 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering and Causally Validating Emotion-Sensitive Neurons in Large Audio-Language Models
Jan 06, 2026Emotion is a central dimension of spoken communication, yet, we still lack a mechanistic account of how modern large audio-language models (LALMs) encode it internally. We present the first neuron-level interpretability study of emotion-sensitive neurons (ESNs) in LALMs and provide causal evidence that such units exist in Qwen2.5-Omni, Kimi-Audio, and Audio Flamingo 3. Across these three widely used open-source models, we compare frequency-, entropy-, magnitude-, and contrast-based neuron selectors on multiple emotion recognition benchmarks. Using inference-time interventions, we reveal a consistent emotion-specific signature: ablating neurons selected for a given emotion disproportionately degrades recognition of that emotion while largely preserving other classes, whereas gain-based amplification steers predictions toward the target emotion. These effects arise with modest identification data and scale systematically with intervention strength. We further observe that ESNs exhibit non-uniform layer-wise clustering with partial cross-dataset transfer. Taken together, our results offer a causal, neuron-level account of emotion decisions in LALMs and highlight targeted neuron interventions as an actionable handle for controllable affective behaviors.
NE-PADD: Leveraging Named Entity Knowledge for Robust Partial Audio Deepfake Detection via Attention Aggregation
Sep 04, 2025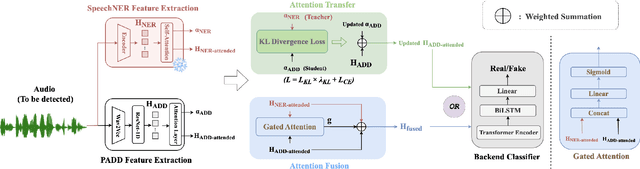
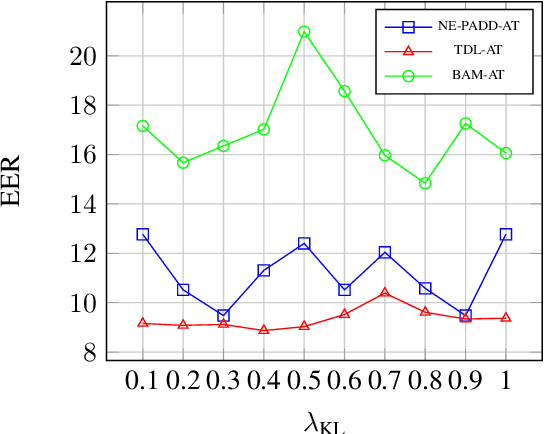
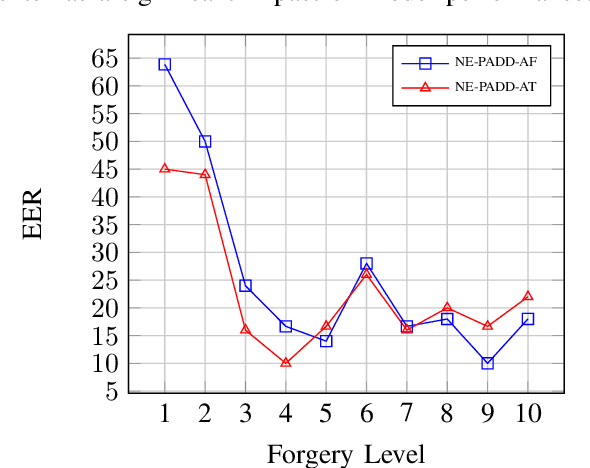
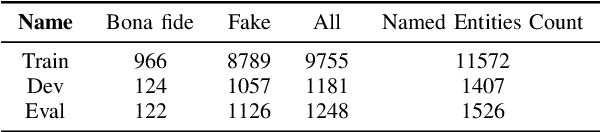
Different from traditional sentence-level audio deepfake detection (ADD), partial audio deepfake detection (PADD) requires frame-level positioning of the location of fake speech. While some progress has been made in this area, leveraging semantic information from audio, especially named entities, remains an underexplored aspect. To this end, we propose NE-PADD, a novel method for Partial Audio Deepfake Detection (PADD) that leverages named entity knowledge through two parallel branches: Speech Name Entity Recognition (SpeechNER) and PADD. The approach incorporates two attention aggregation mechanisms: Attention Fusion (AF) for combining attention weights and Attention Transfer (AT) for guiding PADD with named entity semantics using an auxiliary loss. Built on the PartialSpoof-NER dataset, experiments show our method outperforms existing baselines, proving the effectiveness of integrating named entity knowledge in PADD. The code is available at https://github.com/AI-S2-Lab/NE-PADD.
