 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualSep: A Light-weight dual-encoder convolutional recurrent network for real-time in-car speech separation
Sep 13, 2024



Advancements in deep learning and voice-activated technologies have driven the development of human-vehicle interaction. Distributed microphone arrays are widely used in in-car scenarios because they can accurately capture the voices of passengers from different speech zones. However, the increase in the number of audio channels, coupled with the limited computational resources and low latency requirements of in-car systems, presents challenges for in-car multi-channel speech separation. To migrate the problems, we propose a lightweight framework that cascades digital signal processing (DSP) and neural networks (NN). We utilize fixed beamforming (BF) to reduce computational costs and independent vector analysis (IVA) to provide spatial prior. We employ dual encoders for dual-branch modeling, with spatial encoder capturing spatial cues and spectral encoder preserving spectral information, facilitating spatial-spectral fusion. Our proposed system supports both streaming and non-streaming modes. Experimental results demonstrate the superiority of the proposed system across various metrics. With only 0.83M parameters and 0.39 real-time factor (RTF) on an Intel Core i7 (2.6GHz) CPU, it effectively separates speech into distinct speech zones. Our demos are available at https://honee-w.github.io/DualSep/.
BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators
Jan 08, 2024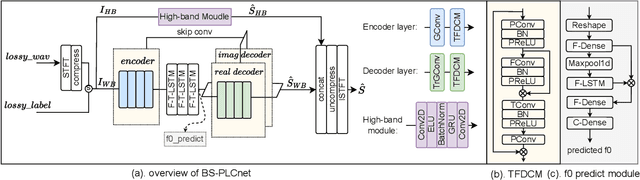

Packet loss is a common and unavoidable problem in voice over internet phone (VoIP) systems. To deal with the problem, we propose a band-split packet loss concealment network (BS-PLCNet). Specifically, we split the full-band signal into wide-band (0-8kHz) and high-band (8-24kHz). The wide-band signals are processed by a gated convolutional recurrent network (GCRN), while the high-band counterpart is processed by a simple GRU network. To ensure high speech quality and automatic speech recognition (ASR) compatibility, multi-task learning (MTL) framework including fundamental frequency (f0) prediction, linguistic awareness, and multi-discriminators are used. The proposed approach tied for 1st place in the ICASSP 2024 PLC Challenge.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
ICMC-ASR: The ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition Challenge
Jan 07, 2024

To promote speech processing and recognition research in driving scenarios, we build on the success of the Intelligent Cockpit Speech Recognition Challenge (ICSRC) held at ISCSLP 2022 and launch the ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) Challenge. This challenge collects over 100 hours of multi-channel speech data recorded inside a new energy vehicle and 40 hours of noise for data augmentation. Two tracks, including automatic speech recognition (ASR) and automatic speech diarization and recognition (ASDR) are set up, using character error rate (CER) and concatenated minimum permutation character error rate (cpCER) as evaluation metrics, respectively. Overall, the ICMC-ASR Challenge attracts 98 participating teams and receives 53 valid results in both tracks. In the end, first-place team USTCiflytek achieves a CER of 13.16% in the ASR track and a cpCER of 21.48% in the ASDR track, showing an absolute improvement of 13.08% and 51.4% compared to our challenge baseline, respectively.
An Exploration of Task-decoupling on Two-stage Neural Post Filter for Real-time Personalized Acoustic Echo Cancellation
Oct 07, 2023Deep learning based techniques have been popularly adopted in acoustic echo cancellation (AEC). Utilization of speaker representation has extended the frontier of AEC, thus attracting many researchers' interest in personalized acoustic echo cancellation (PAEC). Meanwhile, task-decoupling strategies are widely adopted in speech enhancement. To further explore the task-decoupling approach, we propose to use a two-stage task-decoupling post-filter (TDPF) in PAEC. Furthermore, a multi-scale local-global speaker representation is applied to improve speaker extraction in PAEC. Experimental results indicate that the task-decoupling model can yield better performance than a single joint network. The optimal approach is to decouple the echo cancellation from noise and interference speech suppression. Based on the task-decoupling sequence, optimal training strategies for the two-stage model are explored afterwards.
Multi-Task Sub-Band Network For Deep Residual Echo Suppression
Mar 11, 2023This paper introduces the SWANT team entry to the ICASSP 2023 AEC Challenge. We submit a system that cascades a linear filter with a neural post-filter. Particularly, we adopt sub-band processing to handle full-band signals and shape the network with multi-task learning, where dual signal voice activity detection (DSVAD) and echo estimation are adopted as auxiliary tasks. Moreover, we particularly improve the time frequency convolution module (TFCM) to increase the receptive field using small convolution kernels. Finally, our system has ranked 4th in ICASSP 2023 AEC Challenge Non-personalized track.
