 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP and LLMs for Program Synthesis: No Clear Winners
Aug 05, 2025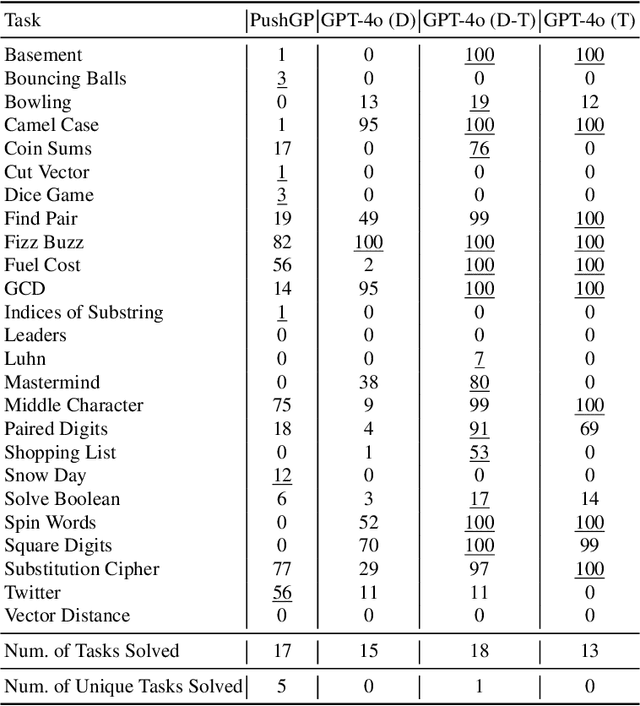
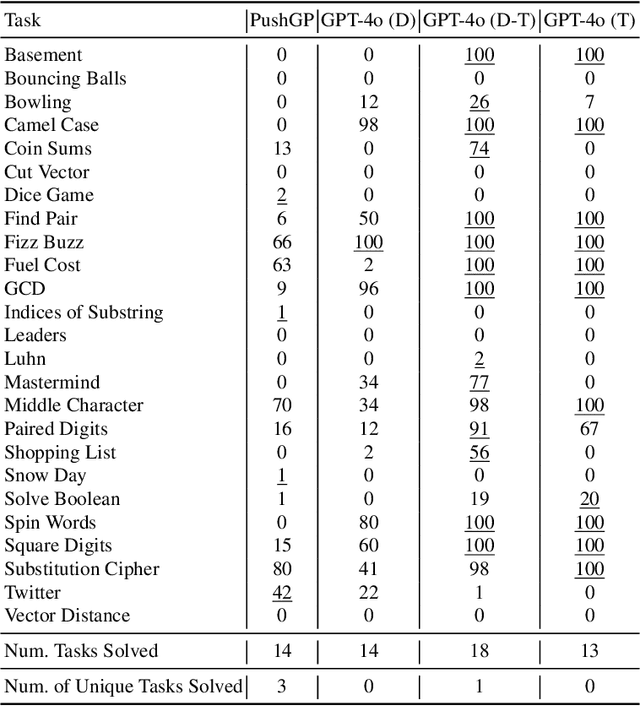
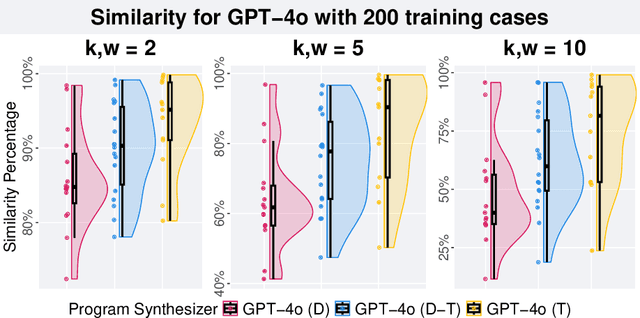
Genetic programming (GP) and large language models (LLMs) differ in how program specifications are provided: GP uses input-output examples, and LLMs use text descriptions. In this work, we compared the ability of PushGP and GPT-4o to synthesize computer programs for tasks from the PSB2 benchmark suite. We used three prompt variants with GPT-4o: input-output examples (data-only), textual description of the task (text-only), and a combination of both textual descriptions and input-output examples (data-text). Additionally, we varied the number of input-output examples available for building programs. For each synthesizer and task combination, we compared success rates across all program synthesizers, as well as the similarity between successful GPT-4o synthesized programs. We found that the combination of PushGP and GPT-4o with data-text prompting led to the greatest number of tasks solved (23 of the 25 tasks), even though several tasks were solved exclusively by only one of the two synthesizers. We also observed that PushGP and GPT-4o with data-only prompting solved fewer tasks with the decrease in the training set size, while the remaining synthesizers saw no decrease. We also detected significant differences in similarity between the successful programs synthesized for GPT-4o with text-only and data-only prompting. With there being no dominant program synthesizer, this work highlights the importance of different optimization techniques used by PushGP and LLMs to synthesize programs.