Can Emotion Fool Anti-spoofing?
May 29, 2025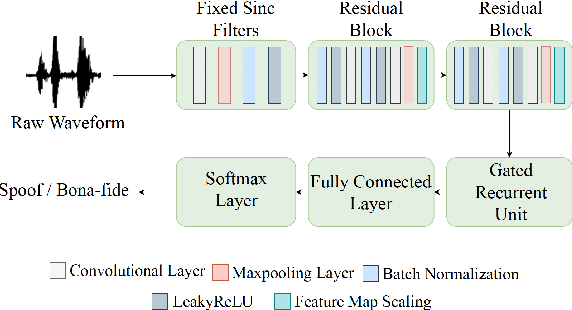
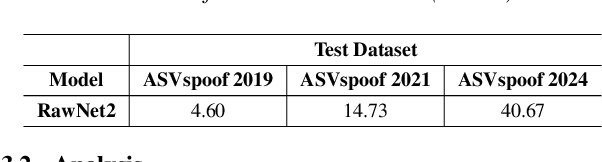
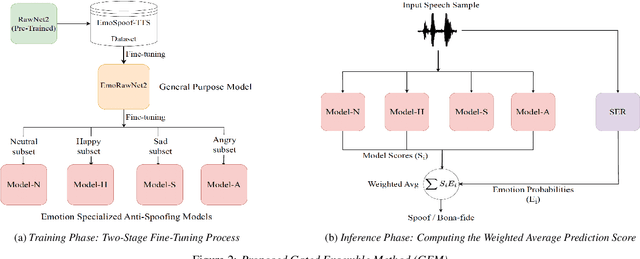
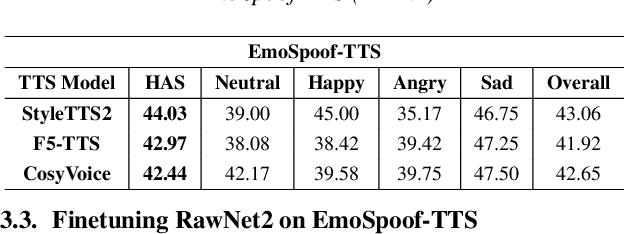
Traditional anti-spoofing focuses on models and datasets built on synthetic speech with mostly neutral state, neglecting diverse emotional variations. As a result, their robustness against high-quality, emotionally expressive synthetic speech is uncertain. We address this by introducing EmoSpoof-TTS, a corpus of emotional text-to-speech samples. Our analysis shows existing anti-spoofing models struggle with emotional synthetic speech, exposing risks of emotion-targeted attacks. Even trained on emotional data, the models underperform due to limited focus on emotional aspect and show performance disparities across emotions. This highlights the need for emotion-focused anti-spoofing paradigm in both dataset and methodology. We propose GEM, a gated ensemble of emotion-specialized models with a speech emotion recognition gating network. GEM performs effectively across all emotions and neutral state, improving defenses against spoofing attacks. We release the EmoSpoof-TTS Dataset: https://emospoof-tts.github.io/Dataset/
EmotionRankCLAP: Bridging Natural Language Speaking Styles and Ordinal Speech Emotion via Rank-N-Contrast
May 29, 2025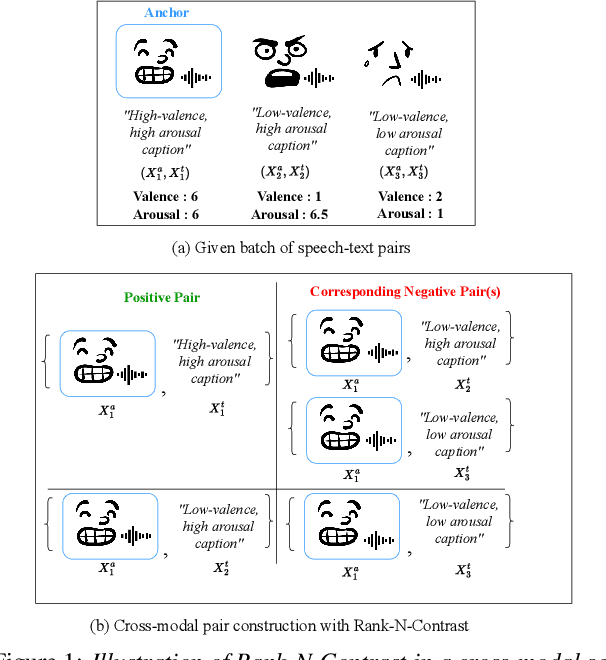


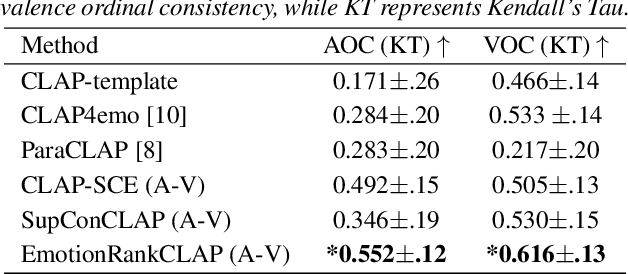
Current emotion-based contrastive language-audio pretraining (CLAP) methods typically learn by na\"ively aligning audio samples with corresponding text prompts. Consequently, this approach fails to capture the ordinal nature of emotions, hindering inter-emotion understanding and often resulting in a wide modality gap between the audio and text embeddings due to insufficient alignment. To handle these drawbacks, we introduce EmotionRankCLAP, a supervised contrastive learning approach that uses dimensional attributes of emotional speech and natural language prompts to jointly capture fine-grained emotion variations and improve cross-modal alignment. Our approach utilizes a Rank-N-Contrast objective to learn ordered relationships by contrasting samples based on their rankings in the valence-arousal space. EmotionRankCLAP outperforms existing emotion-CLAP methods in modeling emotion ordinality across modalities, measured via a cross-modal retrieval task.
