 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
The PCG-AIID System for L3DAS22 Challenge: MIMO and MISO convolutional recurrent Network for Multi Channel Speech Enhancement and Speech Recognition
Feb 21, 2022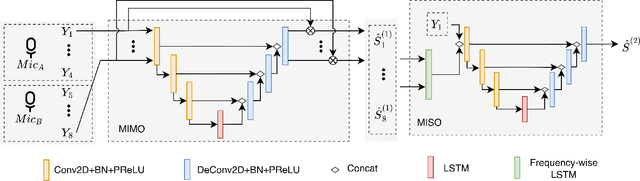
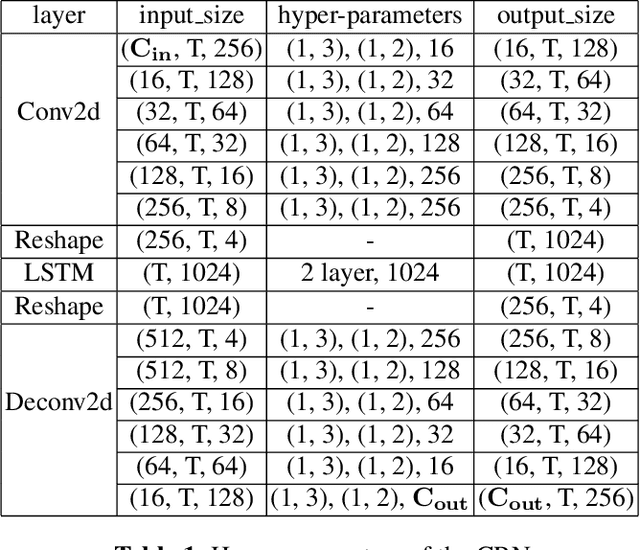
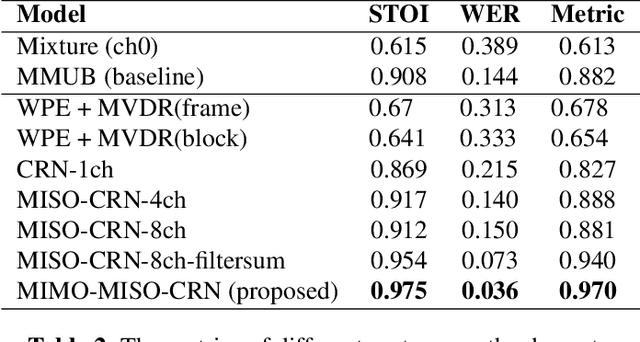
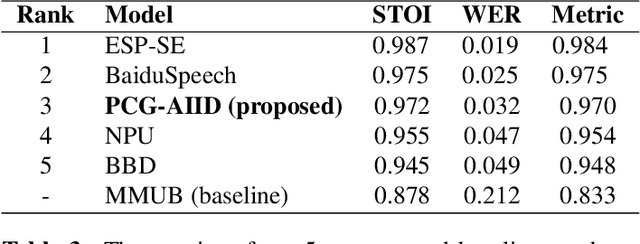
This paper described the PCG-AIID system for L3DAS22 challenge in Task 1: 3D speech enhancement in office reverberant environment. We proposed a two-stage framework to address multi-channel speech denoising and dereverberation. In the first stage, a multiple input and multiple output (MIMO) network is applied to remove background noise while maintaining the spatial characteristics of multi-channel signals. In the second stage, a multiple input and single output (MISO) network is applied to enhance the speech from desired direction and post-filtering. As a result, our system ranked 3rd place in ICASSP2022 L3DAS22 challenge and significantly outperforms the baseline system, while achieving 3.2% WER and 0.972 STOI on the blind test-set.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021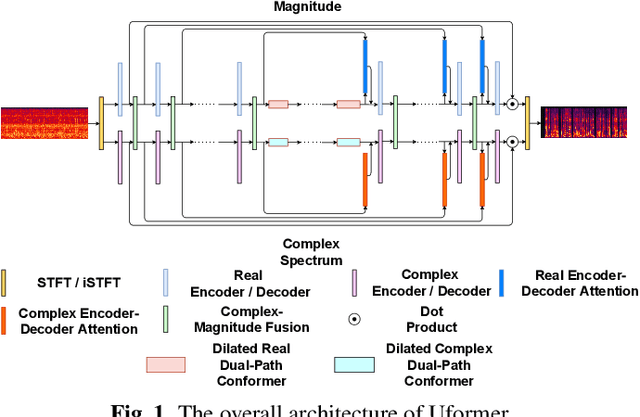
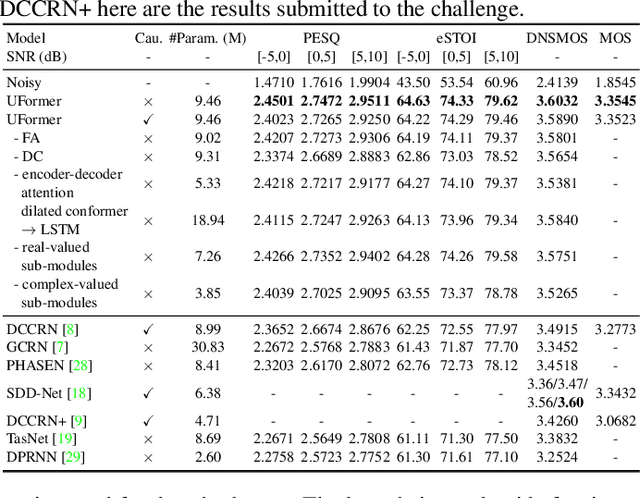
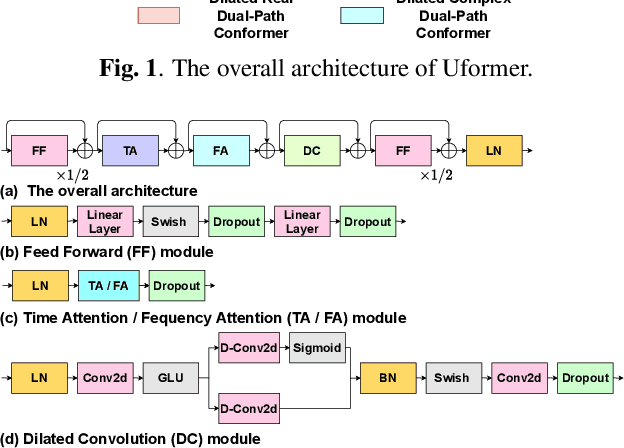
