 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Lifelong Learning in the Age of AI: Trends and Insights
Feb 03, 2026Rapid innovations in AI and large language models (LLMs) have accelerated the adoption of digital learning, particularly beyond formal education. What began as an emergency response during COVID-19 has shifted from a supplementary resource to an essential pillar of education. Understanding how digital learning continues to evolve for adult and lifelong learners is therefore increasingly important. This study examines how various demographics interact with digital learning platforms, focusing on the learner motivations, the effectiveness of gamification in digital learning, and the integration of AI. Using multi survey data from 200 respondents and advanced analytics, our findings reveal a notable increase in the perceived relevance of digital learning after the pandemic, especially among young adults and women, coinciding with the rise of LLM-powered AI tools that support personalized learning. We aim to provide actionable insights for businesses, government policymakers, and educators seeking to optimize their digital learning offerings to meet evolving workforce needs.
Aligning Generative Music AI with Human Preferences: Methods and Challenges
Nov 19, 2025Recent advances in generative AI for music have achieved remarkable fidelity and stylistic diversity, yet these systems often fail to align with nuanced human preferences due to the specific loss functions they use. This paper advocates for the systematic application of preference alignment techniques to music generation, addressing the fundamental gap between computational optimization and human musical appreciation. Drawing on recent breakthroughs including MusicRL's large-scale preference learning, multi-preference alignment frameworks like diffusion-based preference optimization in DiffRhythm+, and inference-time optimization techniques like Text2midi-InferAlign, we discuss how these techniques can address music's unique challenges: temporal coherence, harmonic consistency, and subjective quality assessment. We identify key research challenges including scalability to long-form compositions, reliability amongst others in preference modelling. Looking forward, we envision preference-aligned music generation enabling transformative applications in interactive composition tools and personalized music services. This work calls for sustained interdisciplinary research combining advances in machine learning, music-theory to create music AI systems that truly serve human creative and experiential needs.
NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
Nov 18, 2025



Vision--language--action (VLA) models have recently shown promising performance on a variety of embodied tasks, yet they still fall short in reliability and generalization, especially when deployed across different embodiments or real-world environments. In this work, we introduce NORA-1.5, a VLA model built from the pre-trained NORA backbone by adding to it a flow-matching-based action expert. This architectural enhancement alone yields substantial performance gains, enabling NORA-1.5 to outperform NORA and several state-of-the-art VLA models across both simulated and real-world benchmarks. To further improve robustness and task success, we develop a set of reward models for post-training VLA policies. Our rewards combine (i) an action-conditioned world model (WM) that evaluates whether generated actions lead toward the desired goal, and (ii) a deviation-from-ground-truth heuristic that distinguishes good actions from poor ones. Using these reward signals, we construct preference datasets and adapt NORA-1.5 to target embodiments through direct preference optimization (DPO). Extensive evaluations show that reward-driven post-training consistently improves performance in both simulation and real-robot settings, demonstrating significant VLA model-reliability gains through simple yet effective reward models. Our findings highlight NORA-1.5 and reward-guided post-training as a viable path toward more dependable embodied agents suitable for real-world deployment.
HHNAS-AM: Hierarchical Hybrid Neural Architecture Search using Adaptive Mutation Policies
Aug 20, 2025Neural Architecture Search (NAS) has garnered significant research interest due to its capability to discover architectures superior to manually designed ones. Learning text representation is crucial for text classification and other language-related tasks. The NAS model used in text classification does not have a Hybrid hierarchical structure, and there is no restriction on the architecture structure, due to which the search space becomes very large and mostly redundant, so the existing RL models are not able to navigate the search space effectively. Also, doing a flat architecture search leads to an unorganised search space, which is difficult to traverse. For this purpose, we propose HHNAS-AM (Hierarchical Hybrid Neural Architecture Search with Adaptive Mutation Policies), a novel approach that efficiently explores diverse architectural configurations. We introduce a few architectural templates to search on which organise the search spaces, where search spaces are designed on the basis of domain-specific cues. Our method employs mutation strategies that dynamically adapt based on performance feedback from previous iterations using Q-learning, enabling a more effective and accelerated traversal of the search space. The proposed model is fully probabilistic, enabling effective exploration of the search space. We evaluate our approach on the database id (db_id) prediction task, where it consistently discovers high-performing architectures across multiple experiments. On the Spider dataset, our method achieves an 8% improvement in test accuracy over existing baselines.
JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Jul 28, 2025



Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.
SonicVerse: Multi-Task Learning for Music Feature-Informed Captioning
Jun 18, 2025Detailed captions that accurately reflect the characteristics of a music piece can enrich music databases and drive forward research in music AI. This paper introduces a multi-task music captioning model, SonicVerse, that integrates caption generation with auxiliary music feature detection tasks such as key detection, vocals detection, and more, so as to directly capture both low-level acoustic details as well as high-level musical attributes. The key contribution is a projection-based architecture that transforms audio input into language tokens, while simultaneously detecting music features through dedicated auxiliary heads. The outputs of these heads are also projected into language tokens, to enhance the captioning input. This framework not only produces rich, descriptive captions for short music fragments but also directly enables the generation of detailed time-informed descriptions for longer music pieces, by chaining the outputs using a large-language model. To train the model, we extended the MusicBench dataset by annotating it with music features using MIRFLEX, a modular music feature extractor, resulting in paired audio, captions and music feature data. Experimental results show that incorporating features in this way improves the quality and detail of the generated captions.
* 14 pages, 2 figures, Accepted to AIMC 2025
MelodySim: Measuring Melody-aware Music Similarity for Plagiarism Detection
May 27, 2025We propose MelodySim, a melody-aware music similarity model and dataset for plagiarism detection. First, we introduce a novel method to construct a dataset with focus on melodic similarity. By augmenting Slakh2100; an existing MIDI dataset, we generate variations of each piece while preserving the melody through modifications such as note splitting, arpeggiation, minor track dropout (excluding bass), and re-instrumentation. A user study confirms that positive pairs indeed contain similar melodies, with other musical tracks significantly changed. Second, we develop a segment-wise melodic-similarity detection model that uses a MERT encoder and applies a triplet neural network to capture melodic similarity. The resultant decision matrix highlights where plagiarism might occur. Our model achieves high accuracy on the MelodySim test set.
Text2midi-InferAlign: Improving Symbolic Music Generation with Inference-Time Alignment
May 19, 2025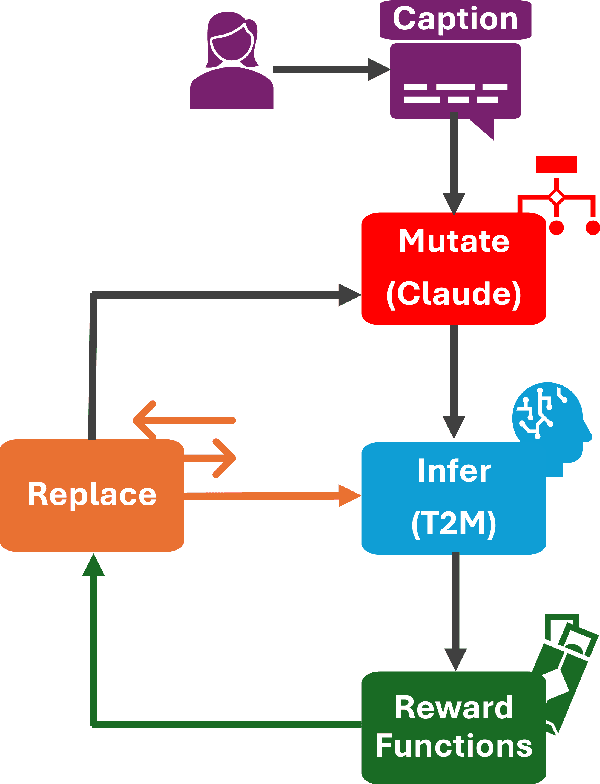
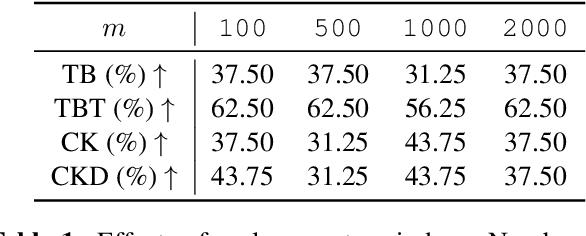
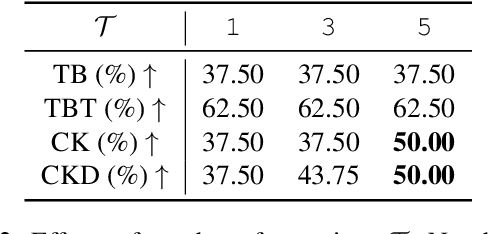
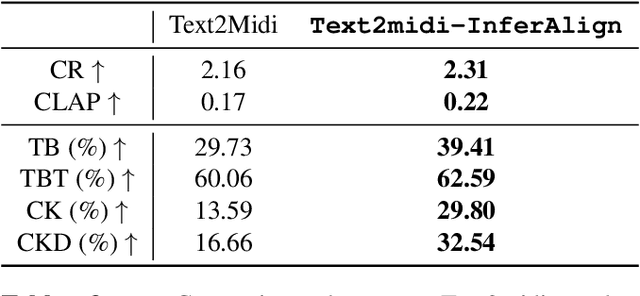
