 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoevolving Artistic Images Using OMNIREP
Jan 20, 2024We have recently developed OMNIREP, a coevolutionary algorithm to discover both a representation and an interpreter that solve a particular problem of interest. Herein, we demonstrate that the OMNIREP framework can be successfully applied within the field of evolutionary art. Specifically, we coevolve representations that encode image position, alongside interpreters that transform these positions into one of three pre-defined shapes (chunks, polygons, or circles) of varying size, shape, and color. We showcase a sampling of the unique image variations produced by this approach.
New Pathways in Coevolutionary Computation
Jan 19, 2024The simultaneous evolution of two or more species with coupled fitness -- coevolution -- has been put to good use in the field of evolutionary computation. Herein, we present two new forms of coevolutionary algorithms, which we have recently designed and applied with success. OMNIREP is a cooperative coevolutionary algorithm that discovers both a representation and an encoding for solving a particular problem of interest. SAFE is a commensalistic coevolutionary algorithm that maintains two coevolving populations: a population of candidate solutions and a population of candidate objective functions needed to measure solution quality during evolution.
* arXiv admin note: substantial text overlap with arXiv:2206.13509, arXiv:2206.15409, arXiv:2206.12707
STREAMLINE: An Automated Machine Learning Pipeline for Biomedicine Applied to Examine the Utility of Photography-Based Phenotypes for OSA Prediction Across International Sleep Centers
Dec 09, 2023



While machine learning (ML) includes a valuable array of tools for analyzing biomedical data, significant time and expertise is required to assemble effective, rigorous, and unbiased pipelines. Automated ML (AutoML) tools seek to facilitate ML application by automating a subset of analysis pipeline elements. In this study we develop and validate a Simple, Transparent, End-to-end Automated Machine Learning Pipeline (STREAMLINE) and apply it to investigate the added utility of photography-based phenotypes for predicting obstructive sleep apnea (OSA); a common and underdiagnosed condition associated with a variety of health, economic, and safety consequences. STREAMLINE is designed to tackle biomedical binary classification tasks while adhering to best practices and accommodating complexity, scalability, reproducibility, customization, and model interpretation. Benchmarking analyses validated the efficacy of STREAMLINE across data simulations with increasingly complex patterns of association. Then we applied STREAMLINE to evaluate the utility of demographics (DEM), self-reported comorbidities (DX), symptoms (SYM), and photography-based craniofacial (CF) and intraoral (IO) anatomy measures in predicting any OSA or moderate/severe OSA using 3,111 participants from Sleep Apnea Global Interdisciplinary Consortium (SAGIC). OSA analyses identified a significant increase in ROC-AUC when adding CF to DEM+DX+SYM to predict moderate/severe OSA. A consistent but non-significant increase in PRC-AUC was observed with the addition of each subsequent feature set to predict any OSA, with CF and IO yielding minimal improvements. Application of STREAMLINE to OSA data suggests that CF features provide additional value in predicting moderate/severe OSA, but neither CF nor IO features meaningfully improved the prediction of any OSA beyond established demographics, comorbidity and symptom characteristics.