Multi-Task Deep Residual Echo Suppression with Echo-aware Loss
Feb 21, 2022

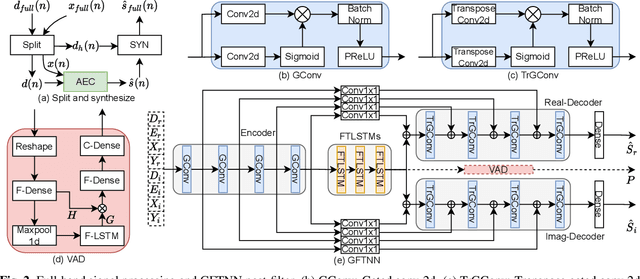
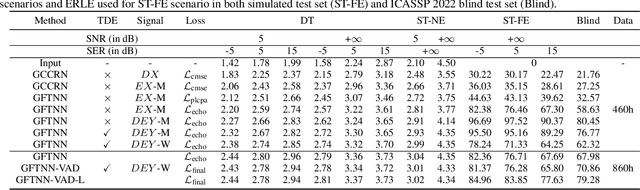
This paper introduces the NWPU Team's entry to the ICASSP 2022 AEC Challenge. We take a hybrid approach that cascades a linear AEC with a neural post-filter. The former is used to deal with the linear echo components while the latter suppresses the residual non-linear echo components. We use gated convolutional F-T-LSTM neural network (GFTNN) as the backbone and shape the post-filter by a multi-task learning (MTL) framework, where a voice activity detection (VAD) module is adopted as an auxiliary task along with echo suppression, with the aim to avoid over suppression that may cause speech distortion. Moreover, we adopt an echo-aware loss function, where the mean square error (MSE) loss can be optimized particularly for every time-frequency bin (TF-bin) according to the signal-to-echo ratio (SER), leading to further suppression on the echo. Extensive ablation study shows that the time delay estimation (TDE) module in neural post-filter leads to better perceptual quality, and an adaptive filter with better convergence will bring consistent performance gain for the post-filter. Besides, we find that using the linear echo as the input of our neural post-filter is a better choice than using the reference signal directly. In the ICASSP 2022 AEC-Challenge, our approach has ranked the 1st place on word accuracy (WAcc) (0.817) and the 3rd place on both mean opinion score (MOS) (4.502) and the final score (0.864).
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021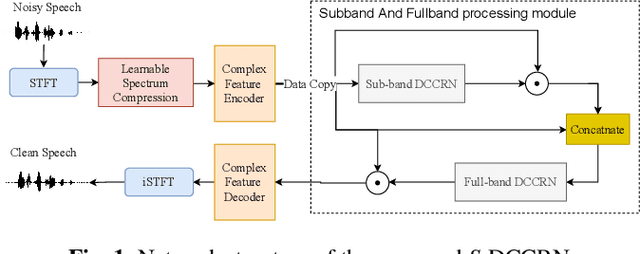
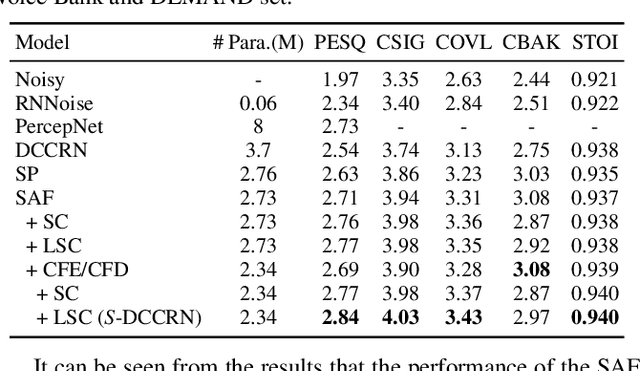
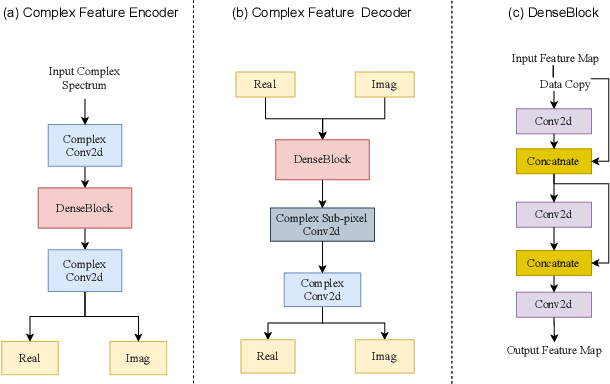
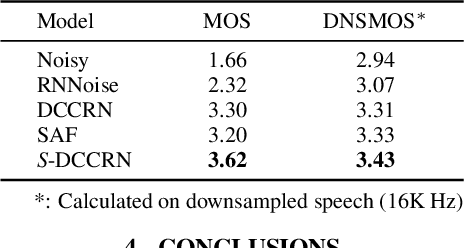
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.