Surgeon Style Fingerprinting and Privacy Risk Quantification via Discrete Diffusion Models in a Vision-Language-Action Framework
Jun 09, 2025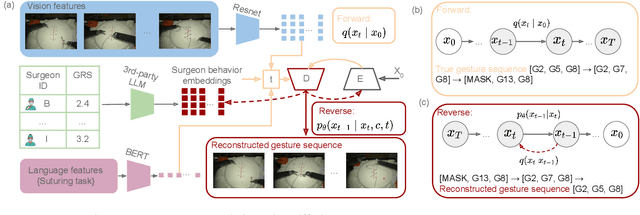

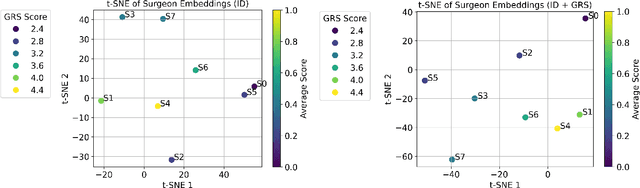

Surgeons exhibit distinct operating styles due to differences in training, experience, and motor behavior - yet current AI systems often ignore this personalization signal. We propose a novel approach to model fine-grained, surgeon-specific fingerprinting in robotic surgery using a discrete diffusion framework integrated with a vision-language-action (VLA) pipeline. Our method formulates gesture prediction as a structured sequence denoising task, conditioned on multimodal inputs including endoscopic video, surgical intent language, and a privacy-aware embedding of surgeon identity and skill. Personalized surgeon fingerprinting is encoded through natural language prompts using third-party language models, allowing the model to retain individual behavioral style without exposing explicit identity. We evaluate our method on the JIGSAWS dataset and demonstrate that it accurately reconstructs gesture sequences while learning meaningful motion fingerprints unique to each surgeon. To quantify the privacy implications of personalization, we perform membership inference attacks and find that more expressive embeddings improve task performance but simultaneously increase susceptibility to identity leakage. These findings demonstrate that while personalized embeddings improve performance, they also increase vulnerability to identity leakage, revealing the importance of balancing personalization with privacy risk in surgical modeling. Code is available at: https://github.com/huixin-zhan-ai/Surgeon_style_fingerprinting.
StarBASE-GP: Biologically-Guided Automated Machine Learning for Genotype-to-Phenotype Association Analysis
May 28, 2025We present the Star-Based Automated Single-locus and Epistasis analysis tool - Genetic Programming (StarBASE-GP), an automated framework for discovering meaningful genetic variants associated with phenotypic variation in large-scale genomic datasets. StarBASE-GP uses a genetic programming-based multi-objective optimization strategy to evolve machine learning pipelines that simultaneously maximize explanatory power (r2) and minimize pipeline complexity. Biological domain knowledge is integrated at multiple stages, including the use of nine inheritance encoding strategies to model deviations from additivity, a custom linkage disequilibrium pruning node that minimizes redundancy among features, and a dynamic variant recommendation system that prioritizes informative candidates for pipeline inclusion. We evaluate StarBASE-GP on a cohort of Rattus norvegicus (brown rat) to identify variants associated with body mass index, benchmarking its performance against a random baseline and a biologically naive version of the tool. StarBASE-GP consistently evolves Pareto fronts with superior performance, yielding higher accuracy in identifying both ground truth and novel quantitative trait loci, highlighting relevant targets for future validation. By incorporating evolutionary search and relevant biological theory into a flexible automated machine learning framework, StarBASE-GP demonstrates robust potential for advancing variant discovery in complex traits.
