 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.
Expanding on the BRIAR Dataset: A Comprehensive Whole Body Biometric Recognition Resource at Extreme Distances and Real-World Scenarios (Collections 1-4)
Jan 23, 2025
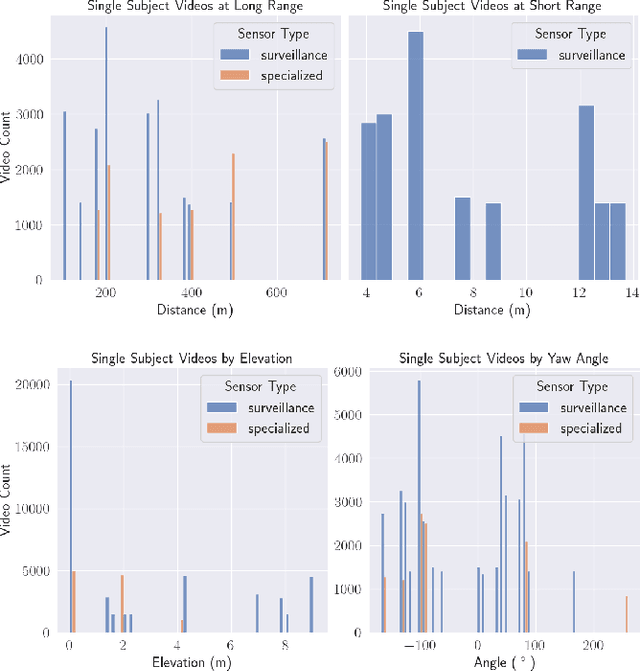
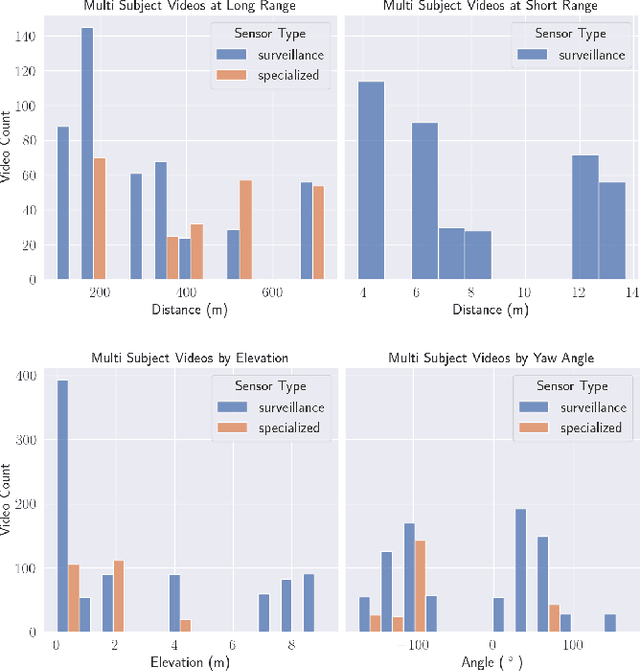

The state-of-the-art in biometric recognition algorithms and operational systems has advanced quickly in recent years providing high accuracy and robustness in more challenging collection environments and consumer applications. However, the technology still suffers greatly when applied to non-conventional settings such as those seen when performing identification at extreme distances or from elevated cameras on buildings or mounted to UAVs. This paper summarizes an extension to the largest dataset currently focused on addressing these operational challenges, and describes its composition as well as methodologies of collection, curation, and annotation.