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.
Single Channel Speech Enhancement Using Temporal Convolutional Recurrent Neural Networks
Feb 02, 2020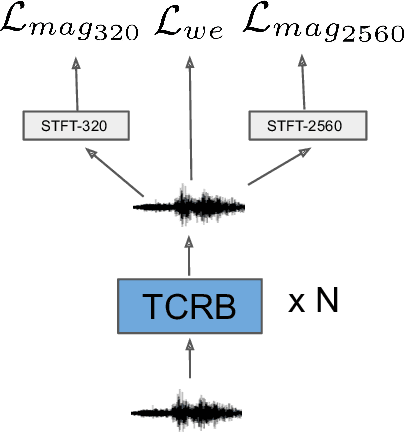
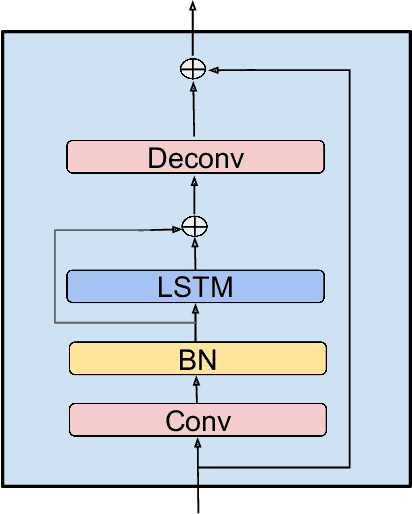

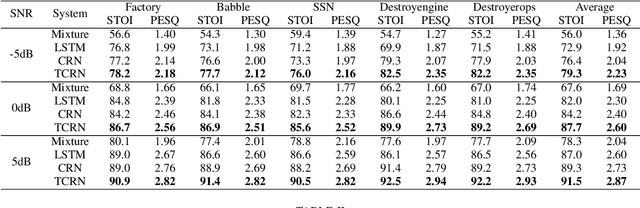
In recent decades, neural network based methods have significantly improved the performace of speech enhancement. Most of them estimate time-frequency (T-F) representation of target speech directly or indirectly, then resynthesize waveform using the estimated T-F representation. In this work, we proposed the temporal convolutional recurrent network (TCRN), an end-to-end model that directly map noisy waveform to clean waveform. The TCRN, which is combined convolution and recurrent neural network, is able to efficiently and effectively leverage short-term ang long-term information. Futuremore, we present the architecture that repeatedly downsample and upsample speech during forward propagation. We show that our model is able to improve the performance of model, compared with existing convolutional recurrent networks. Futuremore, We present several key techniques to stabilize the training process. The experimental results show that our model consistently outperforms existing speech enhancement approaches, in terms of speech intelligibility and quality.