Automatically Balancing Model Accuracy and Complexity using Solution and Fitness Evolution (SAFE)
Jun 30, 2022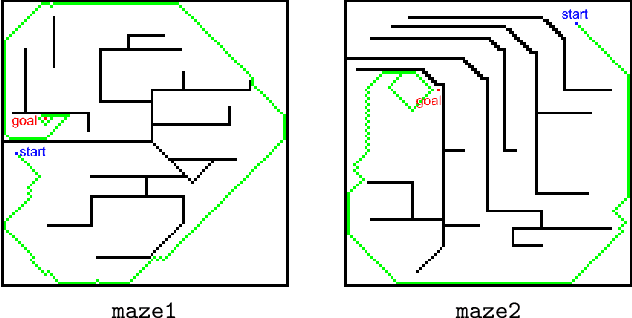
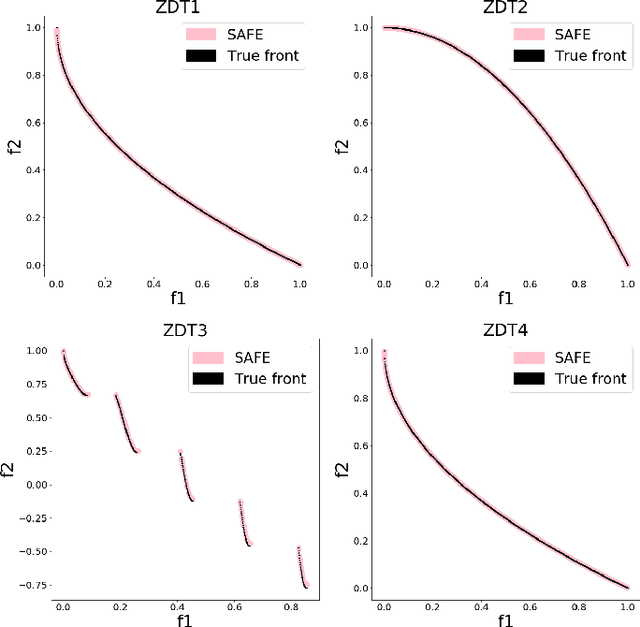
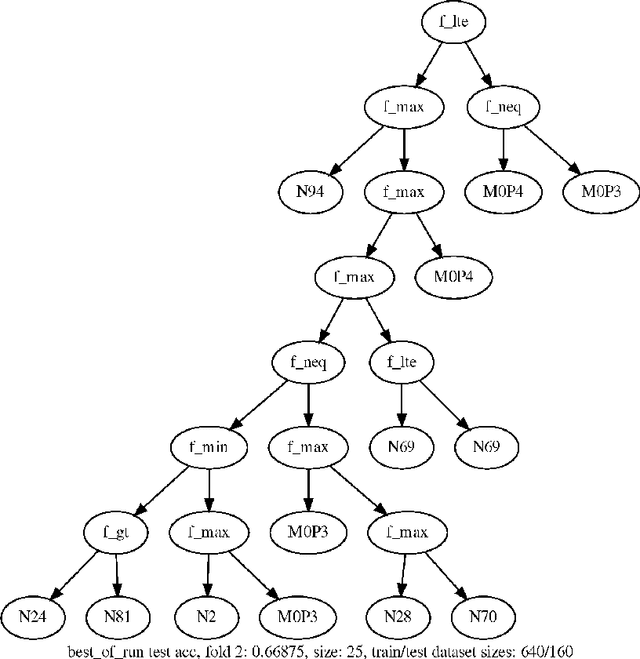
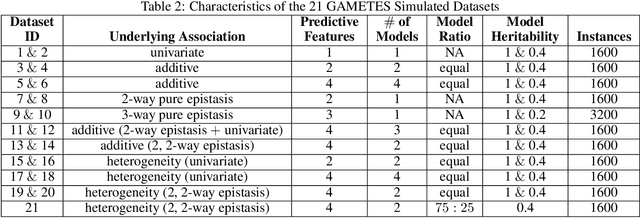
When seeking a predictive model in biomedical data, one often has more than a single objective in mind, e.g., attaining both high accuracy and low complexity (to promote interpretability). We investigate herein whether multiple objectives can be dynamically tuned by our recently proposed coevolutionary algorithm, SAFE (Solution And Fitness Evolution). We find that SAFE is able to automatically tune accuracy and complexity with no performance loss, as compared with a standard evolutionary algorithm, over complex simulated genetics datasets produced by the GAMETES tool.
