 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher-Student Perspective on the Dynamics of Learning Near the Optimal Point
Dec 17, 2025Near an optimal learning point of a neural network, the learning performance of gradient descent dynamics is dictated by the Hessian matrix of the loss function with respect to the network parameters. We characterize the Hessian eigenspectrum for some classes of teacher-student problems, when the teacher and student networks have matching weights, showing that the smaller eigenvalues of the Hessian determine long-time learning performance. For linear networks, we analytically establish that for large networks the spectrum asymptotically follows a convolution of a scaled chi-square distribution with a scaled Marchenko-Pastur distribution. We numerically analyse the Hessian spectrum for polynomial and other non-linear networks. Furthermore, we show that the rank of the Hessian matrix can be seen as an effective number of parameters for networks using polynomial activation functions. For a generic non-linear activation function, such as the error function, we empirically observe that the Hessian matrix is always full rank.
A Verification Methodology for Safety Assurance of Robotic Autonomous Systems
Jun 24, 2025Autonomous robots deployed in shared human environments, such as agricultural settings, require rigorous safety assurance to meet both functional reliability and regulatory compliance. These systems must operate in dynamic, unstructured environments, interact safely with humans, and respond effectively to a wide range of potential hazards. This paper presents a verification workflow for the safety assurance of an autonomous agricultural robot, covering the entire development life-cycle, from concept study and design to runtime verification. The outlined methodology begins with a systematic hazard analysis and risk assessment to identify potential risks and derive corresponding safety requirements. A formal model of the safety controller is then developed to capture its behaviour and verify that the controller satisfies the specified safety properties with respect to these requirements. The proposed approach is demonstrated on a field robot operating in an agricultural setting. The results show that the methodology can be effectively used to verify safety-critical properties and facilitate the early identification of design issues, contributing to the development of safer robots and autonomous systems.
A Framework Leveraging Large Language Models for Autonomous UAV Control in Flying Networks
Jun 04, 2025

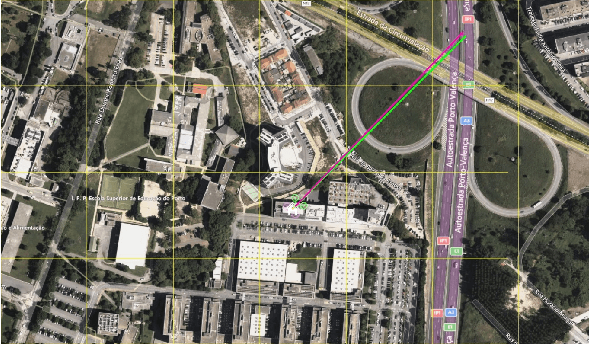
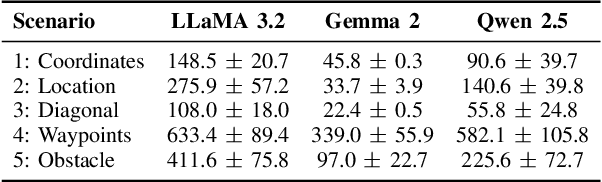
This paper proposes FLUC, a modular framework that integrates open-source Large Language Models (LLMs) with Unmanned Aerial Vehicle (UAV) autopilot systems to enable autonomous control in Flying Networks (FNs). FLUC translates high-level natural language commands into executable UAV mission code, bridging the gap between operator intent and UAV behaviour. FLUC is evaluated using three open-source LLMs - Qwen 2.5, Gemma 2, and LLaMA 3.2 - across scenarios involving code generation and mission planning. Results show that Qwen 2.5 excels in multi-step reasoning, Gemma 2 balances accuracy and latency, and LLaMA 3.2 offers faster responses with lower logical coherence. A case study on energy-aware UAV positioning confirms FLUC's ability to interpret structured prompts and autonomously execute domain-specific logic, showing its effectiveness in real-time, mission-driven control.
