 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexidate: Model Evaluation and Selection with Lexicase
Paper and Code
Jun 17, 2024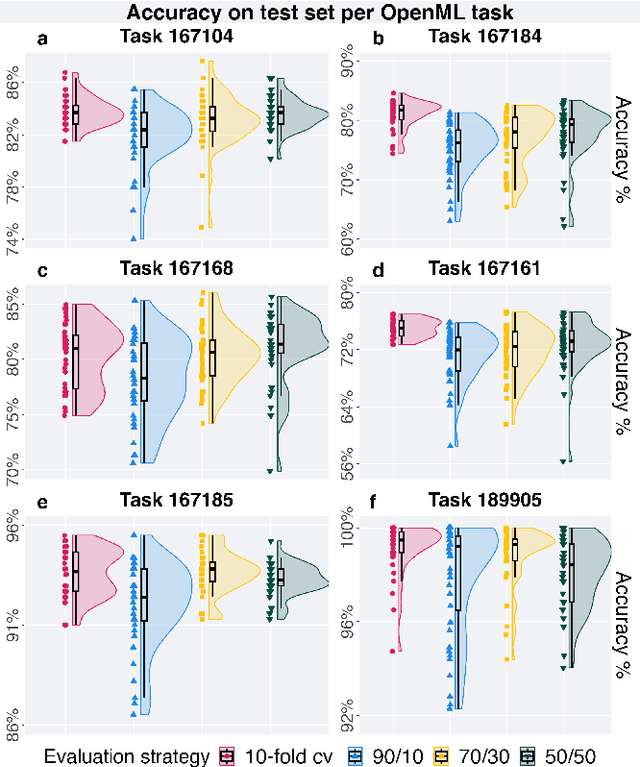
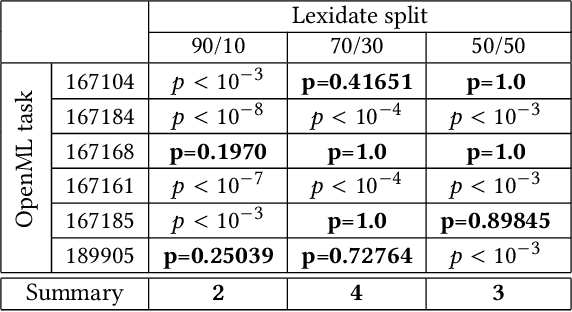
Automated machine learning streamlines the task of finding effective machine learning pipelines by automating model training, evaluation, and selection. Traditional evaluation strategies, like cross-validation (CV), generate one value that averages the accuracy of a pipeline's predictions. This single value, however, may not fully describe the generalizability of the pipeline. Here, we present Lexicase-based Validation (lexidate), a method that uses multiple, independent prediction values for selection. Lexidate splits training data into a learning set and a selection set. Pipelines are trained on the learning set and make predictions on the selection set. The predictions are graded for correctness and used by lexicase selection to identify parent pipelines. Compared to 10-fold CV, lexicase reduces the training time. We test the effectiveness of three lexidate configurations within the Tree-based Pipeline Optimization Tool 2 (TPOT2) package on six OpenML classification tasks. In one configuration, we detected no difference in the accuracy of the final model returned from TPOT2 on most tasks compared to 10-fold CV. All configurations studied here returned similar or less complex final pipelines compared to 10-fold CV.