Solution and Fitness Evolution : A Study of Multiobjective Problems
Jun 25, 2022
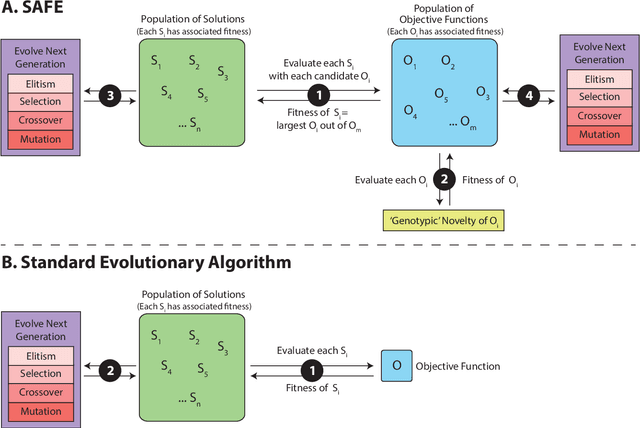
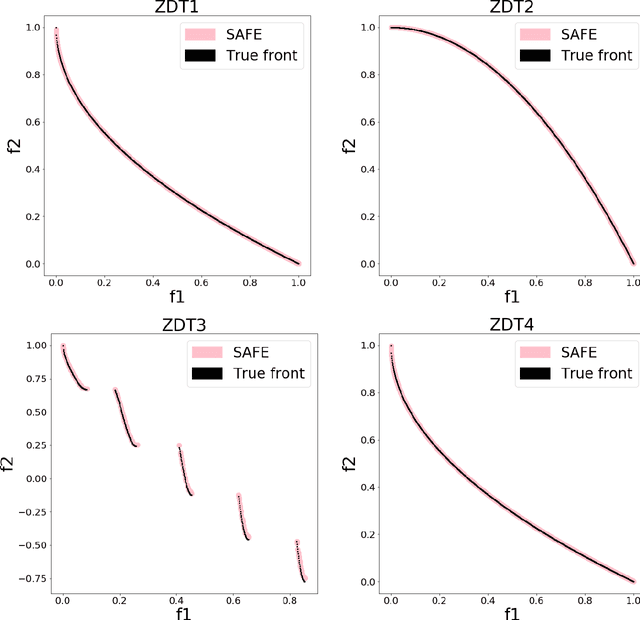

We have recently presented SAFE -- Solution And Fitness Evolution -- a commensalistic coevolutionary algorithm that maintains two coevolving populations: a population of candidate solutions and a population of candidate objective functions. We showed that SAFE was successful at evolving solutions within a robotic maze domain. Herein we present an investigation of SAFE's adaptation and application to multiobjective problems, wherein candidate objective functions explore different weightings of each objective. Though preliminary, the results suggest that SAFE, and the concept of coevolving solutions and objective functions, can identify a similar set of optimal multiobjective solutions without explicitly employing a Pareto front for fitness calculation and parent selection. These findings support our hypothesis that the SAFE algorithm concept can not only solve complex problems, but can adapt to the challenge of problems with multiple objectives.
* arXiv admin note: substantial text overlap with arXiv:2206.12707
Solution and Fitness Evolution (SAFE): Coevolving Solutions and Their Objective Functions
Jun 25, 2022We recently highlighted a fundamental problem recognized to confound algorithmic optimization, namely, \textit{conflating} the objective with the objective function. Even when the former is well defined, the latter may not be obvious, e.g., in learning a strategy to navigate a maze to find a goal (objective), an effective objective function to \textit{evaluate} strategies may not be a simple function of the distance to the objective. We proposed to automate the means by which a good objective function may be discovered -- a proposal reified herein. We present \textbf{S}olution \textbf{A}nd \textbf{F}itness \textbf{E}volution (\textbf{SAFE}), a \textit{commensalistic} coevolutionary algorithm that maintains two coevolving populations: a population of candidate solutions and a population of candidate objective functions. As proof of principle of this concept, we show that SAFE successfully evolves not only solutions within a robotic maze domain, but also the objective functions needed to measure solution quality during evolution.
STREAMLINE: A Simple, Transparent, End-To-End Automated Machine Learning Pipeline Facilitating Data Analysis and Algorithm Comparison
Jun 23, 2022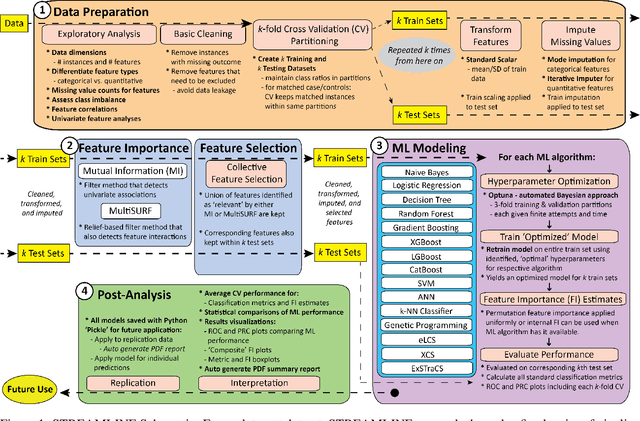
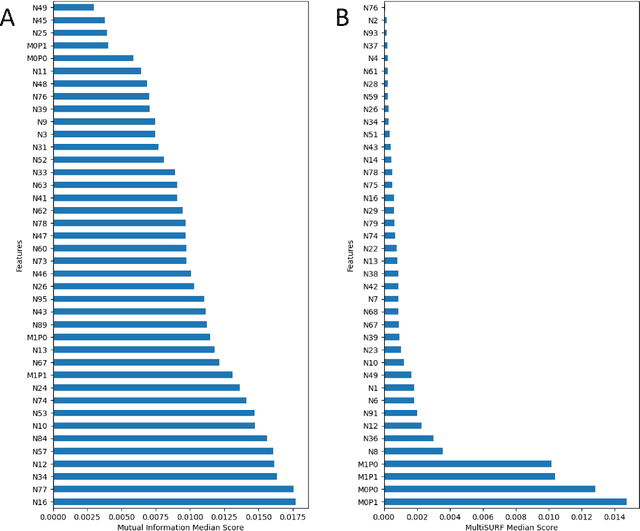