Leveraging Social Determinants of Health in Alzheimer's Research Using LLM-Augmented Literature Mining and Knowledge Graphs
Oct 04, 2024Growing evidence suggests that social determinants of health (SDoH), a set of nonmedical factors, affect individuals' risks of developing Alzheimer's disease (AD) and related dementias. Nevertheless, the etiological mechanisms underlying such relationships remain largely unclear, mainly due to difficulties in collecting relevant information. This study presents a novel, automated framework that leverages recent advancements of large language model (LLM) and natural language processing techniques to mine SDoH knowledge from extensive literature and integrate it with AD-related biological entities extracted from the general-purpose knowledge graph PrimeKG. Utilizing graph neural networks, we performed link prediction tasks to evaluate the resultant SDoH-augmented knowledge graph. Our framework shows promise for enhancing knowledge discovery in AD and can be generalized to other SDoH-related research areas, offering a new tool for exploring the impact of social determinants on health outcomes. Our code is available at: https://github.com/hwq0726/SDoHenPKG
Lexicase Selection Parameter Analysis: Varying Population Size and Test Case Redundancy with Diagnostic Metrics
Jul 21, 2024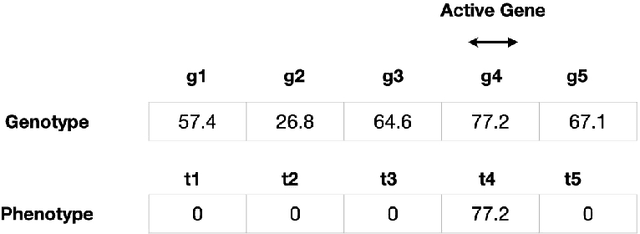
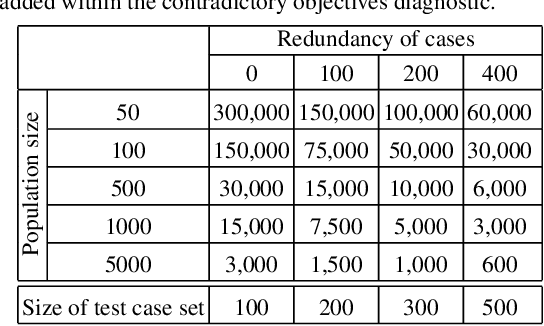
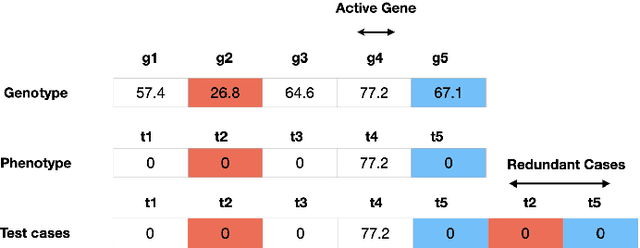
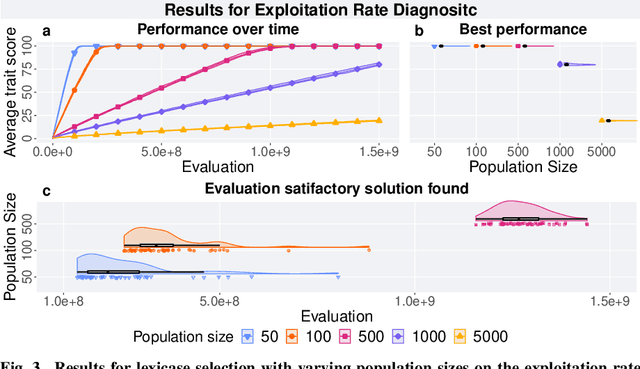
Lexicase selection is a successful parent selection method in genetic programming that has outperformed other methods across multiple benchmark suites. Unlike other selection methods that require explicit parameters to function, such as tournament size in tournament selection, lexicase selection does not. However, if evolutionary parameters like population size and number of generations affect the effectiveness of a selection method, then lexicase's performance may also be impacted by these `hidden' parameters. Here, we study how these hidden parameters affect lexicase's ability to exploit gradients and maintain specialists using diagnostic metrics. By varying the population size with a fixed evaluation budget, we show that smaller populations tend to have greater exploitation capabilities, whereas larger populations tend to maintain more specialists. We also consider the effect redundant test cases have on specialist maintenance, and find that high redundancy may hinder the ability to optimize and maintain specialists, even for larger populations. Ultimately, we highlight that population size, evaluation budget, and test cases must be carefully considered for the characteristics of the problem being solved.
A review of feature selection strategies utilizing graph data structures and knowledge graphs
Jun 21, 2024



Feature selection in Knowledge Graphs (KGs) are increasingly utilized in diverse domains, including biomedical research, Natural Language Processing (NLP), and personalized recommendation systems. This paper delves into the methodologies for feature selection within KGs, emphasizing their roles in enhancing machine learning (ML) model efficacy, hypothesis generation, and interpretability. Through this comprehensive review, we aim to catalyze further innovation in feature selection for KGs, paving the way for more insightful, efficient, and interpretable analytical models across various domains. Our exploration reveals the critical importance of scalability, accuracy, and interpretability in feature selection techniques, advocating for the integration of domain knowledge to refine the selection process. We highlight the burgeoning potential of multi-objective optimization and interdisciplinary collaboration in advancing KG feature selection, underscoring the transformative impact of such methodologies on precision medicine, among other fields. The paper concludes by charting future directions, including the development of scalable, dynamic feature selection algorithms and the integration of explainable AI principles to foster transparency and trust in KG-driven models.