We present Text2midi-InferAlign, a novel technique for improving symbolic music generation at inference time. Our method leverages text-to-audio alignment and music structural alignment rewards during inference to encourage the generated music to be consistent with the input caption. Specifically, we introduce two objectives scores: a text-audio consistency score that measures rhythmic alignment between the generated music and the original text caption, and a harmonic consistency score that penalizes generated music containing notes inconsistent with the key. By optimizing these alignment-based objectives during the generation process, our model produces symbolic music that is more closely tied to the input captions, thereby improving the overall quality and coherence of the generated compositions. Our approach can extend any existing autoregressive model without requiring further training or fine-tuning. We evaluate our work on top of Text2midi - an existing text-to-midi generation model, demonstrating significant improvements in both objective and subjective evaluation metrics.
JamendoMaxCaps: A Large Scale Music-caption Dataset with Imputed Metadata
Feb 11, 2025We introduce JamendoMaxCaps, a large-scale music-caption dataset featuring over 200,000 freely licensed instrumental tracks from the renowned Jamendo platform. The dataset includes captions generated by a state-of-the-art captioning model, enhanced with imputed metadata. We also introduce a retrieval system that leverages both musical features and metadata to identify similar songs, which are then used to fill in missing metadata using a local large language model (LLLM). This approach allows us to provide a more comprehensive and informative dataset for researchers working on music-language understanding tasks. We validate this approach quantitatively with five different measurements. By making the JamendoMaxCaps dataset publicly available, we provide a high-quality resource to advance research in music-language understanding tasks such as music retrieval, multimodal representation learning, and generative music models.
Towards Unified Music Emotion Recognition across Dimensional and Categorical Models
Feb 06, 2025One of the most significant challenges in Music Emotion Recognition (MER) comes from the fact that emotion labels can be heterogeneous across datasets with regard to the emotion representation, including categorical (e.g., happy, sad) versus dimensional labels (e.g., valence-arousal). In this paper, we present a unified multitask learning framework that combines these two types of labels and is thus able to be trained on multiple datasets. This framework uses an effective input representation that combines musical features (i.e., key and chords) and MERT embeddings. Moreover, knowledge distillation is employed to transfer the knowledge of teacher models trained on individual datasets to a student model, enhancing its ability to generalize across multiple tasks. To validate our proposed framework, we conducted extensive experiments on a variety of datasets, including MTG-Jamendo, DEAM, PMEmo, and EmoMusic. According to our experimental results, the inclusion of musical features, multitask learning, and knowledge distillation significantly enhances performance. In particular, our model outperforms the state-of-the-art models, including the best-performing model from the MediaEval 2021 competition on the MTG-Jamendo dataset. Our work makes a significant contribution to MER by allowing the combination of categorical and dimensional emotion labels in one unified framework, thus enabling training across datasets.