Model Checking and Verification of Synchronisation Properties of Cobot Welding
Nov 21, 2024
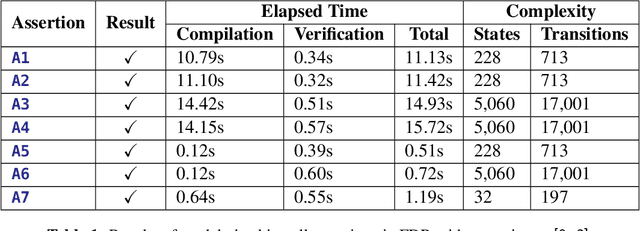

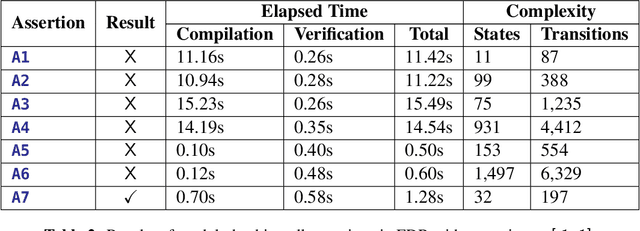
This paper describes use of model checking to verify synchronisation properties of an industrial welding system consisting of a cobot arm and an external turntable. The robots must move synchronously, but sometimes get out of synchronisation, giving rise to unsatisfactory weld qualities in problem areas, such as around corners. These mistakes are costly, since time is lost both in the robotic welding and in manual repairs needed to improve the weld. Verification of the synchronisation properties has shown that they are fulfilled as long as assumptions of correctness made about parts outside the scope of the model hold, indicating limitations in the hardware. These results have indicated the source of the problem, and motivated a re-calibration of the real-life system. This has drastically improved the welding results, and is a demonstration of how formal methods can be useful in an industrial setting.
* In Proceedings FMAS2024, arXiv:2411.13215
Deep-Graph-Sprints: Accelerated Representation Learning in Continuous-Time Dynamic Graphs
Jul 10, 2024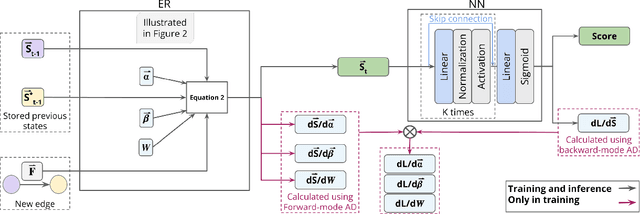



Continuous-time dynamic graphs (CTDGs) are essential for modeling interconnected, evolving systems. Traditional methods for extracting knowledge from these graphs often depend on feature engineering or deep learning. Feature engineering is limited by the manual and time-intensive nature of crafting features, while deep learning approaches suffer from high inference latency, making them impractical for real-time applications. This paper introduces Deep-Graph-Sprints (DGS), a novel deep learning architecture designed for efficient representation learning on CTDGs with low-latency inference requirements. We benchmark