Machine learning (ML) offers powerful methods for detecting and modeling associations often in data with large feature spaces and complex associations. Many useful tools/packages (e.g. scikit-learn) have been developed to make the various elements of data handling, processing, modeling, and interpretation accessible. However, it is not trivial for most investigators to assemble these elements into a rigorous, replicatable, unbiased, and effective data analysis pipeline. Automated machine learning (AutoML) seeks to address these issues by simplifying the process of ML analysis for all. Here, we introduce STREAMLINE, a simple, transparent, end-to-end AutoML pipeline designed as a framework to easily conduct rigorous ML modeling and analysis (limited initially to binary classification). STREAMLINE is specifically designed to compare performance between datasets, ML algorithms, and other AutoML tools. It is unique among other autoML tools by offering a fully transparent and consistent baseline of comparison using a carefully designed series of pipeline elements including: (1) exploratory analysis, (2) basic data cleaning, (3) cross validation partitioning, (4) data scaling and imputation, (5) filter-based feature importance estimation, (6) collective feature selection, (7) ML modeling with `Optuna' hyperparameter optimization across 15 established algorithms (including less well-known Genetic Programming and rule-based ML), (8) evaluation across 16 classification metrics, (9) model feature importance estimation, (10) statistical significance comparisons, and (11) automatically exporting all results, plots, a PDF summary report, and models that can be easily applied to replication data.
LCS-DIVE: An Automated Rule-based Machine Learning Visualization Pipeline for Characterizing Complex Associations in Classification
Apr 26, 2021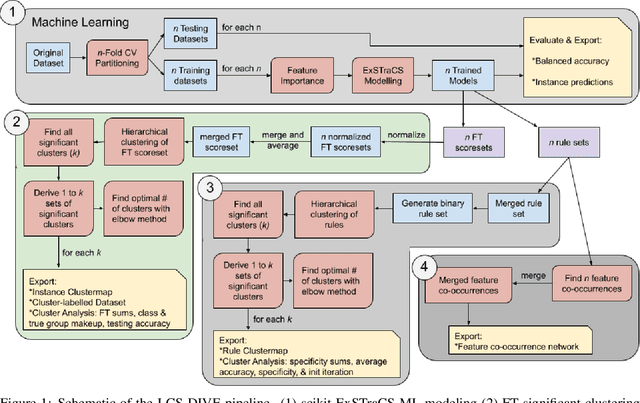
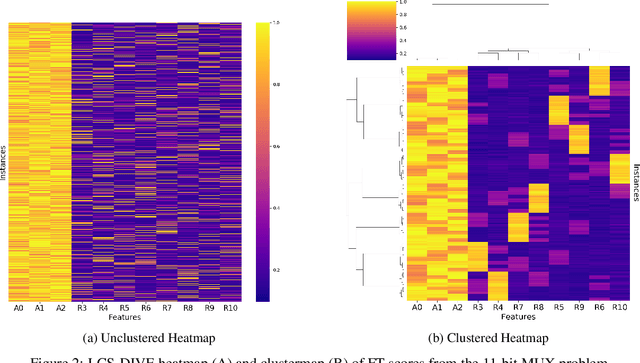
Machine learning (ML) research has yielded powerful tools for training accurate prediction models despite complex multivariate associations (e.g. interactions and heterogeneity). In fields such as medicine, improved interpretability of ML modeling is required for knowledge discovery, accountability, and fairness. Rule-based ML approaches such as Learning Classifier Systems (LCSs) strike a balance between predictive performance and interpretability in complex, noisy domains. This work introduces the LCS Discovery and Visualization Environment (LCS-DIVE), an automated LCS model interpretation pipeline for complex biomedical classification. LCS-DIVE conducts modeling using a new scikit-learn implementation of ExSTraCS, an LCS designed to overcome noise and scalability in biomedical data mining yielding human readable IF:THEN rules as well as feature-tracking scores for each training sample. LCS-DIVE leverages feature-tracking scores and/or rules to automatically guide characterization of (1) feature importance (2) underlying additive, epistatic, and/or heterogeneous patterns of association, and (3) model-driven heterogeneous instance subgroups via clustering, visualization generation, and cluster interrogation. LCS-DIVE was evaluated over a diverse set of simulated genetic and benchmark datasets encoding a variety of complex multivariate associations, demonstrating its ability to differentiate between them and then applied to characterize associations within a real-world study of pancreatic cancer.
