 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Multi-Site Clinical Data: A Federated Approach to Privacy-First Child Autism Behavior Analysis
Apr 03, 2026Automated recognition of autistic behaviors in children is essential for early intervention and objective clinical assessment. However, the development of robust models is severely hindered by strict privacy regulations (e.g., HIPAA) and the sensitive nature of pediatric data, which prevents the centralized aggregation of clinical datasets. Furthermore, individual clinical sites often suffer from data scarcity, making it difficult to learn generalized behavior patterns or tailor models to site-specific patient distributions. To address these challenges, we observe that Federated Learning (FL) can decouple model training from raw data access, enabling multi-site collaboration while maintaining strict data residency. In this paper, we present the first study exploring Federated Learning for pose-based child autism behavior recognition. Our framework employs a two-layer privacy protection mechanism: utilizing human skeletal abstraction to remove identifiable visual information from the raw RGB videos and FL to ensure sensitive pose data remains within the clinic. This approach leverages distributed clinical data to learn generalized representations while providing the flexibility for site-specific personalization. Experimental results on the MMASD benchmark demonstrate that our framework achieves high recognition accuracy, outperforming traditional federated baselines and providing a robust, privacy-first solution for multi-site clinical analysis.
DEAF: A Benchmark for Diagnostic Evaluation of Acoustic Faithfulness in Audio Language Models
Mar 17, 2026Recent Audio Multimodal Large Language Models (Audio MLLMs) demonstrate impressive performance on speech benchmarks, yet it remains unclear whether these models genuinely process acoustic signals or rely on text-based semantic inference. To systematically study this question, we introduce DEAF (Diagnostic Evaluation of Acoustic Faithfulness), a benchmark of over 2,700 conflict stimuli spanning three acoustic dimensions: emotional prosody, background sounds, and speaker identity. Then, we design a controlled multi-level evaluation framework that progressively increases textual influence, ranging from semantic conflicts in the content to misleading prompts and their combination, allowing us to disentangle content-driven bias from prompt-induced sycophancy. We further introduce diagnostic metrics to quantify model reliance on textual cues over acoustic signals. Our evaluation of seven Audio MLLMs reveals a consistent pattern of text dominance: models are sensitive to acoustic variations, yet predictions are predominantly driven by textual inputs, revealing a gap between high performance on standard speech benchmarks and genuine acoustic understanding.
TrustMH-Bench: A Comprehensive Benchmark for Evaluating the Trustworthiness of Large Language Models in Mental Health
Mar 03, 2026While Large Language Models (LLMs) demonstrate significant potential in providing accessible mental health support, their practical deployment raises critical trustworthiness concerns due to the domains high-stakes and safety-sensitive nature. Existing evaluation paradigms for general-purpose LLMs fail to capture mental health-specific requirements, highlighting an urgent need to prioritize and enhance their trustworthiness. To address this, we propose TrustMH-Bench, a holistic framework designed to systematically quantify the trustworthiness of mental health LLMs. By establishing a deep mapping from domain-specific norms to quantitative evaluation metrics, TrustMH-Bench evaluates models across eight core pillars: Reliability, Crisis Identification and Escalation, Safety, Fairness, Privacy, Robustness, Anti-sycophancy, and Ethics. We conduct extensive experiments across six general-purpose LLMs and six specialized mental health models. Experimental results indicate that the evaluated models underperform across various trustworthiness dimensions in mental health scenarios, revealing significant deficiencies. Notably, even generally powerful models (e.g., GPT-5.1) fail to maintain consistently high performance across all dimensions. Consequently, systematically improving the trustworthiness of LLMs has become a critical task. Our data and code are released.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
V-FAT: Benchmarking Visual Fidelity Against Text-bias
Jan 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive performance on standard visual reasoning benchmarks. However, there is growing concern that these models rely excessively on linguistic shortcuts rather than genuine visual grounding, a phenomenon we term Text Bias. In this paper, we investigate the fundamental tension between visual perception and linguistic priors. We decouple the sources of this bias into two dimensions: Internal Corpus Bias, stemming from statistical correlations in pretraining, and External Instruction Bias, arising from the alignment-induced tendency toward sycophancy. To quantify this effect, we introduce V-FAT (Visual Fidelity Against Text-bias), a diagnostic benchmark comprising 4,026 VQA instances across six semantic domains. V-FAT employs a Three-Level Evaluation Framework that systematically increases the conflict between visual evidence and textual information: (L1) internal bias from atypical images, (L2) external bias from misleading instructions, and (L3) synergistic bias where both coincide. We introduce the Visual Robustness Score (VRS), a metric designed to penalize "lucky" linguistic guesses and reward true visual fidelity. Our evaluation of 12 frontier MLLMs reveals that while models excel in existing benchmarks, they experience significant visual collapse under high linguistic dominance.