DGS against state-of-the-art feature engineering and graph neural network methods using five diverse datasets. The results indicate that DGS achieves competitive performance while improving inference speed up to 12x compared to other deep learning approaches on our tested benchmarks. Our method effectively bridges the gap between deep representation learning and low-latency application requirements for CTDGs.
On the Energy Consumption of Rotary Wing and Fixed Wing UAVs in Flying Networks
Jun 27, 2024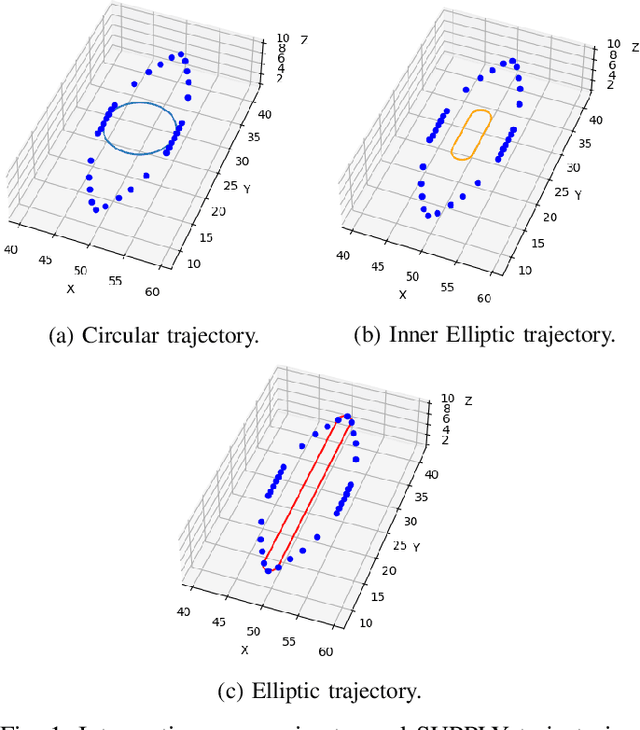
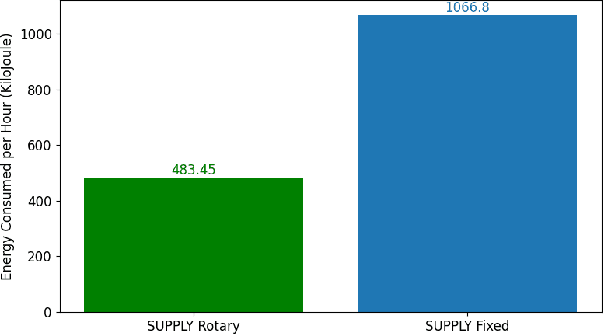
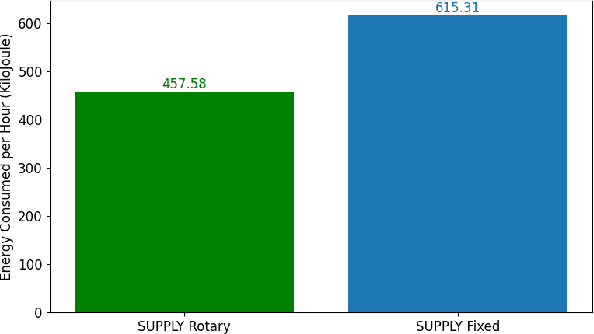
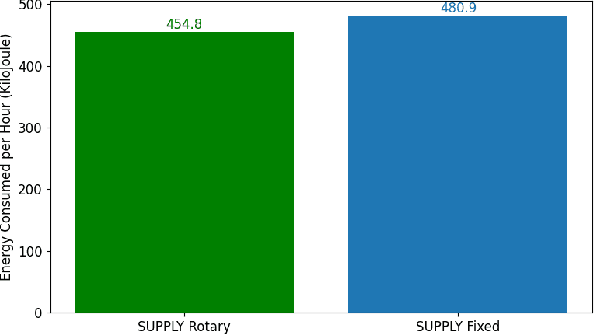
Unmanned Aerial Vehicles (UAVs) are increasingly used to enable wireless communications. Due to their characteristics, such as the ability to hover and carry cargo, UAVs can serve as communications nodes, including Wi-Fi Access Points and Cellular Base Stations. In previous work, we proposed the Sustainable multi-UAV Performance-aware Placement (SUPPLY) algorithm, which focuses on the energy-efficient placement of multiple UAVs acting as Flying Access Points (FAPs). Additionally, we developed the Multi-UAV Energy Consumption (MUAVE) simulator to evaluate the UAV energy consumption, specifically when using the SUPPLY algorithm. However, MUAVE was initially designed to compute the energy consumption for rotary-wing UAVs only. In this paper, we propose eMUAVE, an enhanced version of the MUAVE simulator that allows the evaluation of the energy consumption for both rotary-wing and fixed-wing UAVs. Our energy consumption evaluation using eMUAVE considers reference and random networking scenarios. The results show that fixed-wing UAVs can be employed in the majority of networking scenarios. However, rotary-wing UAVs are typically more energy-efficient than fixed-wing UAVs when following the trajectories defined by SUPPLY.
