 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP and LLMs for Program Synthesis: No Clear Winners
Aug 05, 2025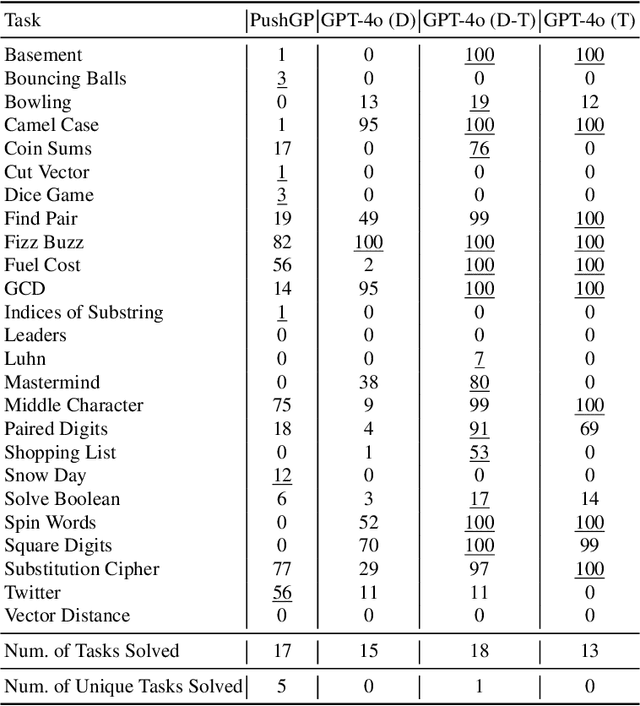
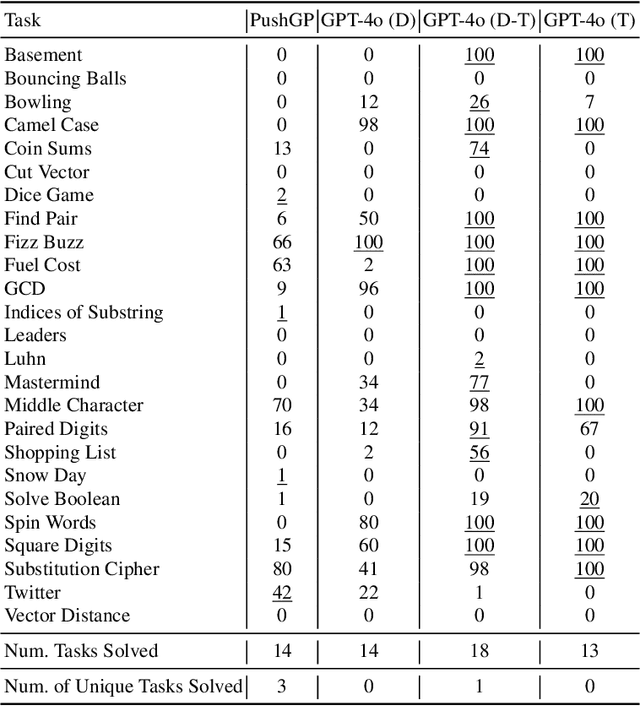
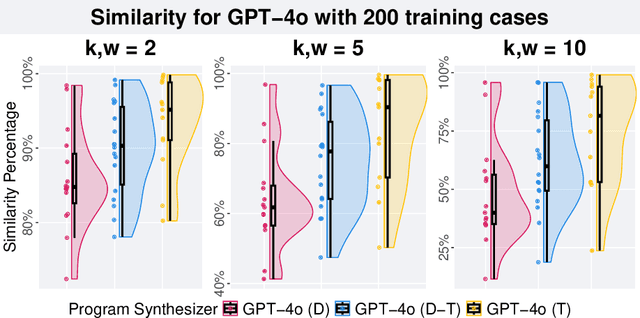
Genetic programming (GP) and large language models (LLMs) differ in how program specifications are provided: GP uses input-output examples, and LLMs use text descriptions. In this work, we compared the ability of PushGP and GPT-4o to synthesize computer programs for tasks from the PSB2 benchmark suite. We used three prompt variants with GPT-4o: input-output examples (data-only), textual description of the task (text-only), and a combination of both textual descriptions and input-output examples (data-text). Additionally, we varied the number of input-output examples available for building programs. For each synthesizer and task combination, we compared success rates across all program synthesizers, as well as the similarity between successful GPT-4o synthesized programs. We found that the combination of PushGP and GPT-4o with data-text prompting led to the greatest number of tasks solved (23 of the 25 tasks), even though several tasks were solved exclusively by only one of the two synthesizers. We also observed that PushGP and GPT-4o with data-only prompting solved fewer tasks with the decrease in the training set size, while the remaining synthesizers saw no decrease. We also detected significant differences in similarity between the successful programs synthesized for GPT-4o with text-only and data-only prompting. With there being no dominant program synthesizer, this work highlights the importance of different optimization techniques used by PushGP and LLMs to synthesize programs.
