing state-of-the-art solutions using unsupervised anomaly detection methods are inadequate to detect the illicit patterns in a real Bitcoin transaction dataset. Then, we show that our proposed active learning solution is capable of matching the performance of a fully supervised baseline by using just 5\% of the labels. This solution mimics a typical real-life situation in which a limited number of labels can be acquired through manual annotation by experts.
ARMS: Automated rules management system for fraud detection
Feb 14, 2020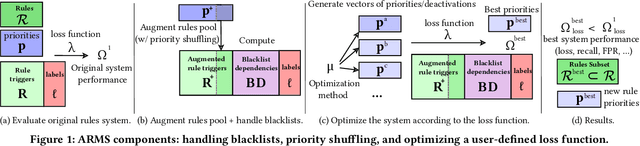
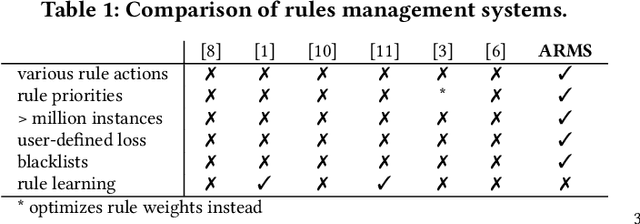
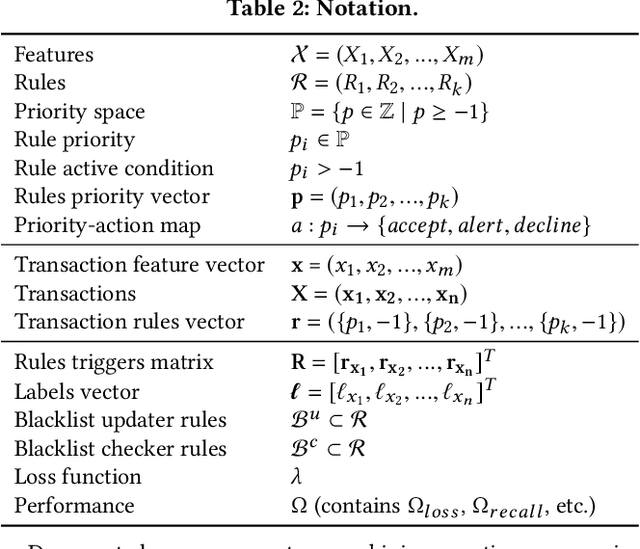
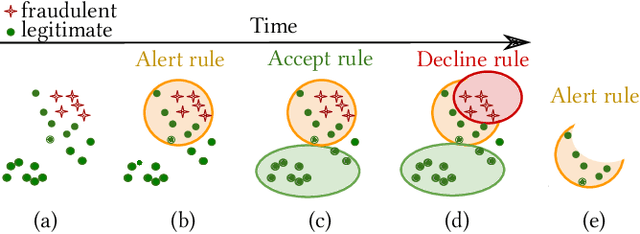
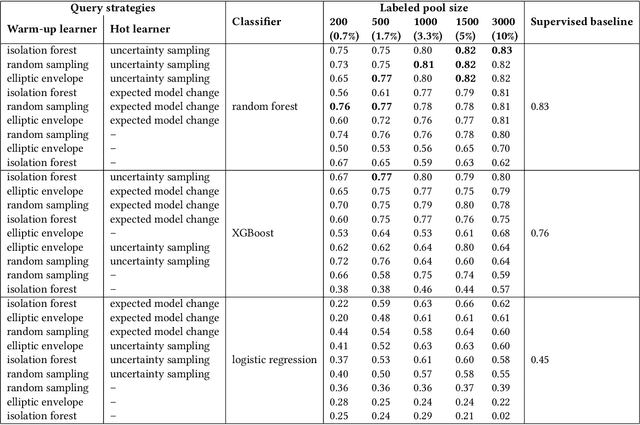
Fraud detection is essential in financial services, with the potential of greatly reducing criminal activities and saving considerable resources for businesses and customers. We address online fraud detection, which consists of classifying incoming transactions as either legitimate or fraudulent in real-time. Modern fraud detection systems consist of a machine learning model and rules defined by human experts. Often, the rules performance degrades over time due to concept drift, especially of adversarial nature. Furthermore, they can be costly to maintain, either because they are computationally expensive or because they send transactions for manual review. We propose ARMS, an automated rules management system that evaluates the contribution of individual rules and optimizes the set of active rules using heuristic search and a user-defined loss-function. It complies with critical domain-specific requirements, such as handling different actions (e.g., accept, alert, and decline), priorities, blacklists, and large datasets (i.e., hundreds of rules and millions of transactions). We use ARMS to optimize the rule-based systems of two real-world clients. Results show that it can maintain the original systems' performance (e.g., recall, or false-positive rate) using only a fraction of the original rules (~ 50% in one case, and ~ 20% in the other).
GoT-WAVE: Temporal network alignment using graphlet-orbit transitions
Aug 24, 2018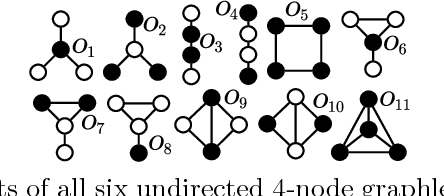

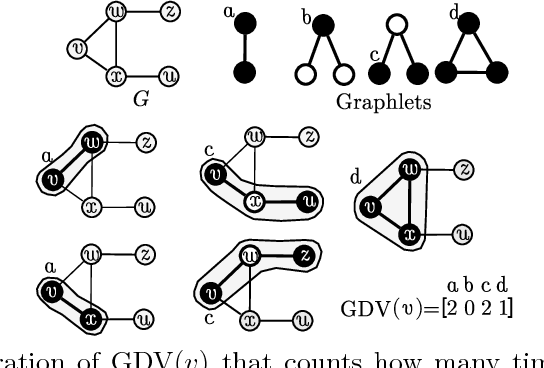
Global pairwise network alignment (GPNA) aims to find a one-to-one node mapping between two networks that identifies conserved network regions. GPNA algorithms optimize node conservation (NC) and edge conservation (EC). NC quantifies topological similarity between nodes. Graphlet-based degree vectors (GDVs) are a state-of-the-art topological NC measure. Dynamic GDVs (DGDVs) were used as a dynamic NC measure within the first-ever algorithms for GPNA of temporal networks: DynaMAGNA++ and DynaWAVE. The latter is superior for larger networks. We recently developed a different graphlet-based measure of temporal node similarity, graphlet-orbit transitions (GoTs). Here, we use GoTs instead of DGDVs as a new dynamic NC measure within DynaWAVE, resulting in a new approach, GoT-WAVE. On synthetic networks, GoT-WAVE improves DynaWAVE's accuracy by 25% and speed by 64%. On real networks, when optimizing only dynamic NC, each method is superior ~50% of the time. While DynaWAVE benefits more from also optimizing dynamic EC, only GoT-WAVE can support directed edges. Hence, GoT-WAVE is a promising new temporal GPNA algorithm, which efficiently optimizes dynamic NC. Future work on better incorporating dynamic EC may yield further improvements.