Continuous Speculative Decoding for Autoregressive Image Generation
Nov 18, 2024Continuous-valued Autoregressive (AR) image generation models have demonstrated notable superiority over their discrete-token counterparts, showcasing considerable reconstruction quality and higher generation fidelity. However, the computational demands of the autoregressive framework result in significant inference overhead. While speculative decoding has proven effective in accelerating Large Language Models (LLMs), their adaptation to continuous-valued visual autoregressive models remains unexplored. This work generalizes the speculative decoding algorithm from discrete tokens to continuous space. By analyzing the intrinsic properties of output distribution, we establish a tailored acceptance criterion for the diffusion distributions prevalent in such models. To overcome the inconsistency that occurred in speculative decoding output distributions, we introduce denoising trajectory alignment and token pre-filling methods. Additionally, we identify the hard-to-sample distribution in the rejection phase. To mitigate this issue, we propose a meticulous acceptance-rejection sampling method with a proper upper bound, thereby circumventing complex integration. Experimental results show that our continuous speculative decoding achieves a remarkable $2.33\times$ speed-up on off-the-shelf models while maintaining the output distribution. Codes will be available at https://github.com/MarkXCloud/CSpD
Expanding Accurate Person Recognition to New Altitudes and Ranges: The BRIAR Dataset
Nov 03, 2022



Face recognition technology has advanced significantly in recent years due largely to the availability of large and increasingly complex training datasets for use in deep learning models. These datasets, however, typically comprise images scraped from news sites or social media platforms and, therefore, have limited utility in more advanced security, forensics, and military applications. These applications require lower resolution, longer ranges, and elevated viewpoints. To meet these critical needs, we collected and curated the first and second subsets of a large multi-modal biometric dataset designed for use in the research and development (R&D) of biometric recognition technologies under extremely challenging conditions. Thus far, the dataset includes more than 350,000 still images and over 1,300 hours of video footage of approximately 1,000 subjects. To collect this data, we used Nikon DSLR cameras, a variety of commercial surveillance cameras, specialized long-rage R&D cameras, and Group 1 and Group 2 UAV platforms. The goal is to support the development of algorithms capable of accurately recognizing people at ranges up to 1,000 m and from high angles of elevation. These advances will include improvements to the state of the art in face recognition and will support new research in the area of whole-body recognition using methods based on gait and anthropometry. This paper describes methods used to collect and curate the dataset, and the dataset's characteristics at the current stage.
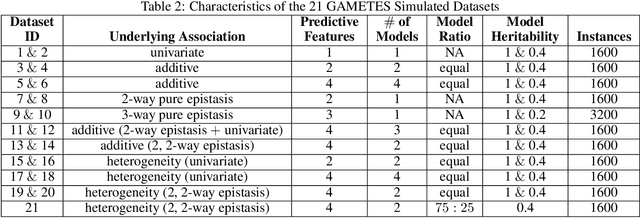
STREAMLINE: A Simple, Transparent, End-To-End Automated Machine Learning Pipeline Facilitating Data Analysis and Algorithm Comparison
Jun 23, 2022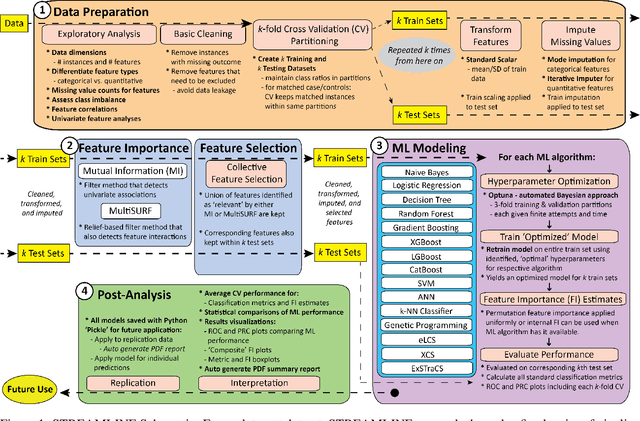
Machine learning (ML) offers powerful methods for detecting and modeling associations often in data with large feature spaces and complex associations. Many useful tools/packages (e.g. scikit-learn) have been developed to make the various elements of data handling, processing, modeling, and interpretation accessible. However, it is not trivial for most investigators to assemble these elements into a rigorous, replicatable, unbiased, and effective data analysis pipeline. Automated machine learning (AutoML) seeks to address these issues by simplifying the process of ML analysis for all. Here, we introduce STREAMLINE, a simple, transparent, end-to-end AutoML pipeline designed as a framework to easily conduct rigorous ML modeling and analysis (limited initially to binary classification). STREAMLINE is specifically designed to compare performance between datasets, ML algorithms, and other AutoML tools. It is unique among other autoML tools by offering a fully transparent and consistent baseline of comparison using a carefully designed series of pipeline elements including: (1) exploratory analysis, (2) basic data cleaning, (3) cross validation partitioning, (4) data scaling and imputation, (5) filter-based feature importance estimation, (6) collective feature selection, (7) ML modeling with `Optuna' hyperparameter optimization across 15 established algorithms (including less well-known Genetic Programming and rule-based ML), (8) evaluation across 16 classification metrics, (9) model feature importance estimation, (10) statistical significance comparisons, and (11) automatically exporting all results, plots, a PDF summary report, and models that can be easily applied to replication data.
