 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Relief-Based Feature Selection Methods for Bioinformatics Data Mining
Apr 03, 2018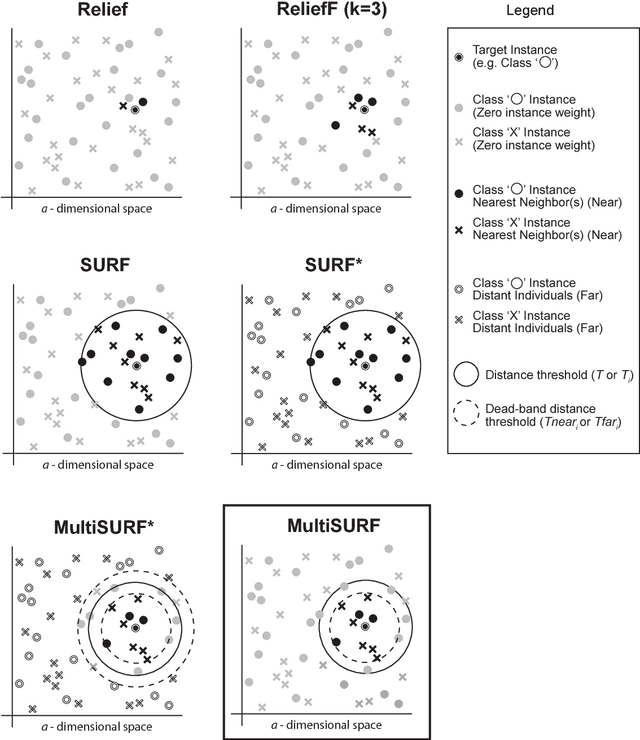
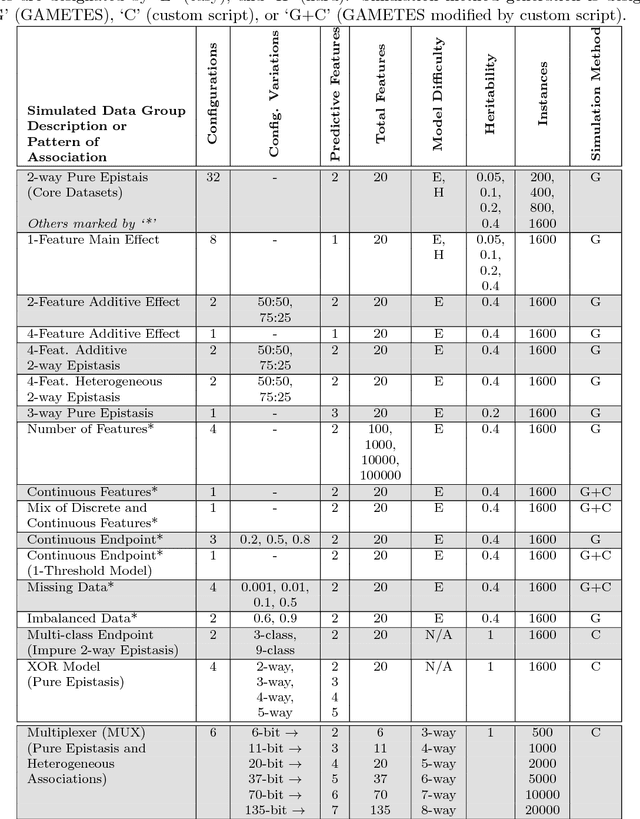
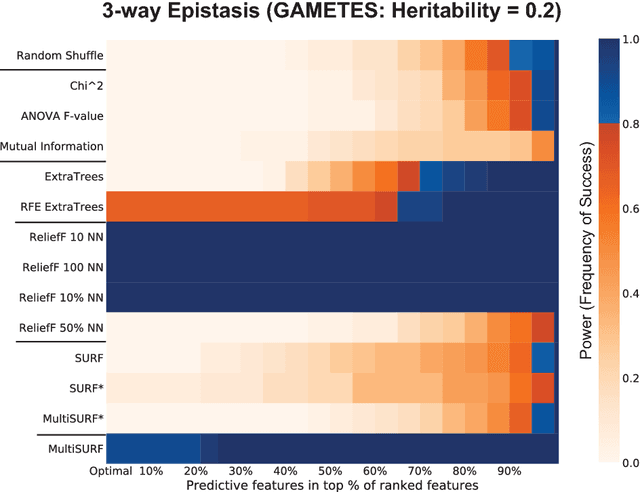
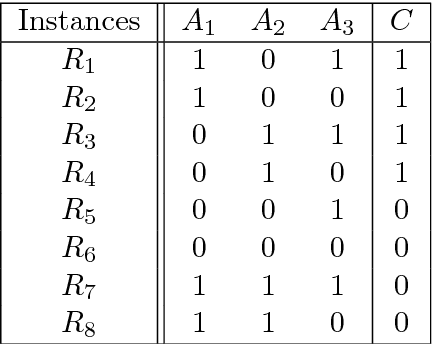
Modern biomedical data mining requires feature selection methods that can (1) be applied to large scale feature spaces (e.g. `omics' data), (2) function in noisy problems, (3) detect complex patterns of association (e.g. gene-gene interactions), (4) be flexibly adapted to various problem domains and data types (e.g. genetic variants, gene expression, and clinical data) and (5) are computationally tractable. To that end, this work examines a set of filter-style feature selection algorithms inspired by the `Relief' algorithm, i.e. Relief-Based algorithms (RBAs). We implement and expand these RBAs in an open source framework called ReBATE (Relief-Based Algorithm Training Environment). We apply a comprehensive genetic simulation study comparing existing RBAs, a proposed RBA called MultiSURF, and other established feature selection methods, over a variety of problems. The results of this study (1) support the assertion that RBAs are particularly flexible, efficient, and powerful feature selection methods that differentiate relevant features having univariate, multivariate, epistatic, or heterogeneous associations, (2) confirm the efficacy of expansions for classification vs. regression, discrete vs. continuous features, missing data, multiple classes, or class imbalance, (3) identify previously unknown limitations of specific RBAs, and (4) suggest that while MultiSURF* performs best for explicitly identifying pure 2-way interactions, MultiSURF yields the most reliable feature selection performance across a wide range of problem types.