Lexicase Selection Parameter Analysis: Varying Population Size and Test Case Redundancy with Diagnostic Metrics
Jul 21, 2024
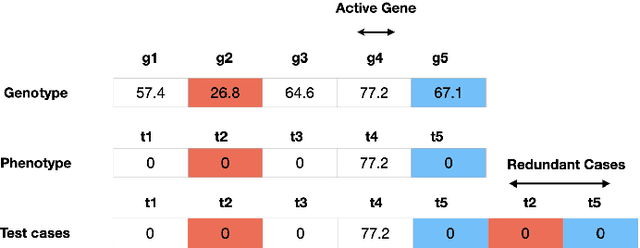
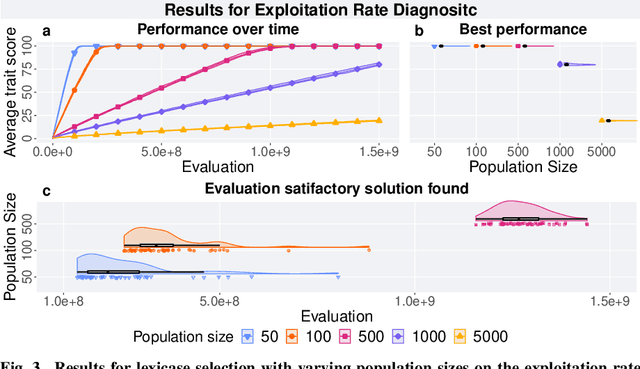
Lexicase selection is a successful parent selection method in genetic programming that has outperformed other methods across multiple benchmark suites. Unlike other selection methods that require explicit parameters to function, such as tournament size in tournament selection, lexicase selection does not. However, if evolutionary parameters like population size and number of generations affect the effectiveness of a selection method, then lexicase's performance may also be impacted by these `hidden' parameters. Here, we study how these hidden parameters affect lexicase's ability to exploit gradients and maintain specialists using diagnostic metrics. By varying the population size with a fixed evaluation budget, we show that smaller populations tend to have greater exploitation capabilities, whereas larger populations tend to maintain more specialists. We also consider the effect redundant test cases have on specialist maintenance, and find that high redundancy may hinder the ability to optimize and maintain specialists, even for larger populations. Ultimately, we highlight that population size, evaluation budget, and test cases must be carefully considered for the characteristics of the problem being solved.
Lexidate: Model Evaluation and Selection with Lexicase
Jun 17, 2024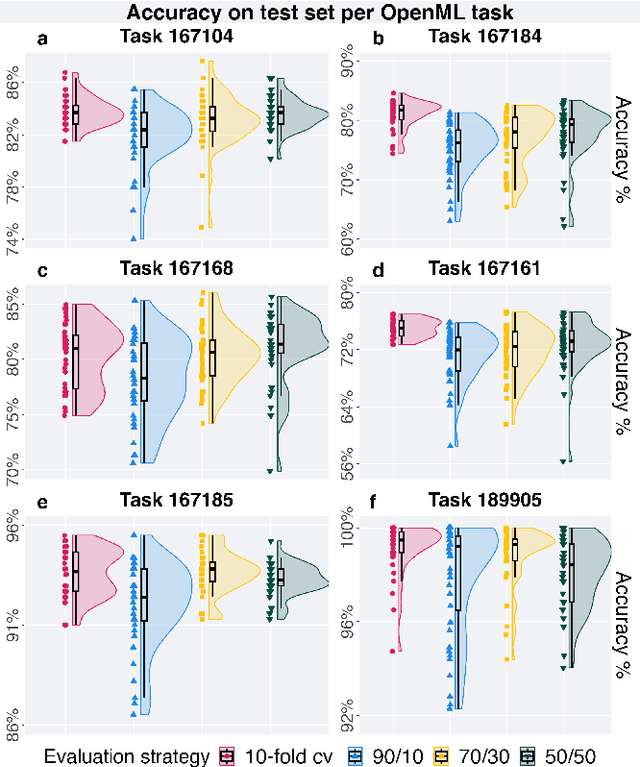
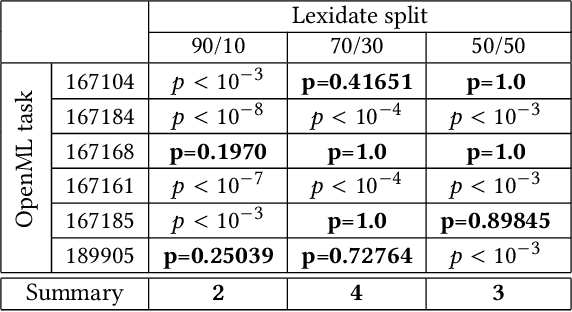
Automated machine learning streamlines the task of finding effective machine learning pipelines by automating model training, evaluation, and selection. Traditional evaluation strategies, like cross-validation (CV), generate one value that averages the accuracy of a pipeline's predictions. This single value, however, may not fully describe the generalizability of the pipeline. Here, we present Lexicase-based Validation (lexidate), a method that uses multiple, independent prediction values for selection. Lexidate splits training data into a learning set and a selection set. Pipelines are trained on the learning set and make predictions on the selection set. The predictions are graded for correctness and used by lexicase selection to identify parent pipelines. Compared to 10-fold CV, lexicase reduces the training time. We test the effectiveness of three lexidate configurations within the Tree-based Pipeline Optimization Tool 2 (TPOT2) package on six OpenML classification tasks. In one configuration, we detected no difference in the accuracy of the final model returned from TPOT2 on most tasks compared to 10-fold CV. All configurations studied here returned similar or less complex final pipelines compared to 10-fold CV.
Faster Convergence with Lexicase Selection in Tree-based Automated Machine Learning
Feb 01, 2023In many evolutionary computation systems, parent selection methods can affect, among other things, convergence to a solution. In this paper, we present a study comparing the role of two commonly used parent selection methods in evolving machine learning pipelines in an automated machine learning system called Tree-based Pipeline Optimization Tool (TPOT). Specifically, we demonstrate, using experiments on multiple datasets, that lexicase selection leads to significantly faster convergence as compared to NSGA-II in TPOT. We also compare the exploration of parts of the search space by these selection methods using a trie data structure that contains information about the pipelines explored in a particular run.