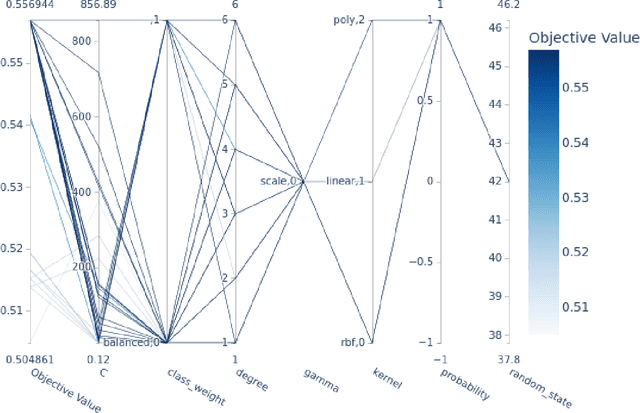
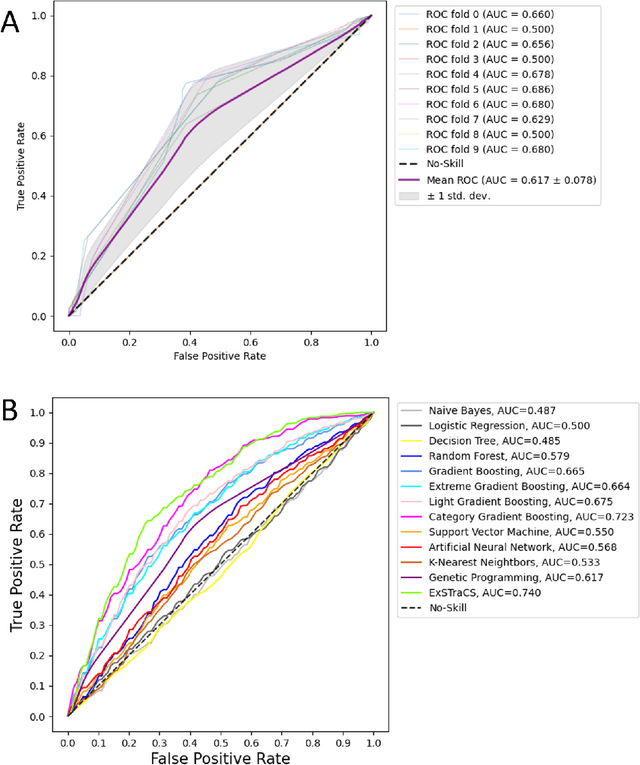
LCS-DIVE: An Automated Rule-based Machine Learning Visualization Pipeline for Characterizing Complex Associations in Classification
Apr 26, 2021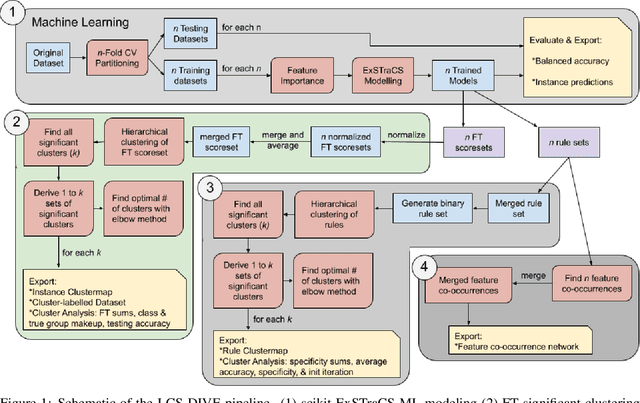
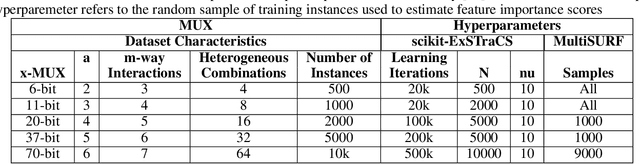
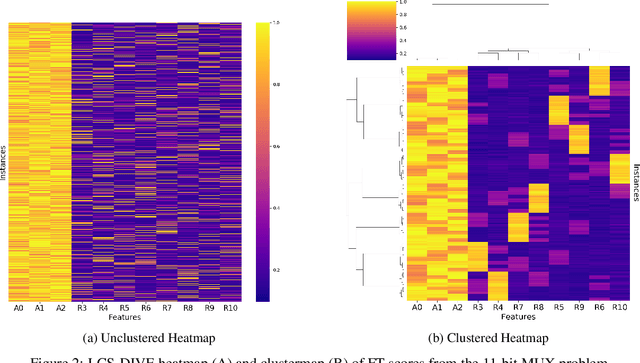
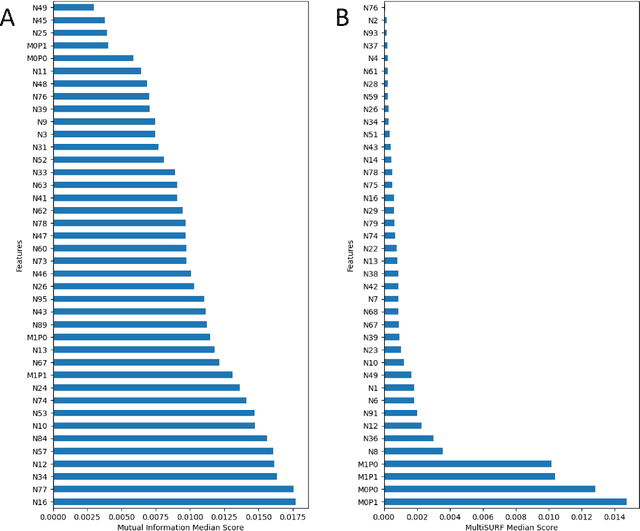
Machine learning (ML) research has yielded powerful tools for training accurate prediction models despite complex multivariate associations (e.g. interactions and heterogeneity). In fields such as medicine, improved interpretability of ML modeling is required for knowledge discovery, accountability, and fairness. Rule-based ML approaches such as Learning Classifier Systems (LCSs) strike a balance between predictive performance and interpretability in complex, noisy domains. This work introduces the LCS Discovery and Visualization Environment (LCS-DIVE), an automated LCS model interpretation pipeline for complex biomedical classification. LCS-DIVE conducts modeling using a new scikit-learn implementation of ExSTraCS, an LCS designed to overcome noise and scalability in biomedical data mining yielding human readable IF:THEN rules as well as feature-tracking scores for each training sample. LCS-DIVE leverages feature-tracking scores and/or rules to automatically guide characterization of (1) feature importance (2) underlying additive, epistatic, and/or heterogeneous patterns of association, and (3) model-driven heterogeneous instance subgroups via clustering, visualization generation, and cluster interrogation. LCS-DIVE was evaluated over a diverse set of simulated genetic and benchmark datasets encoding a variety of complex multivariate associations, demonstrating its ability to differentiate between them and then applied to characterize associations within a real-world study of pancreatic cancer.
