 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.
Satisfiability-Aided Language Models Using Declarative Prompting
May 17, 2023Prior work has combined chain-of-thought prompting in large language models (LLMs) with programmatic representations to perform effective and transparent reasoning. While such an approach works very well for tasks that only require forward reasoning (e.g., straightforward arithmetic), it is less effective for constraint solving problems that require more sophisticated planning and search. In this paper, we propose a new satisfiability-aided language modeling (SATLM) approach for improving the reasoning capabilities of LLMs. We use an LLM to generate a declarative task specification rather than an imperative program and leverage an off-the-shelf automated theorem prover to derive the final answer. This approach has two key advantages. The declarative specification is closer to the problem description than the reasoning steps are, so the LLM can parse it out of the description more accurately. Furthermore, by offloading the actual reasoning task to an automated theorem prover, our approach can guarantee the correctness of the answer with respect to the parsed specification and avoid planning errors in the solving process. We evaluate SATLM on 6 different datasets and show that it consistently outperforms program-aided LMs in an imperative paradigm. In particular, SATLM outperforms program-aided LMs by 23% on a challenging subset of the GSM arithmetic reasoning dataset; SATLM also achieves a new SoTA on LSAT, surpassing previous models that are trained on the full training set.
ImageEye: Batch Image Processing Using Program Synthesis
Apr 10, 2023



This paper presents a new synthesis-based approach for batch image processing. Unlike existing tools that can only apply global edits to the entire image, our method can apply fine-grained edits to individual objects within the image. For example, our method can selectively blur or crop specific objects that have a certain property. To facilitate such fine-grained image editing tasks, we propose a neuro-symbolic domain-specific language (DSL) that combines pre-trained neural networks for image classification with other language constructs that enable symbolic reasoning. Our method can automatically learn programs in this DSL from user demonstrations by utilizing a novel synthesis algorithm. We have implemented the proposed technique in a tool called ImageEye and evaluated it on 50 image editing tasks. Our evaluation shows that ImageEye is able to automate 96% of these tasks.
Optimal Neural Program Synthesis from Multimodal Specifications
Oct 04, 2020



Multimodal program synthesis, which leverages different types of user input to synthesize a desired program, is an attractive way to scale program synthesis to challenging settings; however, it requires integrating noisy signals from the user (like natural language) with hard constraints on the program's behavior. This paper proposes an optimal neural synthesis approach where the goal is to find a program that satisfies user-provided constraints while also maximizing the program's score with respect to a neural model. Specifically, we focus on multimodal synthesis tasks in which the user intent is expressed using combination of natural language (NL) and input-output examples. At the core of our method is a top-down recurrent neural model that places distributions over abstract syntax trees conditioned on the NL input. This model not only allows for efficient search over the space of syntactically valid programs, but it allows us to leverage automated program analysis techniques for pruning the search space based on infeasibility of partial programs with respect to the user's constraints. The experimental results on a multimodal synthesis dataset (StructuredRegex) show that our method substantially outperforms prior state-of-the-art techniques in terms of accuracy %, finds model-optimal programs more frequently, and explores fewer states during search.
Benchmarking Multimodal Regex Synthesis with Complex Structures
May 02, 2020
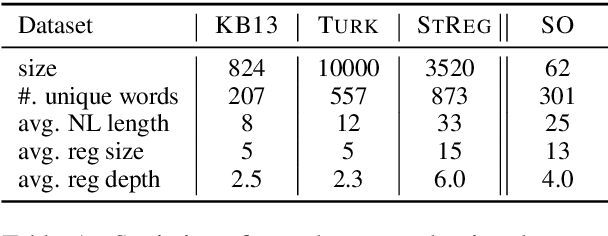


Existing datasets for regular expression (regex) generation from natural language are limited in complexity; compared to regex tasks that users post on StackOverflow, the regexes in these datasets are simple, and the language used to describe them is not diverse. We introduce StructuredRegex, a new regex synthesis dataset differing from prior ones in three aspects. First, to obtain structurally complex and realistic regexes, we generate the regexes using a probabilistic grammar with pre-defined macros observed from real-world StackOverflow posts. Second, to obtain linguistically diverse natural language descriptions, we show crowdworkers abstract depictions of the underlying regex and ask them to describe the pattern they see, rather than having them paraphrase synthetic language. Third, we augment each regex example with a collection of strings that are and are not matched by the ground truth regex, similar to how real users give examples. Our quantitative and qualitative analysis demonstrates the advantages of StructuredRegex over prior datasets. Further experimental results using various multimodal synthesis techniques highlight the challenge presented by our dataset, including non-local constraints and multi-modal inputs.
Sketch-Driven Regular Expression Generation from Natural Language and Examples
Aug 16, 2019


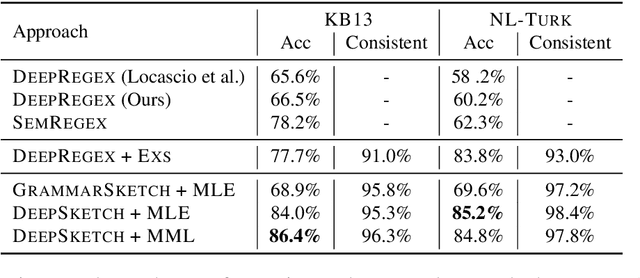
Recent systems for converting natural language descriptions into regular expressions have achieved some success, but typically deal with short, formulaic text and can only produce simple regular expressions, limiting their applicability. Real-world regular expressions are complex, hard to describe with brief sentences, and sometimes require examples to fully convey the user's intent. We present a framework for regular expression synthesis in this setting where both natural language and examples are available. First, a semantic parser (either grammar-based or neural) maps the natural language description into an intermediate sketch, which is an incomplete regular expression containing holes to denote missing components. Then a program synthesizer enumerates the regular expression space defined by the sketch and finds a regular expression that is consistent with the given string examples. Our semantic parser can be trained from supervised or heuristically-derived sketches and additionally fine-tuned with weak supervision based on correctness of the synthesized regex. We conduct experiments on two public large-scale datasets (Kushman and Barzilay, 2013; Locascio et al., 2016) and a real-world dataset we collected from StackOverflow. Our system achieves state-of-the-art performance on the public datasets and successfully solves 57% of the real-world dataset, which existing neural systems completely fail on.