Towards Emotionally Consistent Text-Based Speech Editing: Introducing EmoCorrector and The ECD-TSE Dataset
May 24, 2025



Text-based speech editing (TSE) modifies speech using only text, eliminating re-recording. However, existing TSE methods, mainly focus on the content accuracy and acoustic consistency of synthetic speech segments, and often overlook the emotional shifts or inconsistency issues introduced by text changes. To address this issue, we propose EmoCorrector, a novel post-correction scheme for TSE. EmoCorrector leverages Retrieval-Augmented Generation (RAG) by extracting the edited text's emotional features, retrieving speech samples with matching emotions, and synthesizing speech that aligns with the desired emotion while preserving the speaker's identity and quality. To support the training and evaluation of emotional consistency modeling in TSE, we pioneer the benchmarking Emotion Correction Dataset for TSE (ECD-TSE). The prominent aspect of ECD-TSE is its inclusion of $<$text, speech$>$ paired data featuring diverse text variations and a range of emotional expressions. Subjective and objective experiments and comprehensive analysis on ECD-TSE confirm that EmoCorrector significantly enhances the expression of intended emotion while addressing emotion inconsistency limitations in current TSE methods. Code and audio examples are available at https://github.com/AI-S2-Lab/EmoCorrector.
DART: Disentanglement of Accent and Speaker Representation in Multispeaker Text-to-Speech
Oct 17, 2024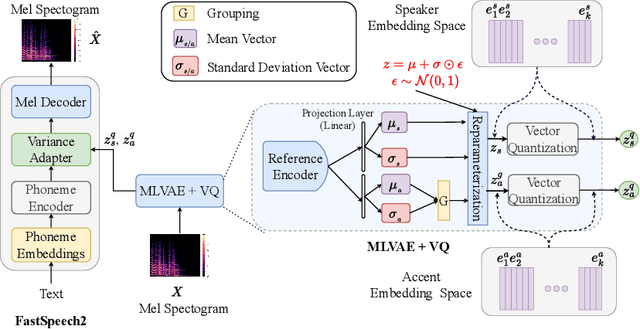
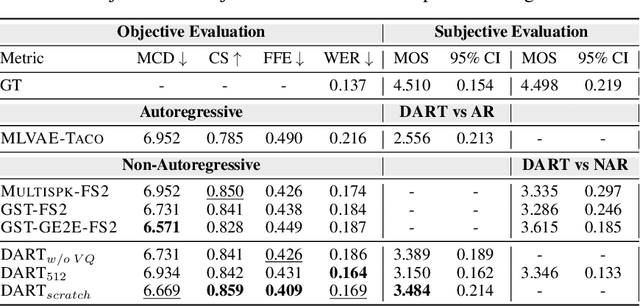
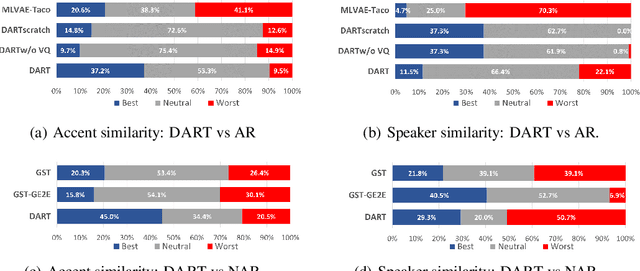
