 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Sub-Band Network For Deep Residual Echo Suppression
Mar 11, 2023


This paper introduces the SWANT team entry to the ICASSP 2023 AEC Challenge. We submit a system that cascades a linear filter with a neural post-filter. Particularly, we adopt sub-band processing to handle full-band signals and shape the network with multi-task learning, where dual signal voice activity detection (DSVAD) and echo estimation are adopted as auxiliary tasks. Moreover, we particularly improve the time frequency convolution module (TFCM) to increase the receptive field using small convolution kernels. Finally, our system has ranked 4th in ICASSP 2023 AEC Challenge Non-personalized track.
The PCG-AIID System for L3DAS22 Challenge: MIMO and MISO convolutional recurrent Network for Multi Channel Speech Enhancement and Speech Recognition
Feb 21, 2022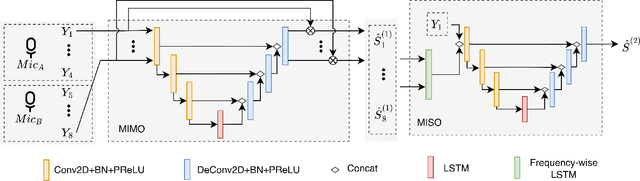
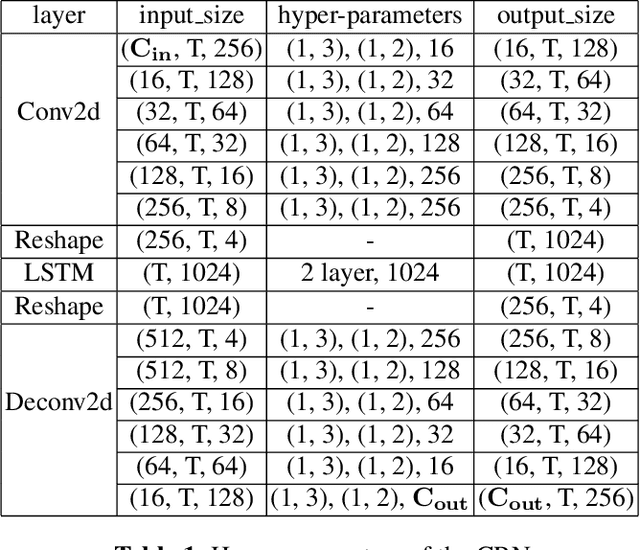
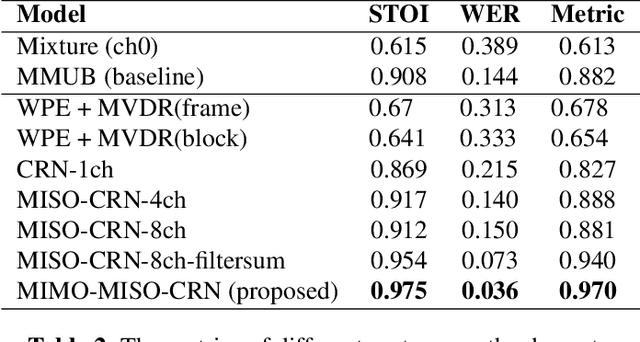
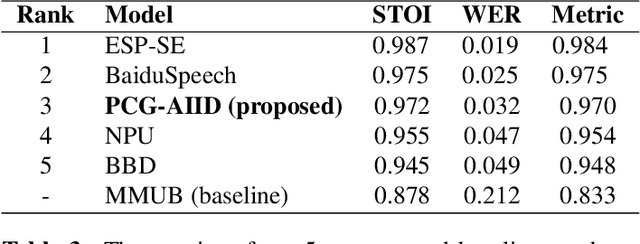
This paper described the PCG-AIID system for L3DAS22 challenge in Task 1: 3D speech enhancement in office reverberant environment. We proposed a two-stage framework to address multi-channel speech denoising and dereverberation. In the first stage, a multiple input and multiple output (MIMO) network is applied to remove background noise while maintaining the spatial characteristics of multi-channel signals. In the second stage, a multiple input and single output (MISO) network is applied to enhance the speech from desired direction and post-filtering. As a result, our system ranked 3rd place in ICASSP2022 L3DAS22 challenge and significantly outperforms the baseline system, while achieving 3.2% WER and 0.972 STOI on the blind test-set.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021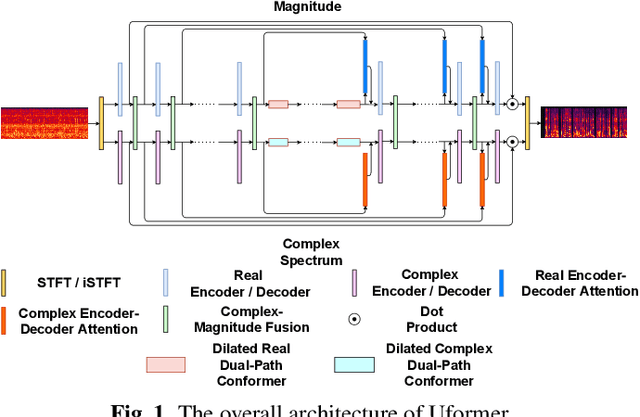
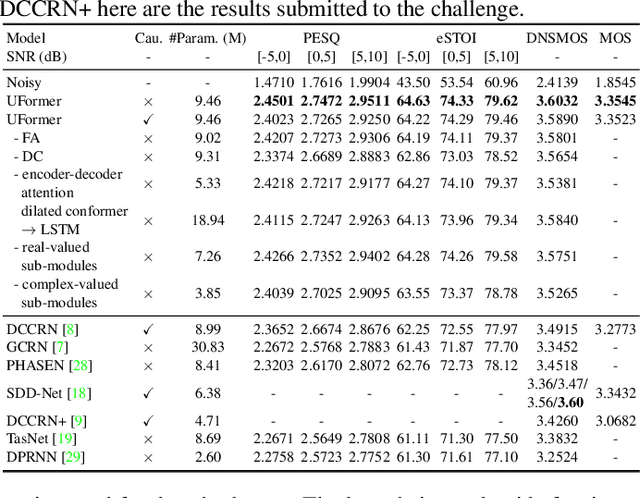
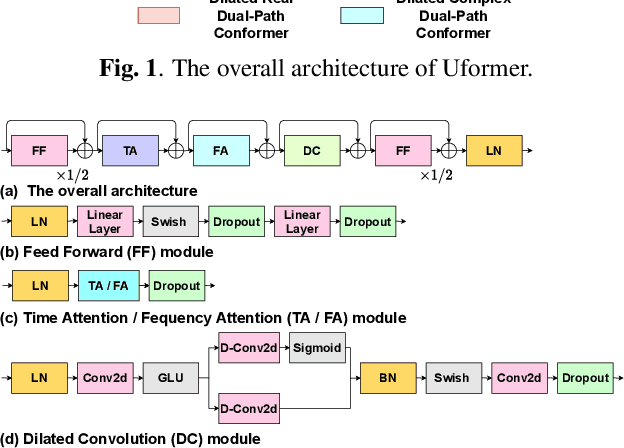
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.