Lexidate: Model Evaluation and Selection with Lexicase
Jun 17, 2024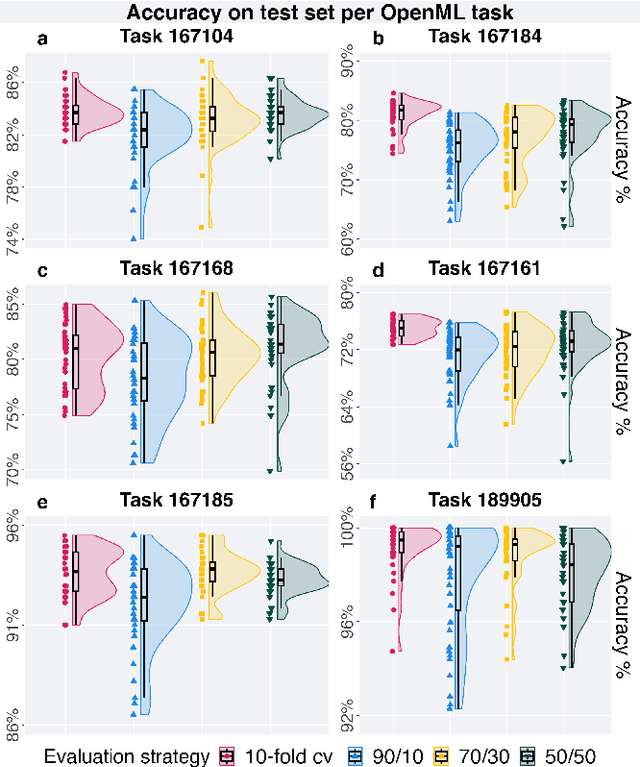
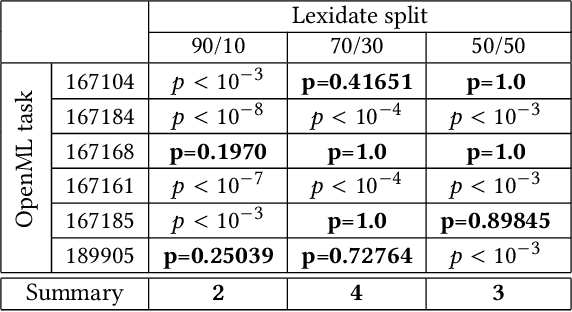
Automated machine learning streamlines the task of finding effective machine learning pipelines by automating model training, evaluation, and selection. Traditional evaluation strategies, like cross-validation (CV), generate one value that averages the accuracy of a pipeline's predictions. This single value, however, may not fully describe the generalizability of the pipeline. Here, we present Lexicase-based Validation (lexidate), a method that uses multiple, independent prediction values for selection. Lexidate splits training data into a learning set and a selection set. Pipelines are trained on the learning set and make predictions on the selection set. The predictions are graded for correctness and used by lexicase selection to identify parent pipelines. Compared to 10-fold CV, lexicase reduces the training time. We test the effectiveness of three lexidate configurations within the Tree-based Pipeline Optimization Tool 2 (TPOT2) package on six OpenML classification tasks. In one configuration, we detected no difference in the accuracy of the final model returned from TPOT2 on most tasks compared to 10-fold CV. All configurations studied here returned similar or less complex final pipelines compared to 10-fold CV.
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Apr 29, 2024



MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Genetic Programming Theory and Practice: A Fifteen-Year Trajectory
Feb 01, 2024The GPTP workshop series, which began in 2003, has served over the years as a focal meeting for genetic programming (GP) researchers. As such, we think it provides an excellent source for studying the development of GP over the past fifteen years. We thus present herein a trajectory of the thematic developments in the field of GP.
Coevolving Artistic Images Using OMNIREP
Jan 20, 2024We have recently developed OMNIREP, a coevolutionary algorithm to discover both a representation and an interpreter that solve a particular problem of interest. Herein, we demonstrate that the OMNIREP framework can be successfully applied within the field of evolutionary art. Specifically, we coevolve representations that encode image position, alongside interpreters that transform these positions into one of three pre-defined shapes (chunks, polygons, or circles) of varying size, shape, and color. We showcase a sampling of the unique image variations produced by this approach.