A Two-stream End-to-End Deep Learning Network for Recognizing Atypical Visual Attention in Autism Spectrum Disorder
Nov 26, 2019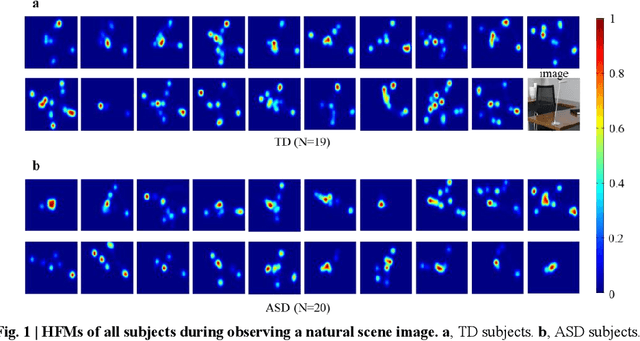
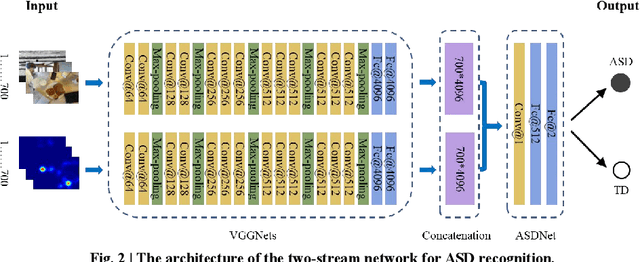
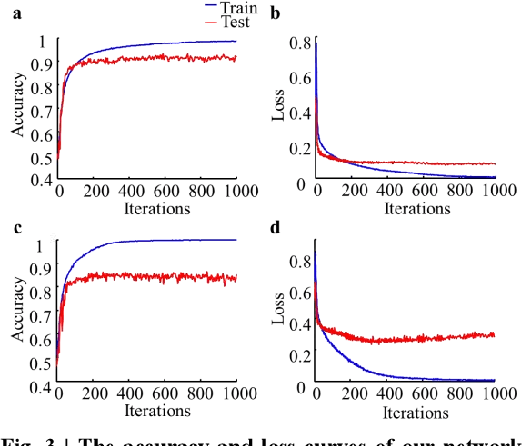
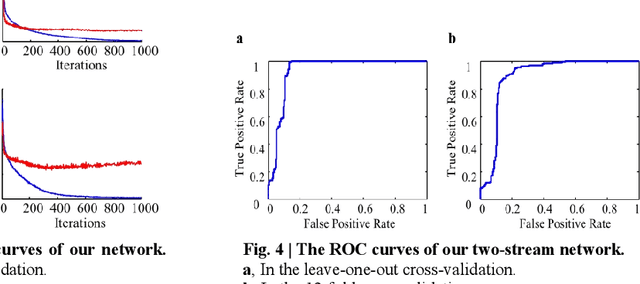
Eye movements have been widely investigated to study the atypical visual attention in Autism Spectrum Disorder (ASD). The majority of these studies have been focused on limited eye movement features by statistical comparisons between ASD and Typically Developing (TD) groups, which make it difficult to accurately separate ASD from TD at the individual level. The deep learning technology has been highly successful in overcoming this issue by automatically extracting features important for classification through a data-driven learning process. However, there is still a lack of end-to-end deep learning framework for recognition of abnormal attention in ASD. In this study, we developed a novel two-stream deep learning network for this recognition based on 700 images and corresponding eye movement patterns of ASD and TD, and obtained an accuracy of 0.95, which was higher than the previous state-of-the-art. We next characterized contributions to the classification at the single image level and non-linearly integration of this single image level information during the classification. Moreover, we identified a group of pixel-level visual features within these images with greater impacts on the classification. Together, this two-stream deep learning network provides us a novel and powerful tool to recognize and understand abnormal visual attention in ASD.