 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Semantic Cloaking for Jailbreak Attacks on Large Language Models
Mar 17, 2026Modern LLMs employ safety mechanisms that extend beyond surface-level input filtering to latent semantic representations and generation-time reasoning, enabling them to recover obfuscated malicious intent during inference and refuse accordingly, and rendering many surface-level obfuscation jailbreak attacks ineffective. We propose Structured Semantic Cloaking (S2C), a novel multi-dimensional jailbreak attack framework that manipulates how malicious semantic intent is reconstructed during model inference. S2C strategically distributes and reshapes semantic cues such that full intent consolidation requires multi-step inference and long-range co-reference resolution within deeper latent representations. The framework comprises three complementary mechanisms: (1) Contextual Reframing, which embeds the request within a plausible high-stakes scenario to bias the model toward compliance; (2) Content Fragmentation, which disperses the semantic signature of the request across disjoint prompt segments; and (3) Clue-Guided Camouflage, which disguises residual semantic cues while embedding recoverable markers that guide output generation. By delaying and restructuring semantic consolidation, S2C degrades safety triggers that depend on coherent or explicitly reconstructed malicious intent at decoding time, while preserving sufficient instruction recoverability for functional output generation. We evaluate S2C across multiple open-source and proprietary LLMs using HarmBench and JBB-Behaviors, where it improves Attack Success Rate (ASR) by 12.4% and 9.7%, respectively, over the current SOTA. Notably, S2C achieves substantial gains on GPT-5-mini, outperforming the strongest baseline by 26% on JBB-Behaviors. We also analyse which combinations perform best against broad families of models, and characterise the trade-off between the extent of obfuscation versus input recoverability on jailbreak success.
PRESENT: Zero-Shot Text-to-Prosody Control
Aug 13, 2024Current strategies for achieving fine-grained prosody control in speech synthesis entail extracting additional style embeddings or adopting more complex architectures. To enable zero-shot application of pretrained text-to-speech (TTS) models, we present PRESENT (PRosody Editing without Style Embeddings or New Training), which exploits explicit prosody prediction in FastSpeech2-based models by modifying the inference process directly. We apply our text-to-prosody framework to zero-shot language transfer using a JETS model exclusively trained on English LJSpeech data. We obtain character error rates (CER) of 12.8%, 18.7% and 5.9% for German, Hungarian and Spanish respectively, beating the previous state-of-the-art CER by over 2x for all three languages. Furthermore, we allow subphoneme-level control, a first in this field. To evaluate its effectiveness, we show that PRESENT can improve the prosody of questions, and use it to generate Mandarin, a tonal language where vowel pitch varies at subphoneme level. We attain 25.3% hanzi CER and 13.0% pinyin CER with the JETS model. All our code and audio samples are available online.
SNIPER Training: Variable Sparsity Rate Training For Text-To-Speech
Nov 14, 2022



Text-to-speech (TTS) models have achieved remarkable naturalness in recent years, yet like most deep neural models, they have more parameters than necessary. Sparse TTS models can improve on dense models via pruning and extra retraining, or converge faster than dense models with some performance loss. Inspired by these results, we propose training TTS models using a decaying sparsity rate, i.e. a high initial sparsity to accelerate training first, followed by a progressive rate reduction to obtain better eventual performance. This decremental approach differs from current methods of incrementing sparsity to a desired target, which costs significantly more time than dense training. We call our method SNIPER training: Single-shot Initialization Pruning Evolving-Rate training. Our experiments on FastSpeech2 show that although we were only able to obtain better losses in the first few epochs before being overtaken by the baseline, the final SNIPER-trained models beat constant-sparsity models and pip dense models in performance.
EPIC TTS Models: Empirical Pruning Investigations Characterizing Text-To-Speech Models
Sep 22, 2022
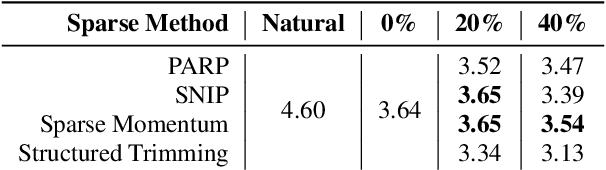
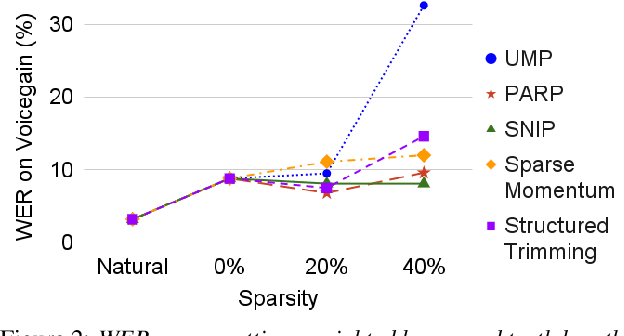
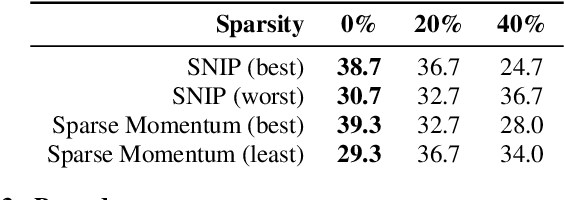
Neural models are known to be over-parameterized, and recent work has shown that sparse text-to-speech (TTS) models can outperform dense models. Although a plethora of sparse methods has been proposed for other domains, such methods have rarely been applied in TTS. In this work, we seek to answer the question: what are the characteristics of selected sparse techniques on the performance and model complexity? We compare a Tacotron2 baseline and the results of applying five techniques. We then evaluate the performance via the factors of naturalness, intelligibility and prosody, while reporting model size and training time. Complementary to prior research, we find that pruning before or during training can achieve similar performance to pruning after training and can be trained much faster, while removing entire neurons degrades performance much more than removing parameters. To our best knowledge, this is the first work that compares sparsity paradigms in text-to-speech synthesis.