Recent advancements in Text-to-Speech (TTS) systems have enabled the generation of natural and expressive speech from textual input. Accented TTS aims to enhance user experience by making the synthesized speech more relatable to minority group listeners, and useful across various applications and context. Speech synthesis can further be made more flexible by allowing users to choose any combination of speaker identity and accent, resulting in a wide range of personalized speech outputs. Current models struggle to disentangle speaker and accent representation, making it difficult to accurately imitate different accents while maintaining the same speaker characteristics. We propose a novel approach to disentangle speaker and accent representations using multi-level variational autoencoders (ML-VAE) and vector quantization (VQ) to improve flexibility and enhance personalization in speech synthesis. Our proposed method addresses the challenge of effectively separating speaker and accent characteristics, enabling more fine-grained control over the synthesized speech. Code and speech samples are publicly available.
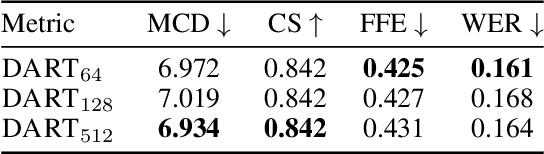
Discrete Unit based Masking for Improving Disentanglement in Voice Conversion
Sep 17, 2024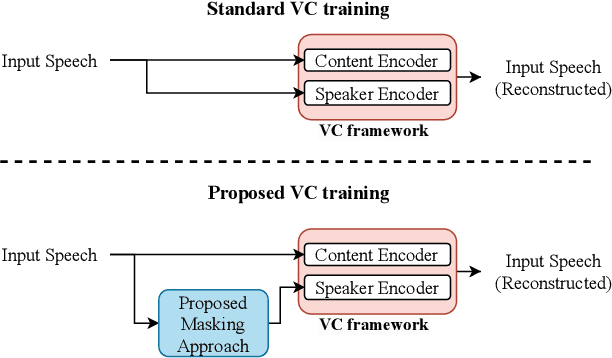

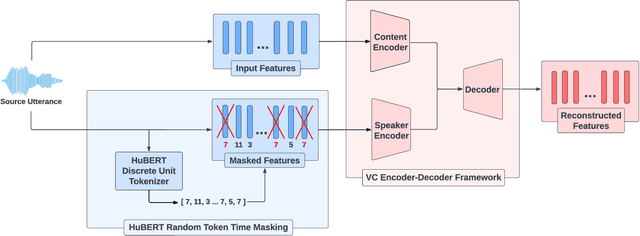

Voice conversion (VC) aims to modify the speaker's identity while preserving the linguistic content. Commonly, VC methods use an encoder-decoder architecture, where disentangling the speaker's identity from linguistic information is crucial. However, the disentanglement approaches used in these methods are limited as the speaker features depend on the phonetic content of the utterance, compromising disentanglement. This dependency is amplified with attention-based methods. To address this, we introduce a novel masking mechanism in the input before speaker encoding, masking certain discrete speech units that correspond highly with phoneme classes. Our work aims to reduce the phonetic dependency of speaker features by restricting access to some phonetic information. Furthermore, since our approach is at the input level, it is applicable to any encoder-decoder based VC framework. Our approach improves disentanglement and conversion performance across multiple VC methods, showing significant effectiveness, particularly in attention-based method, with 44% relative improvement in objective intelligibility.