A Fog Robotic System for Dynamic Visual Servoing
Sep 16, 2018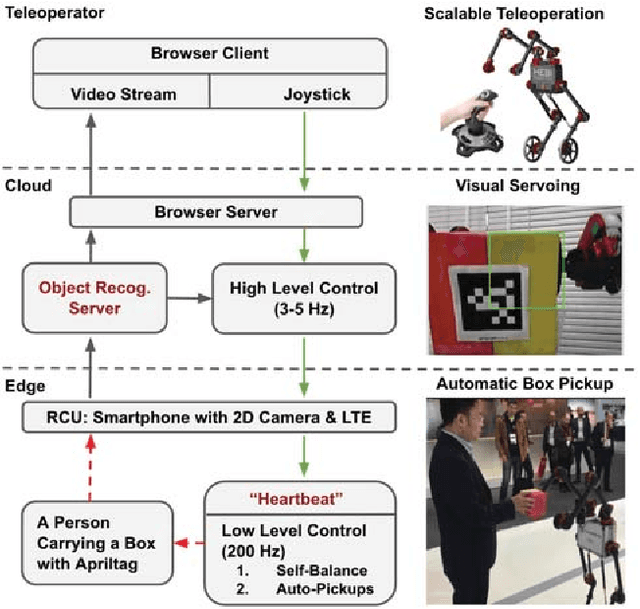

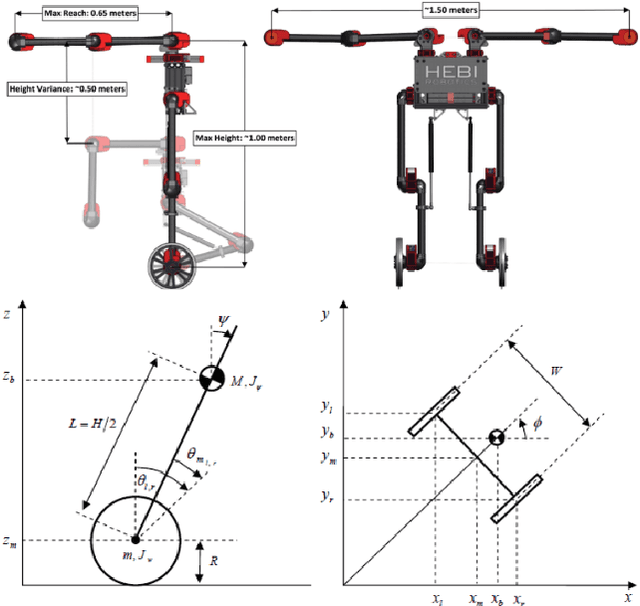
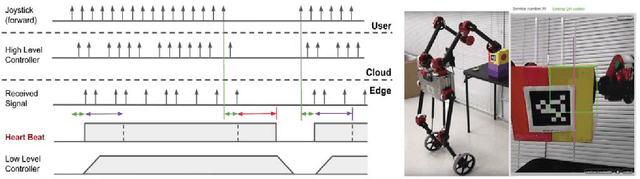
Cloud Robotics is a paradigm where distributed robots are connected to cloud services via networks to access unlimited computation power, at the cost of network communication. However, due to limitations such as network latency and variability, it is difficult to control dynamic, human compliant service robots directly from the cloud. In this work, by leveraging asynchronous protocol with a heartbeat signal, we combine cloud robotics with a smart edge device to build a Fog Robotic system. We use the system to enable robust teleoperation of a dynamic self-balancing robot from the cloud. We first use the system to pick up boxes from static locations, a task commonly performed in warehouse logistics. To make cloud teleoperation more efficient, we deploy image based visual servoing (IBVS) to perform box pickups automatically. Visual feedbacks, including apriltag recognition and tracking, are performed in the cloud to emulate a Fog Robotic object recognition system for IBVS. We demonstrate the feasibility of real-time dynamic automation system using this cloud-edge hybrid, which opens up possibilities of deploying dynamic robotic control with deep-learning recognition systems in Fog Robotics. Finally, we show that Fog Robotics enables the self-balancing service robot to pick up a box automatically from a person under unstructured environments.