SUPPLY: Sustainable multi-UAV Performance-aware Placement Algorithm for Flying Networks
Apr 09, 2024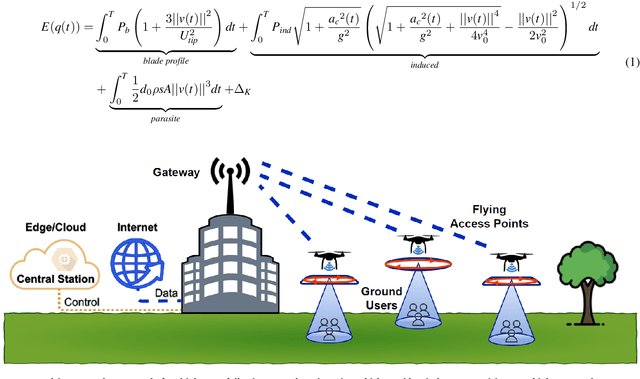
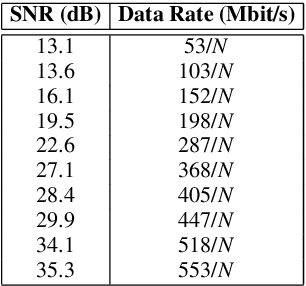
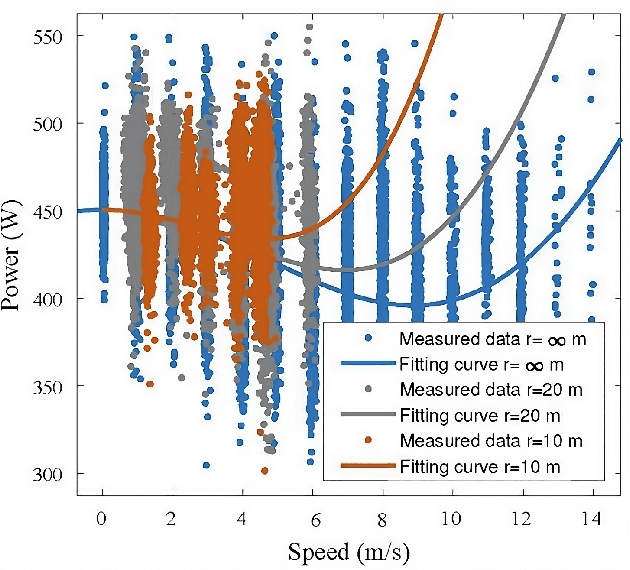
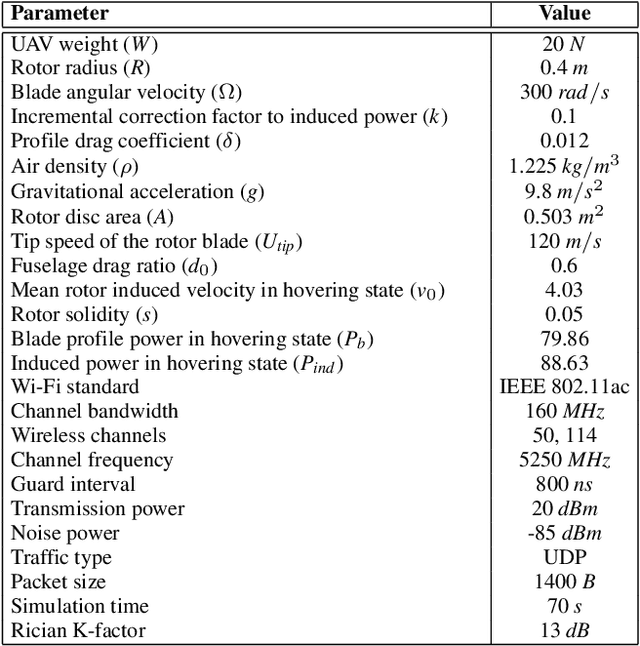
Unmanned Aerial Vehicles (UAVs) are used for a wide range of applications. Due to characteristics such as the ability to hover and carry cargo on-board, rotary-wing UAVs have been considered suitable platforms for carrying communications nodes, including Wi-Fi Access Points and cellular Base Stations. This gave rise to the concept of Flying Networks (FNs), now making part of the so-called Non-Terrestrial Networks (NTNs) defined in 3GPP. In scenarios where the deployment of terrestrial networks is not feasible, the use of FNs has emerged as a solution to provide wireless connectivity. However, the management of the communications resources in FNs imposes significant challenges, especially regarding the positioning of the UAVs so that the Quality of Service (QoS) offered to the Ground Users (GUs) and devices is maximized. Moreover, unlike terrestrial networks that are directly connected to the power grid, UAVs typically rely on on-board batteries that need to be recharged. In order to maximize the UAVs' flying time, the energy consumed by the UAVs needs to be minimized. When it comes to multi-UAV placement, most state-of-the-art solutions focus on maximizing the coverage area and assume that the UAVs keep hovering in a fixed position while serving GUs. Also, they do not address the energy-aware multi-UAV placement problem in networking scenarios where the GUs may have different QoS requirements and may not be uniformly distributed across the area of interest. In this work, we propose the Sustainable multi-UAV Performance-aware Placement (SUPPLY) algorithm. SUPPLY defines the energy and performance-aware positioning of multiple UAVs in an FN. To accomplish this, SUPPLY defines trajectories that minimize UAVs' energy consumption, while ensuring the targeted QoS levels. The obtained results show up to 25% energy consumption reduction with minimal impact on throughput and delay.