SelectTTS: Synthesizing Anyone's Voice via Discrete Unit-Based Frame Selection
Aug 30, 2024



Synthesizing the voices of unseen speakers is a persisting challenge in multi-speaker text-to-speech (TTS). Most multi-speaker TTS models rely on modeling speaker characteristics through speaker conditioning during training. Modeling unseen speaker attributes through this approach has necessitated an increase in model complexity, which makes it challenging to reproduce results and improve upon them. We design a simple alternative to this. We propose SelectTTS, a novel method to select the appropriate frames from the target speaker and decode using frame-level self-supervised learning (SSL) features. We show that this approach can effectively capture speaker characteristics for unseen speakers, and achieves comparable results to other multi-speaker TTS frameworks in both objective and subjective metrics. With SelectTTS, we show that frame selection from the target speaker's speech is a direct way to achieve generalization in unseen speakers with low model complexity. We achieve better speaker similarity performance than SOTA baselines XTTS-v2 and VALL-E with over an 8x reduction in model parameters and a 270x reduction in training data
PRESENT: Zero-Shot Text-to-Prosody Control
Aug 13, 2024Current strategies for achieving fine-grained prosody control in speech synthesis entail extracting additional style embeddings or adopting more complex architectures. To enable zero-shot application of pretrained text-to-speech (TTS) models, we present PRESENT (PRosody Editing without Style Embeddings or New Training), which exploits explicit prosody prediction in FastSpeech2-based models by modifying the inference process directly. We apply our text-to-prosody framework to zero-shot language transfer using a JETS model exclusively trained on English LJSpeech data. We obtain character error rates (CER) of 12.8%, 18.7% and 5.9% for German, Hungarian and Spanish respectively, beating the previous state-of-the-art CER by over 2x for all three languages. Furthermore, we allow subphoneme-level control, a first in this field. To evaluate its effectiveness, we show that PRESENT can improve the prosody of questions, and use it to generate Mandarin, a tonal language where vowel pitch varies at subphoneme level. We attain 25.3% hanzi CER and 13.0% pinyin CER with the JETS model. All our code and audio samples are available online.
We Need Variations in Speech Synthesis: Sub-center Modelling for Speaker Embeddings
Jul 05, 2024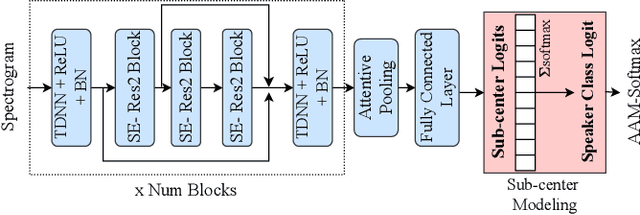
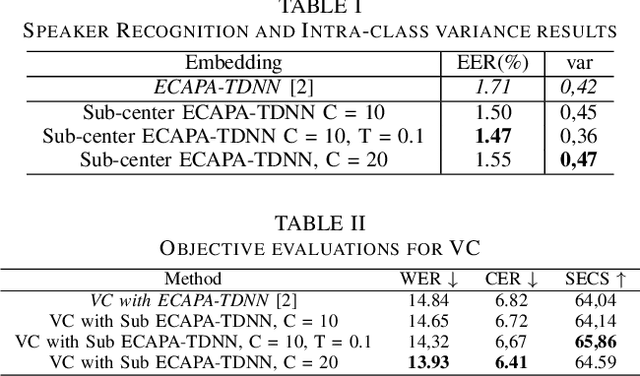
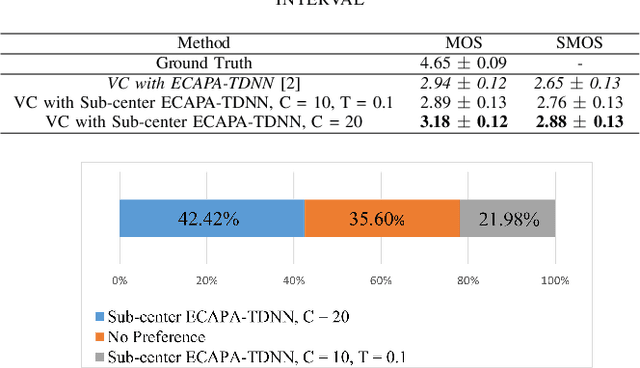
In speech synthesis, modeling of rich emotions and prosodic variations present in human voice are crucial to synthesize natural speech. Although speaker embeddings have been widely used in personalized speech synthesis as conditioning inputs, they are designed to lose variation to optimize speaker recognition accuracy. Thus, they are suboptimal for speech synthesis in terms of modeling the rich variations at the output speech distribution. In this work, we propose a novel speaker embedding network which utilizes multiple class centers in the speaker classification training rather than a single class center as traditional embeddings. The proposed approach introduces variations in the speaker embedding while retaining the speaker recognition performance since model does not have to map all of the utterances of a speaker into a single class center. We apply our proposed embedding in voice conversion task and show that our method provides better naturalness and prosody in synthesized speech.