Teacher-Student Training for Robust Tacotron-based TTS
Nov 07, 2019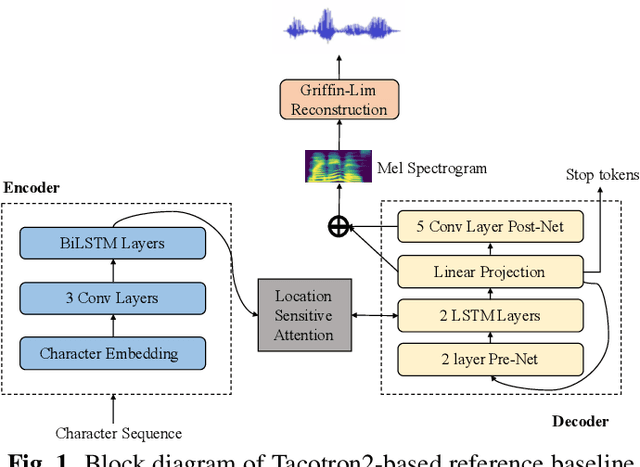
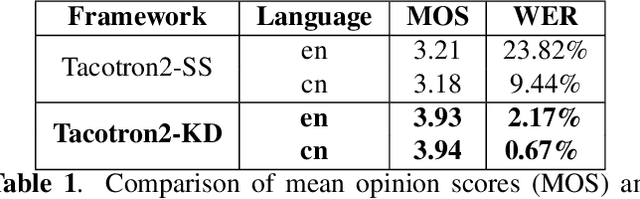
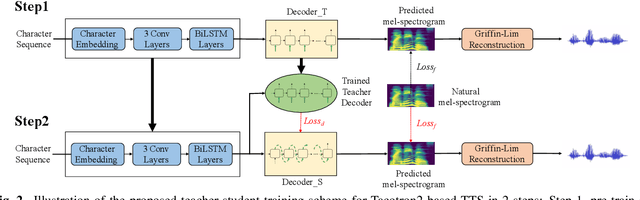
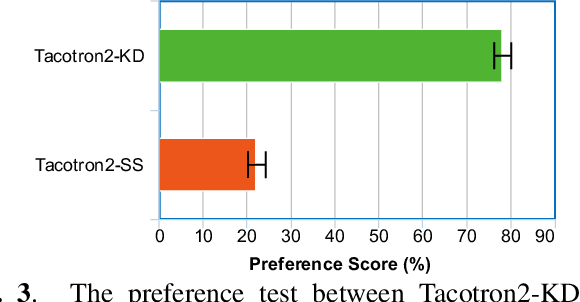
While neural end-to-end text-to-speech (TTS) is superior to conventional statistical methods in many ways, the exposure bias problem in the autoregressive models remains an issue to be resolved. The exposure bias problem arises from the mismatch between the training and inference process, that results in unpredictable performance for out-of-domain test data at run-time. To overcome this, we propose a teacher-student training scheme for Tacotron-based TTS by introducing a distillation loss function in addition to the feature loss function. We first train a Tacotron2-based TTS model by always providing natural speech frames to the decoder, that serves as a teacher model. We then train another Tacotron2-based model as a student model, of which the decoder takes the predicted speech frames as input, similar to how the decoder works during run-time inference. With the distillation loss, the student model learns the output probabilities from the teacher model, that is called knowledge distillation. Experiments show that our proposed training scheme consistently improves the voice quality for out-of-domain test data both in Chinese and English systems.