A Rigorous Machine Learning Analysis Pipeline for Biomedical Binary Classification: Application in Pancreatic Cancer Nested Case-control Studies with Implications for Bias Assessments
Sep 08, 2020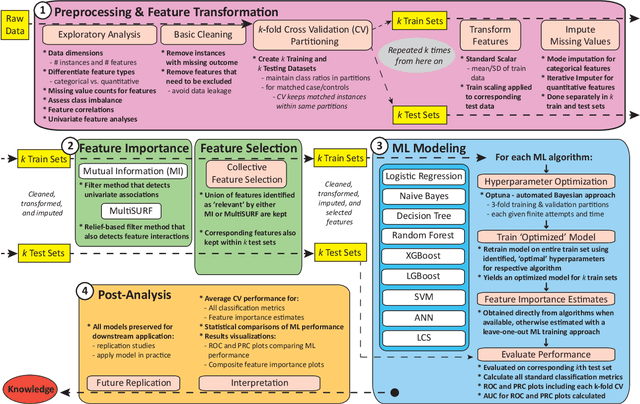
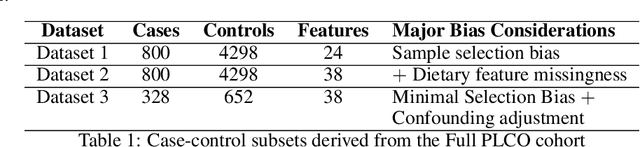
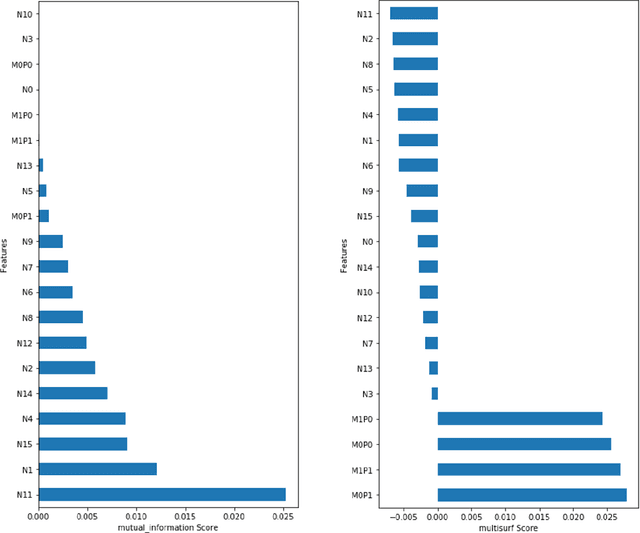
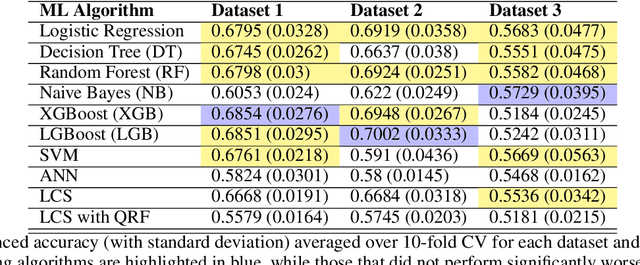
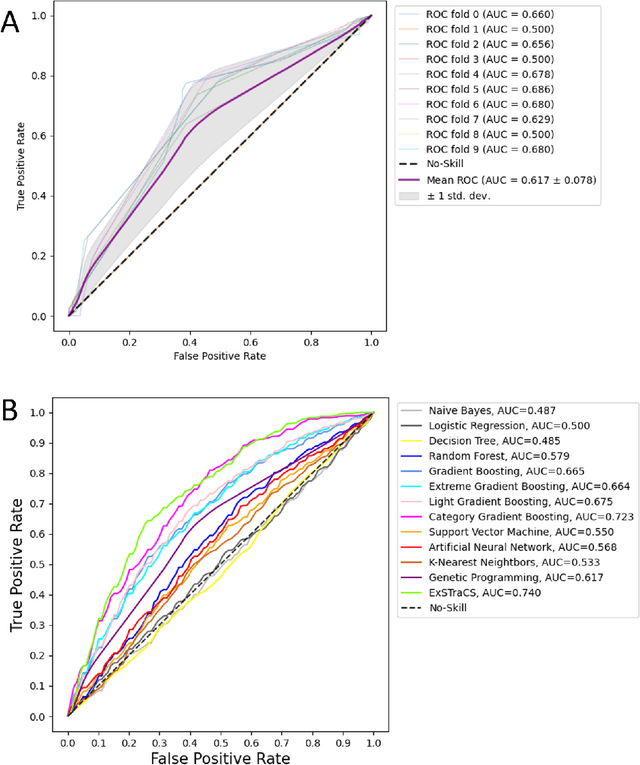
Machine learning (ML) offers a collection of powerful approaches for detecting and modeling associations, often applied to data having a large number of features and/or complex associations. Currently, there are many tools to facilitate implementing custom ML analyses (e.g. scikit-learn). Interest is also increasing in automated ML packages, which can make it easier for non-experts to apply ML and have the potential to improve model performance. ML permeates most subfields of biomedical research with varying levels of rigor and correct usage. Tremendous opportunities offered by ML are frequently offset by the challenge of assembling comprehensive analysis pipelines, and the ease of ML misuse. In this work we have laid out and assembled a complete, rigorous ML analysis pipeline focused on binary classification (i.e. case/control prediction), and applied this pipeline to both simulated and real world data. At a high level, this 'automated' but