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025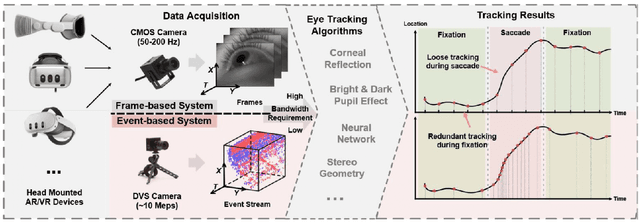
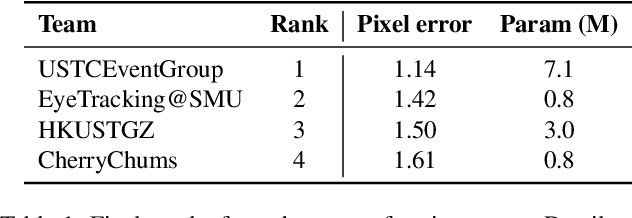
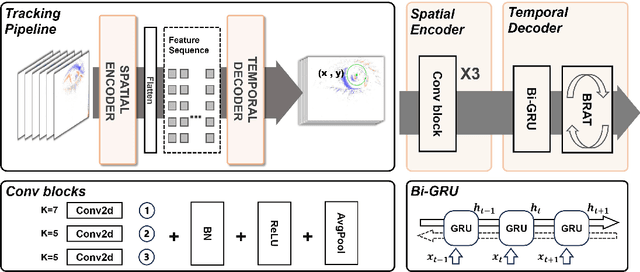

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
Dec 19, 2024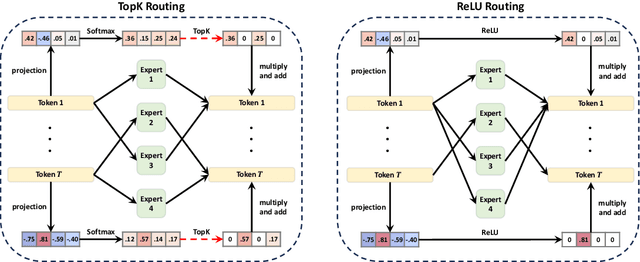

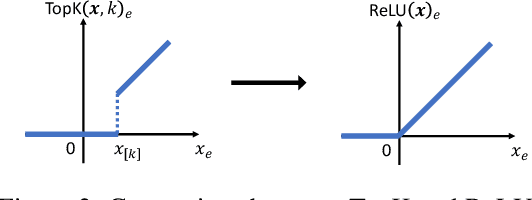
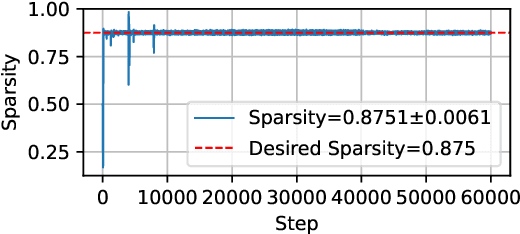
Sparsely activated Mixture-of-Experts (MoE) models are widely adopted to scale up model capacity without increasing the computation budget. However, vanilla TopK routers are trained in a discontinuous, non-differentiable way, limiting their performance and scalability. To address this issue, we propose ReMoE, a fully differentiable MoE architecture that offers a simple yet effective drop-in replacement for the conventional TopK+Softmax routing, utilizing ReLU as the router instead. We further propose methods to regulate the router's sparsity while balancing the load among experts. ReMoE's continuous nature enables efficient dynamic allocation of computation across tokens and layers, while also exhibiting domain specialization. Our experiments demonstrate that ReMoE consistently outperforms vanilla TopK-routed MoE across various model sizes, expert counts, and levels of granularity. Furthermore, ReMoE exhibits superior scalability with respect to the number of experts, surpassing traditional MoE architectures. The implementation based on Megatron-LM is available at https://github.com/thu-ml/ReMoE.
Efficient Backpropagation with Variance-Controlled Adaptive Sampling
Feb 27, 2024Sampling-based algorithms, which eliminate ''unimportant'' computations during forward and/or back propagation (BP), offer potential solutions to accelerate neural network training. However, since sampling introduces approximations to training, such algorithms may not consistently maintain accuracy across various tasks. In this work, we introduce a variance-controlled adaptive sampling (VCAS) method designed to accelerate BP. VCAS computes an unbiased stochastic gradient with fine-grained layerwise importance sampling in data dimension for activation gradient calculation and leverage score sampling in token dimension for weight gradient calculation. To preserve accuracy, we control the additional variance by learning the sample ratio jointly with model parameters during training. We assessed VCAS on multiple fine-tuning and pre-training tasks in both vision and natural language domains. On all the tasks, VCAS can preserve the original training loss trajectory and validation accuracy with an up to 73.87% FLOPs reduction of BP and 49.58% FLOPs reduction of the whole training process. The implementation is available at https://github.com/thu-ml/VCAS .