 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Student Training for Robust Tacotron-based TTS
Paper and Code
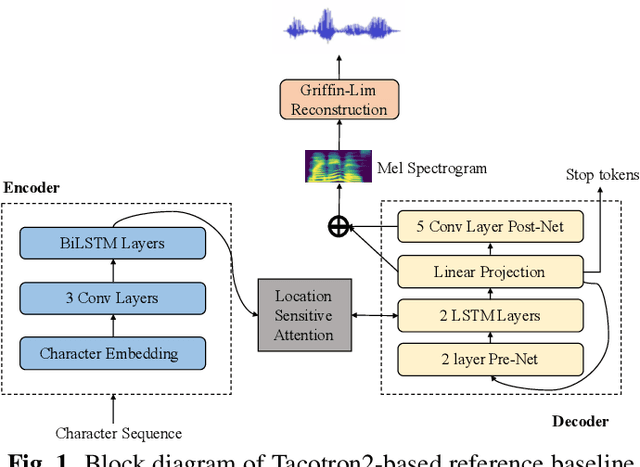
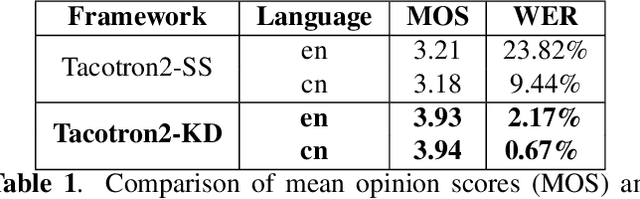
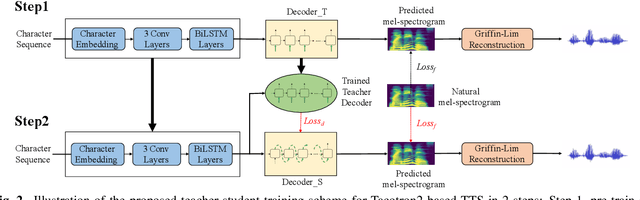
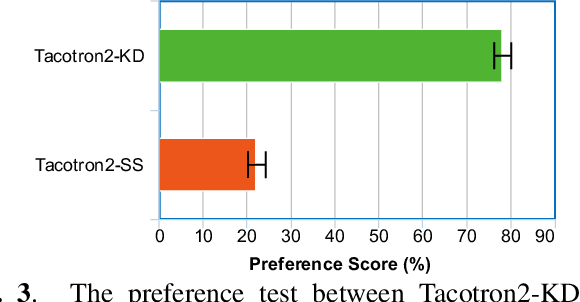
While neural end-to-end text-to-speech (TTS) is superior to conventional statistical methods in many ways, the exposure bias problem in the autoregressive models remains an issue to be resolved. The exposure bias problem arises from the mismatch between the training and inference process, that results in unpredictable performance for out-of-domain test data at run-time. To overcome this, we propose a teacher-student training scheme for Tacotron-based TTS by introducing a distillation loss function in addition to the feature loss function. We first train a Tacotron2-based TTS model by always providing natural speech frames to the decoder, that serves as a teacher model. We then train another Tacotron2-based model as a student model, of which the decoder takes the predicted speech frames as input, similar to how the decoder works during run-time inference. With the distillation loss, the student model learns the output probabilities from the teacher model, that is called knowledge distillation. Experiments show that our proposed training scheme consistently improves the voice quality for out-of-domain test data both in Chinese and English systems.