customizable pipeline includes a) exploratory analysis, b) data cleaning and transformation, c) feature selection, d) model training with 9 established ML algorithms, each with hyperparameter optimization, and e) thorough evaluation, including appropriate metrics, statistical analyses, and novel visualizations. This pipeline organizes the many subtle complexities of ML pipeline assembly to illustrate best practices to avoid bias and ensure reproducibility. Additionally, this pipeline is the first to compare established ML algorithms to 'ExSTraCS', a rule-based ML algorithm with the unique capability of interpretably modeling heterogeneous patterns of association. While designed to be widely applicable we apply this pipeline to an epidemiological investigation of established and newly identified risk factors for pancreatic cancer to evaluate how different sources of bias might be handled by ML algorithms.
Benchmarking Relief-Based Feature Selection Methods for Bioinformatics Data Mining
Apr 03, 2018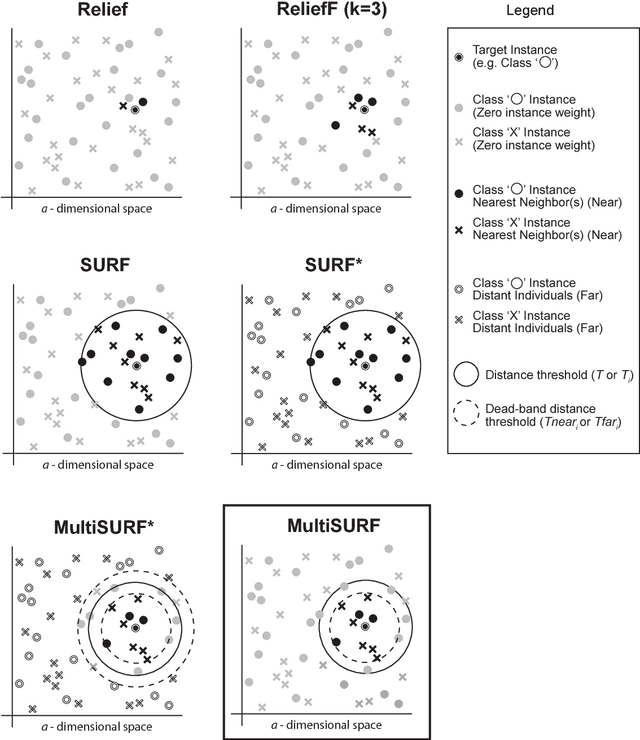
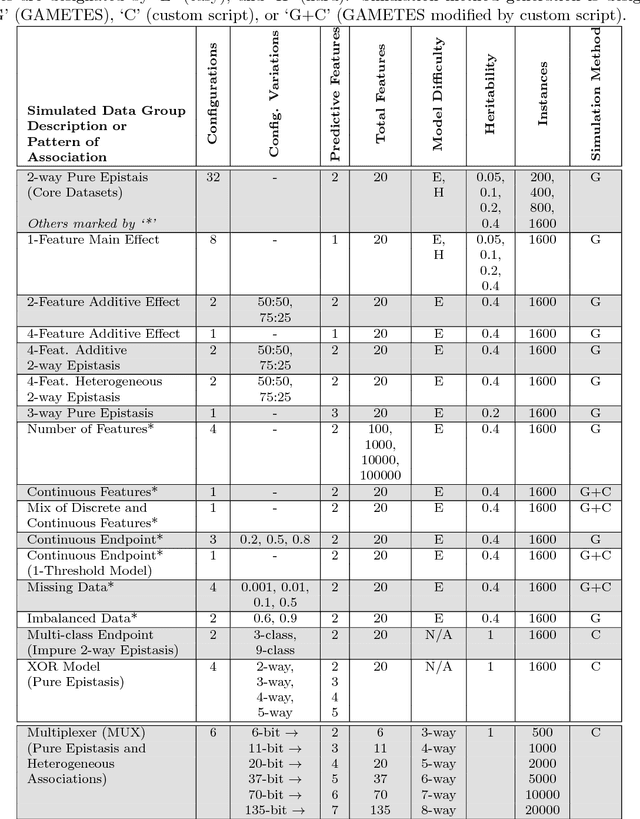
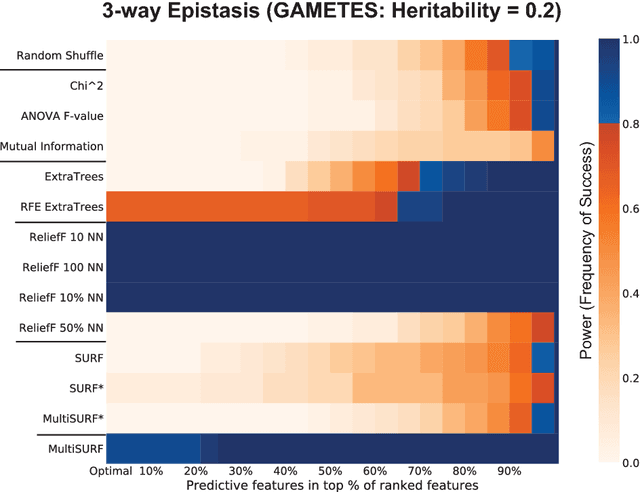
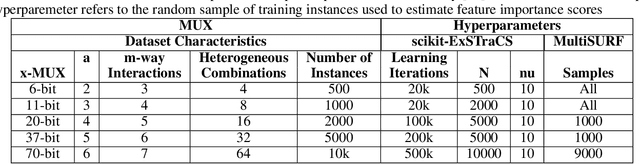
Modern biomedical data mining requires feature selection methods that can (1) be applied to large scale feature spaces (e.g. `omics' data), (2) function in noisy problems, (3) detect complex patterns of association (e.g. gene-gene interactions), (4) be flexibly adapted to various problem domains and data types (e.g. genetic variants, gene expression, and clinical data) and (5) are computationally tractable. To that end, this work examines a set of filter-style feature selection algorithms inspired by the `Relief' algorithm, i.e. Relief-Based algorithms (RBAs). We implement and expand these RBAs in an open source framework called ReBATE (Relief-Based Algorithm Training Environment). We apply a comprehensive genetic simulation study comparing existing RBAs, a proposed RBA called MultiSURF, and other established feature selection methods, over a variety of problems. The results of this study (1) support the assertion that RBAs are particularly flexible, efficient, and powerful feature selection methods that differentiate relevant features having univariate, multivariate, epistatic, or heterogeneous associations, (2) confirm the efficacy of expansions for classification vs. regression, discrete vs. continuous features, missing data, multiple classes, or class imbalance, (3) identify previously unknown limitations of specific RBAs, and (4) suggest that while MultiSURF* performs best for explicitly identifying pure 2-way interactions, MultiSURF yields the most reliable feature selection performance across a wide range of problem types.