The GANfather: Controllable generation of malicious activity to improve defence systems
Jul 25, 2023
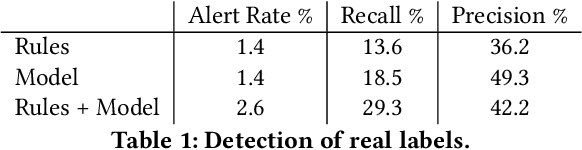
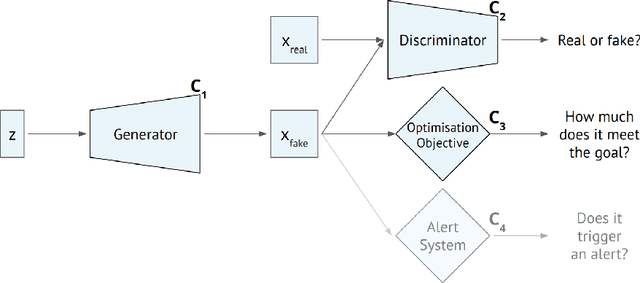
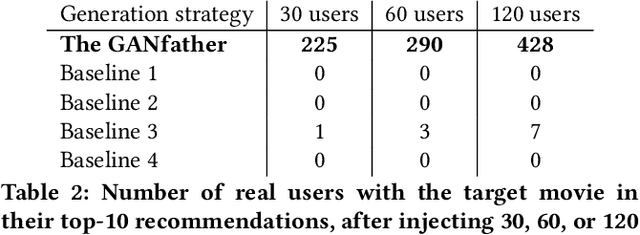
Machine learning methods to aid defence systems in detecting malicious activity typically rely on labelled data. In some domains, such labelled data is unavailable or incomplete. In practice this can lead to low detection rates and high false positive rates, which characterise for example anti-money laundering systems. In fact, it is estimated that 1.7--4 trillion euros are laundered annually and go undetected. We propose The GANfather, a method to generate samples with properties of malicious activity, without label requirements. We propose to reward the generation of malicious samples by introducing an extra objective to the typical Generative Adversarial Networks (GANs) loss. Ultimately, our goal is to enhance the detection of illicit activity using the discriminator network as a novel and robust defence system. Optionally, we may encourage the generator to bypass pre-existing detection systems. This setup then reveals defensive weaknesses for the discriminator to correct. We evaluate our method in two real-world use cases, money laundering and recommendation systems. In the former, our method moves cumulative amounts close to 350 thousand dollars through a network of accounts without being detected by an existing system. In the latter, we recommend the target item to a broad user base with as few as 30 synthetic attackers. In both cases, we train a new defence system to capture the synthetic attacks.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023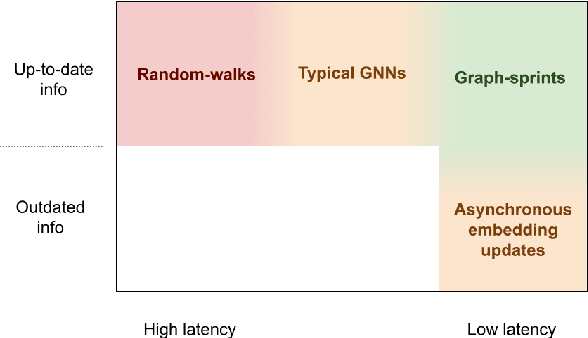

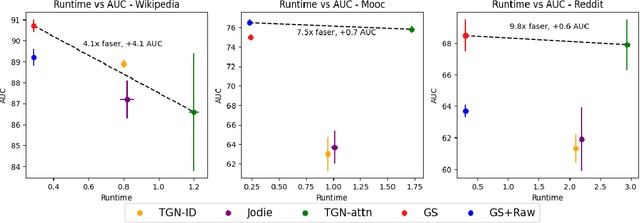

Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.
Faster Convergence with Lexicase Selection in Tree-based Automated Machine Learning
Feb 01, 2023In many evolutionary computation systems, parent selection methods can affect, among other things, convergence to a solution. In this paper, we present a study comparing the role of two commonly used parent selection methods in evolving machine learning pipelines in an automated machine learning system called Tree-based Pipeline Optimization Tool (TPOT). Specifically, we demonstrate, using experiments on multiple datasets, that lexicase selection leads to significantly faster convergence as compared to NSGA-II in TPOT. We also compare the exploration of parts of the search space by these selection methods using a trie data structure that contains information about the pipelines explored in a particular run.